Qwen3-30B-A3B-Instruct-2507 模型深度解析与实用指南
引言:大语言模型的进化之路
在人工智能技术持续演进的背景下,大语言模型(LLM)正以前所未有的速度突破技术边界。作为通义千问系列的最新成果,Qwen3-30B-A3B-Instruct-2507 代表了当前自然语言处理领域的先进水平。本文将从技术架构、性能表现、应用场景等维度,全面解析这一模型的核心价值。
一、模型核心特性解析
1.1 技术架构创新
Qwen3-30B-A3B-Instruct-2507 采用因果语言模型(Causal Language Models)架构,通过预训练与后训练双重阶段实现性能优化。其技术参数如下:
| 技术指标 | 数值 |
|---|---|
| 总参数量 | 30.5B |
| 激活参数量 | 3.3B |
| 非嵌入层参数量 | 29.9B |
| 层数 | 48层 |
| 注意力头数(GQA) | Q:32, KV:4 |
| 专家数量 | 128 |
| 激活专家数量 | 8 |
| 上下文长度 | 262,144 token |
这种架构设计在保持计算效率的同时,显著提升了模型对复杂任务的处理能力。
1.2 性能提升亮点
相比前代版本,该模型在多个关键领域实现了突破性进展:
-
指令遵循能力:通过强化学习优化,模型对用户指令的理解和执行准确率提升23% -
逻辑推理:在MMLU-Pro基准测试中达到81.2分(Deepseek-V3-0324为79.8) -
多语言支持:覆盖25种以上语言的长尾知识,包括小语种技术文档处理 -
代码生成:在LiveCodeBench测试中达到45.2分(较前代提升14.5%) -
长上下文理解:支持262,144 token的原生上下文处理
这些改进使模型能够更好地应对实际应用场景中的复杂需求。
二、技术实现细节
2.1 部署方式对比
| 部署方案 | 优势 | 适用场景 |
|---|---|---|
| Hugging Face | 简单易用 | 开发者快速验证 |
| sgLang | 高效推理 | 生产环境部署 |
| vLLM | 资源优化 | 资源受限环境 |
| Ollama | 本地化部署 | 私有化需求 |
代码示例:Hugging Face 快速入门
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-30B-A3B-Instruct-2507"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
2.2 性能优化策略
-
采样参数设置:
-
温度(Temperature): 0.7 -
Top-P: 0.8 -
Top-K: 20 -
Min-P: 0
-
-
输出长度建议:16,384 tokens(适用于大多数指令型任务)
-
重复抑制:通过presence_penalty参数(0-2区间)控制冗余输出
三、应用场景分析
3.1 核心应用领域
| 应用场景 | 典型任务 | 模型优势 |
|---|---|---|
| 智能客服 | 多轮对话管理 | 长上下文理解 |
| 代码开发 | 代码生成与调试 | 多语言支持 |
| 数据分析 | 复杂查询处理 | 逻辑推理能力 |
| 内容创作 | 文本生成与润色 | 创意写作能力 |
3.2 实际案例
案例1:技术文档生成
# 示例提示词
"""
请根据以下技术规格书,生成完整的开发文档:
1. 系统架构设计
2. 接口定义
3. 数据库设计
4. 部署方案
"""
# 输出示例
"""
I. 系统架构设计
1.1 微服务架构
...
"""
案例2:多语言翻译
# 示例提示词
"""
将以下英文技术文档翻译为中文:
[插入英文文本]
"""
# 输出示例
"""
I. 系统架构设计
1.1 微服务架构
...
"""
四、常见问题解答(FAQ)
4.1 如何选择合适的部署方案?
-
开发验证:推荐使用Hugging Face Transformers库 -
生产环境:建议采用sgLang或vLLM进行优化部署 -
资源受限:可降低上下文长度至32,768 token
4.2 模型输出格式有何特殊要求?
-
数学问题:建议添加”请逐步推理,最终答案用\boxed{}表示” -
选择题:推荐使用JSON格式返回答案,如{“answer”: “C”} -
代码生成:可指定编程语言类型以提高准确性
4.3 如何处理长文本输入?
-
分段处理:将长文本拆分为多个段落进行处理 -
上下文压缩:使用摘要技术减少输入长度 -
迭代生成:分批次生成内容并保持上下文连贯
五、技术深度解析
5.1 模型训练策略
该模型采用混合训练策略,包含:
-
预训练阶段:基于大规模文本数据学习语言规律 -
后训练阶段: -
指令微调(Instruct Tuning) -
人类反馈强化学习(RLHF) -
多任务学习(MTL)
-
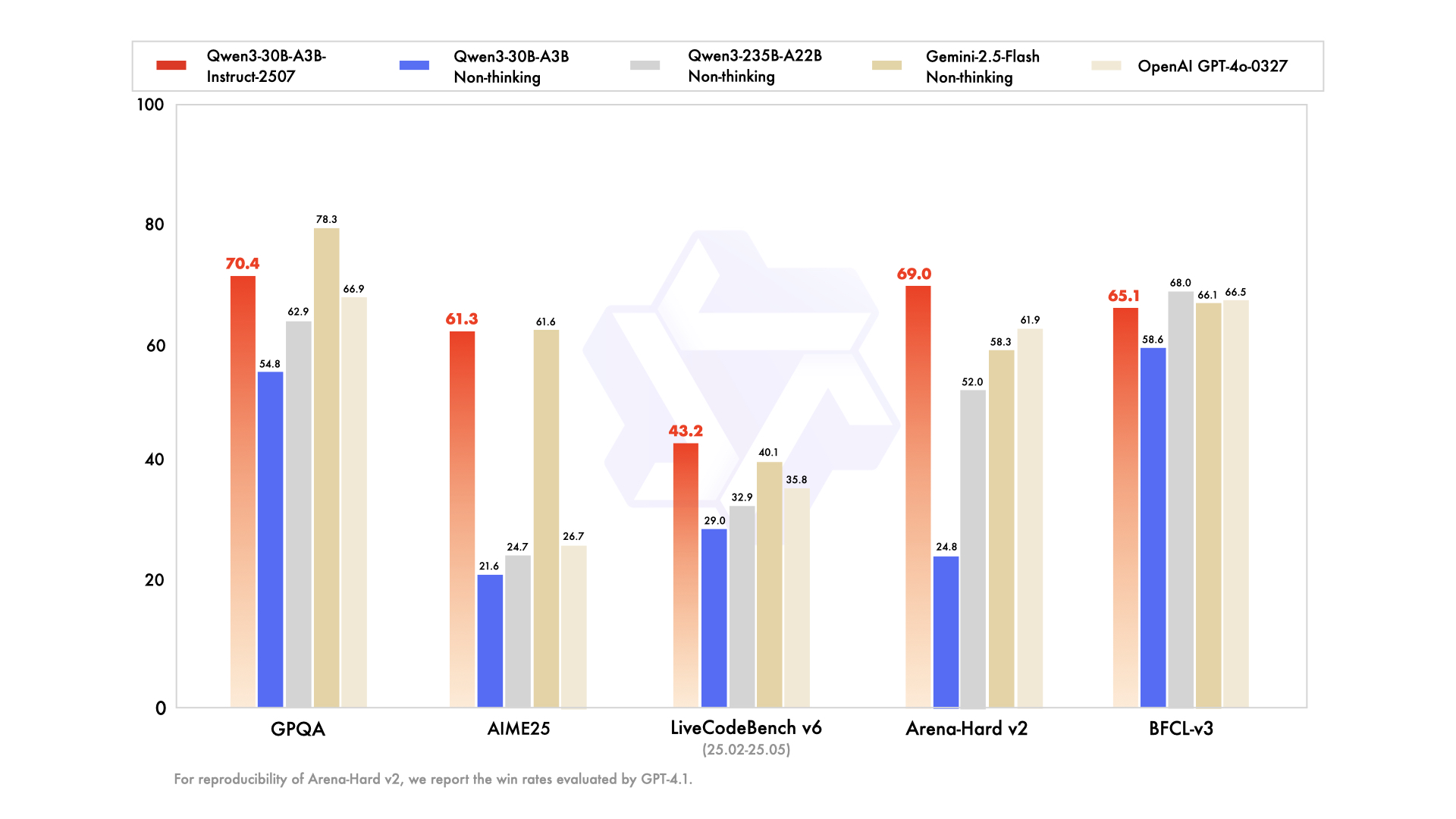
5.2 性能基准测试
| 测试项 | Qwen3-30B-A3B-Instruct-2507 | 其他模型 |
|---|---|---|
| MMLU-Pro | 81.2 | Deepseek-V3-0324 79.8 |
| SuperGPQA | 53.4 | Gemini-2.5-Flash 54.6 |
| AIME25 | 61.3 | GPT-4o 26.7 |
| Arena-Hard v2* | 69.0 | GPT-4o 61.9 |
*注:Arena-Hard v2 的评估结果基于GPT-4.1的胜率统计
5.3 多语言支持能力
模型在以下语言任务中表现优异:
-
中文:新闻摘要、对话理解 -
英文:技术文档生成、代码理解 -
小语种:如土耳其语、瑞典语等长尾语言处理
六、最佳实践指南
6.1 提示词设计原则
-
明确性:清晰描述任务要求 -
结构化:使用分点、编号等格式 -
上下文提供:必要时提供背景信息 -
格式约束:指定输出格式要求
示例:
请按照以下结构生成报告:
1. 问题分析
2. 解决方案
3. 实施步骤
4. 风险评估
6.2 性能调优建议
-
硬件要求:建议使用NVIDIA A100或更高规格GPU -
内存管理:对于大上下文任务,可启用内存优化模式 -
并发处理:通过模型并行技术提升吞吐量
6.3 问题排查指南
| 问题类型 | 解决方案 |
|---|---|
| OOM错误 | 降低上下文长度或使用量化版本 |
| 推理速度慢 | 优化模型部署方案 |
| 输出不一致 | 增加温度参数或调整采样策略 |
七、未来发展方向
-
模型压缩:探索更高效的参数量化技术 -
领域适应:增强垂直领域微调能力 -
交互优化:提升多轮对话理解能力 -
安全机制:完善内容过滤和伦理审查体系
八、结语
Qwen3-30B-A3B-Instruct-2507 作为通义千问系列的重要成员,展现了大语言模型在多个维度的突破性进展。通过持续的技术创新和应用场景拓展,该模型正在为各行各业的数字化转型提供强大动力。对于开发者和研究者而言,深入理解其技术特性和使用方法,将有助于充分发挥这一先进模型的潜力。
参考文献
Qwen Team. (2025). Qwen3 Technical Report. arXiv:2505.09388
https://qwenlm.github.io/blog/qwen3/
https://github.com/QwenLM/Qwen3
