EmbeddingGemma:重新定义设备端嵌入模型的高效与隐私

在人工智能快速发展的今天,如何在资源有限的设备上实现高效、低延迟的文本嵌入,同时保障用户数据的隐私性,成为开发者面临的重要挑战。Google最新推出的EmbeddingGemma模型,以其仅有的3.08亿参数,在多项基准测试中取得了领先的性能表现,为设备端AI应用提供了全新的解决方案。
模型概述:小巧而强大的设计理念
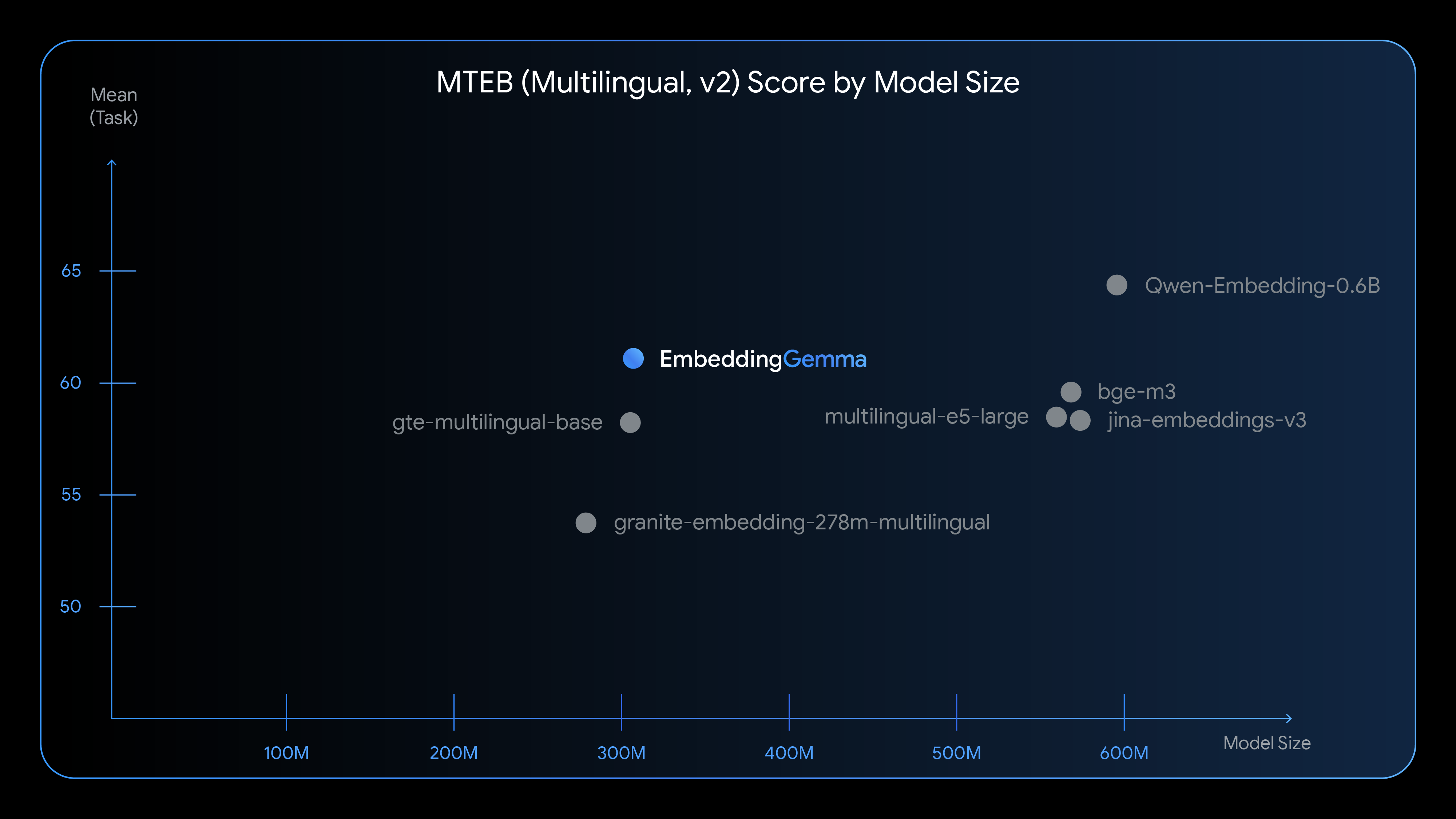
EmbeddingGemma是一个专为设备端AI设计的高效文本嵌入模型。尽管模型参数量仅为308M,却在多语言文本理解任务上表现出色,特别是在 Massive Text Embedding Benchmark (MTEB) 测试中,它在500M参数以下的模型中排名第一。
核心特性包括:
-
支持100多种语言的文本嵌入 -
基于Gemma 3架构的编码器主干网络 -
使用平均池化生成固定长度的向量表示 -
产生768维的嵌入向量,支持最长2048个令牌的输入序列 -
采用Matryoshka表示学习,支持嵌入维度从768到128的灵活调整
技术架构:平衡效率与性能的创新设计
编码器架构
EmbeddingGemma基于Gemma 3编码器架构构建,但针对文本嵌入任务进行了专门优化。与Gemma 3处理多模态输入时使用的双向注意力层不同,EmbeddingGemma采用了标准的Transformer编码器堆栈和全序列自注意力机制,这是文本嵌入模型的典型设计选择。
这种设计选择使得模型在保持高性能的同时,大幅降低了计算复杂度和内存需求。编码器生成的768维嵌入能够有效地捕捉文本的语义信息,适用于检索增强生成(RAG)和长文档搜索等多种应用场景。
Matryoshka表示学习
EmbeddingGemma引入了Matryoshka表示学习(MRL)技术,这是其最突出的创新之一。MRL允许开发者将768维的嵌入向量截断为512、256或128维,而不会显著影响模型性能。
这种灵活性带来的实际好处包括:
-
根据存储限制调整嵌入维度 -
在精度和检索速度之间找到最佳平衡 -
无需重新训练模型即可适应不同的应用需求 -
显著减少嵌入索引的存储空间需求
性能表现:超越尺寸限制的卓越能力
EmbeddingGemma在多个权威基准测试中展现了令人印象深刻的性能。在MTEB多语言测试中,该模型在不同维度设置下都保持了稳定的表现:
| 维度 | 平均任务得分 | 平均任务类型得分 |
|---|---|---|
| 768d | 61.15 | 54.31 |
| 512d | 60.71 | 53.89 |
| 256d | 59.68 | 53.01 |
| 128d | 58.23 | 51.77 |
在英语特定的MTEB测试中,模型表现更加出色:
| 维度 | 平均任务得分 | 平均任务类型得分 |
|---|---|---|
| 768d | 68.36 | 64.15 |
| 512d | 67.80 | 63.59 |
| 256d | 66.89 | 62.94 |
| 128d | 65.09 | 61.56 |
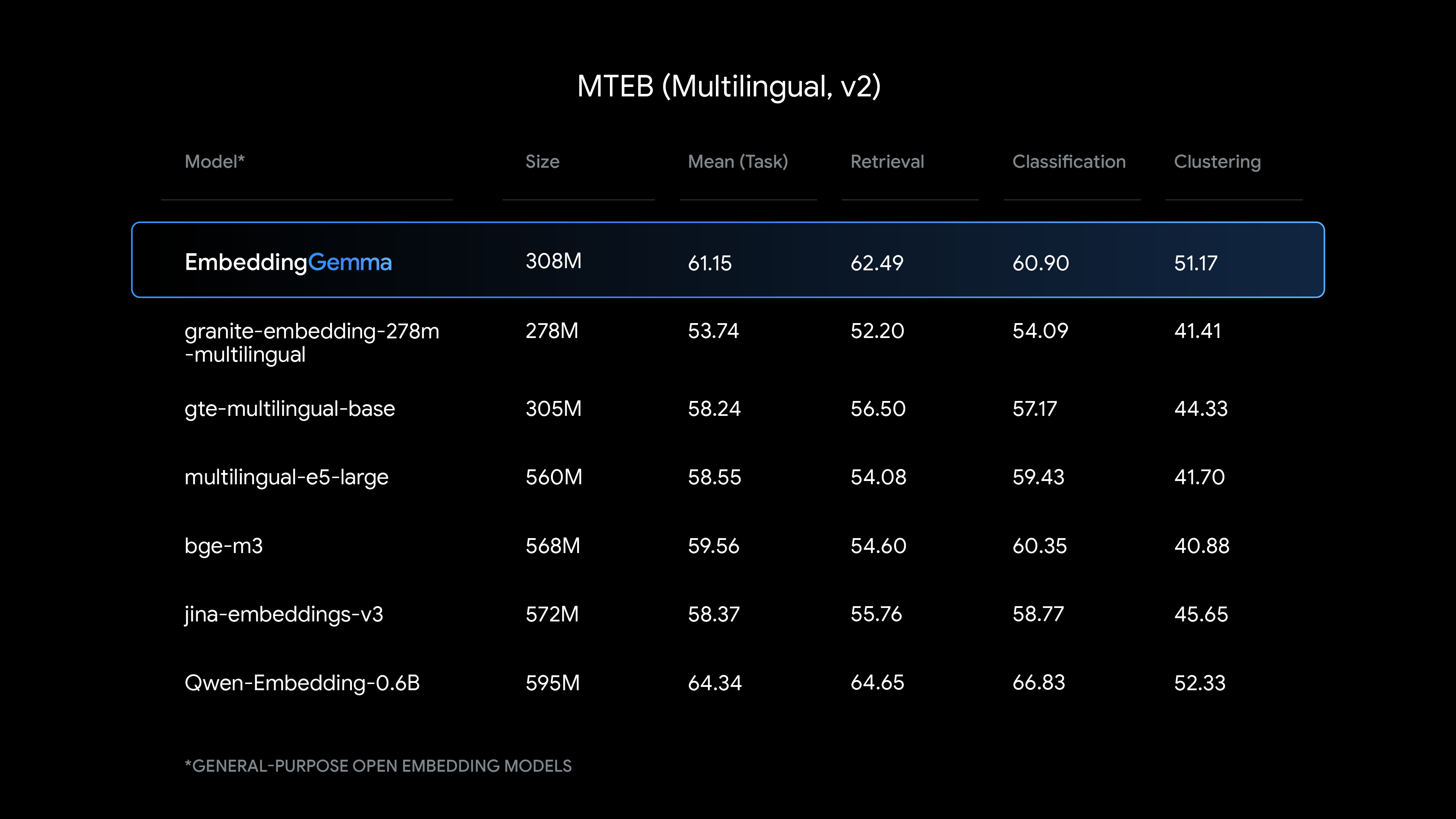
个人反思:在评估这些性能数据时,我注意到EmbeddingGemma在参数效率方面取得了显著突破。通常情况下,模型性能与参数数量呈正相关,但EmbeddingGemma通过精巧的架构设计和训练策略,成功打破了这一传统认知,为设备端AI模型的发展指明了新方向。
设备端部署:隐私与效率的双重优势
离线运行能力
EmbeddingGemma专门为设备端离线使用设计,这意味着敏感数据无需离开用户设备即可完成处理。这种设计为医疗、金融和法律等对数据隐私要求极高的行业提供了理想的解决方案。
离线部署的优势包括:
-
用户数据始终保留在本地设备 -
不依赖网络连接,实时响应 -
减少云服务成本和数据传输延迟 -
符合严格的数据保护法规要求
资源优化与量化支持
模型经过量化感知训练(QAT)优化,在保持质量的同时显著减少内存使用。量化后的模型只需不到200MB的RAM即可运行,使其能够在手机、笔记本电脑和台式机等日常设备上流畅运行。
量化配置性能对比:
| 量化配置 | 多语言平均任务得分 | 英语平均任务得分 |
|---|---|---|
| Q4_0 (768d) | 60.62 | 67.91 |
| Q8_0 (768d) | 60.93 | 68.13 |
| 混合精度 (768d) | 60.69 | 67.95 |
实际应用:从代码实现到完整解决方案
快速开始使用
EmbeddingGemma与主流开发框架无缝集成,开发者可以轻松地将其引入现有项目。
安装和基础使用:
pip install -U sentence-transformers
from sentence_transformers import SentenceTransformer
# 从Hugging Face Hub下载模型
model = SentenceTransformer("google/embeddinggemma-300m")
# 对查询和文档进行推理
query = "Which planet is known as the Red Planet?"
documents = [
"Venus is often called Earth's twin because of its similar size and proximity.",
"Mars, known for its reddish appearance, is often referred to as the Red Planet.",
"Jupiter, the largest planet in our solar system, has a prominent red spot.",
"Saturn, famous for its rings, is sometimes mistaken for the Red Planet."
]
query_embeddings = model.encode_query(query)
document_embeddings = model.encode_document(documents)
# 计算相似度以确定排名
similarities = model.similarity(query_embeddings, document_embeddings)
print(similarities)
# 输出: tensor([[0.3011, 0.6359, 0.4930, 0.4889]])
设备端RAG管道实现
EmbeddingGemma与Gemma 3n配合使用,可以构建完整的设备端检索增强生成管道。
RAG管道工作流程:
-
使用EmbeddingGemma生成用户查询的嵌入向量 -
计算查询嵌入与本地文档库中所有文档嵌入的相似度 -
检索与查询最相关的文档段落 -
将检索到的上下文与原始查询一起输入Gemma 3n生成模型 -
生成基于上下文的准确回答
个人反思:在实际实现RAG管道时,我深刻体会到嵌入质量对最终生成结果的关键影响。高质量的嵌入能够确保检索到最相关的上下文,从而显著提升生成答案的准确性和相关性。EmbeddingGemma在这方面表现出色,为设备端RAG应用提供了可靠的基础。
多语言支持与专业化应用
跨语言检索能力
EmbeddingGemma在100多种语言上进行训练,具备强大的跨语言检索能力。这意味着即使用户查询使用一种语言,模型也能从其他语言的文档中检索相关信息。
多语言应用场景:
-
跨国企业的多语言知识库检索 -
学术研究中的跨语言文献检索 -
旅游和教育应用中的多语言内容推荐
专业化提示模板
为了优化不同用例的嵌入质量,EmbeddingGemma支持使用特定的提示模板:
| 用例 | 推荐提示格式 |
|---|---|
| 检索(查询) | task: search result | query: {content} |
| 检索(文档) | title: title | text: {content} |
| 问答 | task: question answering | query: {content} |
| 事实核查 | task: fact checking | query: {content} |
| 分类 | task: classification | query: {content} |
生态系统集成:无缝接入现有工作流
EmbeddingGemma得到了广泛的开发生态系统支持,包括:
-
Hugging Face(transformers, Sentence-Transformers, transformers.js) -
LangChain 和 LlamaIndex 用于RAG管道 -
Weaviate 和其他向量数据库 -
ONNX Runtime 用于跨平台优化部署 -
llama.cpp, MLX, Ollama, LiteRT 等设备端推理框架
这种广泛的集成支持确保了开发者可以轻松地将EmbeddingGemma融入现有技术栈,无需大幅修改现有代码或工作流程。
适用场景与局限性
理想应用场景
EmbeddingGemma特别适用于以下场景:
-
移动设备应用:需要本地处理敏感数据的移动应用 -
边缘计算环境:网络连接不稳定或延迟敏感的环境 -
隐私敏感行业:医疗、金融、法律等对数据隐私要求极高的领域 -
实时应用:需要亚秒级响应时间的交互式应用 -
多语言环境:需要处理多种语言内容的全球化应用
当前局限性
尽管EmbeddingGemma表现出色,但仍存在一些局限性:
-
训练数据的质量和多样性会影响模型能力 -
可能难以捕捉语言的细微差别和讽刺表达 -
在某些高度专业化的领域可能需要进一步微调 -
模型规模限制了处理极复杂任务的能力
个人反思:认识到这些局限性并不是模型的缺点,而是帮助我们更好地理解其适用边界。在实际应用中,选择合适的模型不仅要考虑性能指标,还要综合考虑应用场景、资源约束和业务需求的多重因素。
实践指南:优化部署与性能调优
内存与速度优化
通过调整嵌入维度和量化配置,开发者可以在精度和效率之间找到最佳平衡:
from sentence_transformers import SentenceTransformer
# 加载模型
model = SentenceTransformer("google/embeddinggemma-300m")
# 生成完整768维嵌入(最高精度)
full_embeddings = model.encode(["example text"])
# 截断到512维(平衡精度和效率)
truncated_512 = full_embeddings[:, :512]
# 截断到256维(更高效率)
truncated_256 = full_embeddings[:, :256]
# 注意:EmbeddingGemma激活不支持float16,请使用float32或bfloat16
设备端优化策略
-
选择性量化:根据精度要求选择合适的量化级别 -
批量处理:合理设置批量大小以优化内存使用和速度 -
缓存策略:对静态内容预计算和缓存嵌入向量 -
维度调整:根据应用需求调整嵌入维度,权衡存储和精度
未来展望:设备端AI的新时代
EmbeddingGemma的发布标志着设备端AI能力的重要进步。随着模型优化技术的不断发展,我们预计将看到更多高性能、低功耗的AI模型能够在资源受限的环境中运行。
这种趋势对AI应用的未来发展具有重要意义:
-
降低AI应用的门槛,使更多开发者能够构建智能应用 -
增强用户隐私保护,推动负责任AI发展 -
实现真正的实时AI体验,无需网络延迟 -
促进AI技术在边缘设备上的普及和创新
实用摘要与操作清单
核心优势总结
-
高效性能:在紧凑模型中实现最佳的多语言检索精度 -
维度灵活:通过MRL支持可调整的嵌入维度 -
隐私保护:完整的端到端离线管道,无外部依赖 -
生态友好:开放权重、宽松许可和强大的生态系统支持
快速启动清单
-
安装Sentence Transformers库: pip install -U sentence-transformers -
加载模型: model = SentenceTransformer("google/embeddinggemma-300m") -
生成嵌入: embeddings = model.encode(["your text here"]) -
根据需求调整嵌入维度(768, 512, 256, 或128维) -
集成到现有RAG或检索管道中
一页速览(One-page Summary)
-
模型大小:308M参数 -
支持语言:100+种语言 -
嵌入维度:768维(可调整至512/256/128) -
上下文长度:2048个令牌 -
推理延迟:EdgeTPU上<15ms(256令牌) -
内存需求:量化后<200MB RAM -
主要特性:设备端优化、多语言支持、MRL灵活性 -
典型应用:移动RAG、语义搜索、文档检索、多语言分类
常见问题解答(FAQ)
EmbeddingGemma支持哪些编程语言?
EmbeddingGemma通过主流的AI开发框架提供支持,包括Python(SentenceTransformers、Transformers)、JavaScript(transformers.js)、以及C++(llama.cpp)等。开发者可以使用自己熟悉的编程语言进行集成。
模型是否需要互联网连接才能工作?
不需要。EmbeddingGemma专门设计为离线运行,所有计算都在本地设备上完成,不需要网络连接,这保证了数据隐私和实时响应。
如何在不同嵌入维度之间进行选择?
建议根据具体应用场景选择:使用768维获得最高精度,512维平衡精度和效率,256维或128维用于对存储和速度要求极高的场景。可以通过实验确定最适合的维度。
模型能否处理长文档?
是的,EmbeddingGemma支持最长2048个令牌的输入序列,能够处理大多数常见文档。对于极长文档,建议先进行分段处理。
是否支持自定义微调?
是的,EmbeddingGemma支持针对特定领域或任务进行微调。Google提供了详细的微调指南和示例代码,帮助开发者优化模型在特定应用中的表现。
量化对模型性能有多大影响?
量化会轻微影响模型性能,但通过量化感知训练(QAT)技术,这种影响被最小化。在实际应用中,量化版本的性能损失通常可以忽略不计,同时带来显著的内存和速度改善。
模型如何处理多语言输入?
EmbeddingGemma在100多种语言的训练数据上进行训练,能够自动识别和处理多种语言的文本输入,并生成高质量的跨语言语义表示。
是否支持商业使用?
是的,EmbeddingGemma采用开放权重和宽松的许可协议,允许商业使用。开发者可以在遵守相应条款的前提下,将模型集成到商业产品中。
