EmbeddingGemma: Revolutionizing On-Device Embeddings with Open-Source Excellence

Introduction: The New Standard for Efficient Text Embeddings
What makes an embedding model truly effective for on-device deployment? EmbeddingGemma answers this question by delivering best-in-class performance in a compact 308 million parameter package, specifically designed to run efficiently on consumer hardware without compromising capability.
In an era where privacy concerns and offline functionality are increasingly important, EmbeddingGemma represents a significant breakthrough. This open embedding model enables developers to build applications featuring Retrieval Augmented Generation (RAG) and semantic search that operate directly on devices, ensuring user data never leaves their hardware while maintaining state-of-the-art performance across 100+ languages.
Architectural Innovation: How EmbeddingGemma Achieves Efficiency Without Compromise
What technical architecture enables EmbeddingGemma’s exceptional performance-density ratio? The model builds upon the Gemma 3-based encoder backbone with mean pooling, but eliminates the multimodal-specific bidirectional attention layers used in the original Gemma 3 for image inputs, instead employing a standard transformer encoder stack with full-sequence self-attention specifically optimized for text embedding tasks.
The architecture consists of approximately 100 million model parameters and 200 million embedding parameters, carefully engineered to balance performance with minimal resource consumption. This design choice allows the model to maintain high-quality text understanding while reducing computational requirements significantly compared to larger models.
Author’s Reflection: Having worked with various embedding models, I find EmbeddingGemma’s architectural decisions particularly insightful. The focus on text-specific optimizations rather than trying to be everything to everyone demonstrates a sophisticated understanding of real-world deployment constraints. This specialized approach delivers tangible benefits in efficiency and performance that general-purpose models often sacrifice.
Performance Benchmarks: Setting New Standards for Compact Models
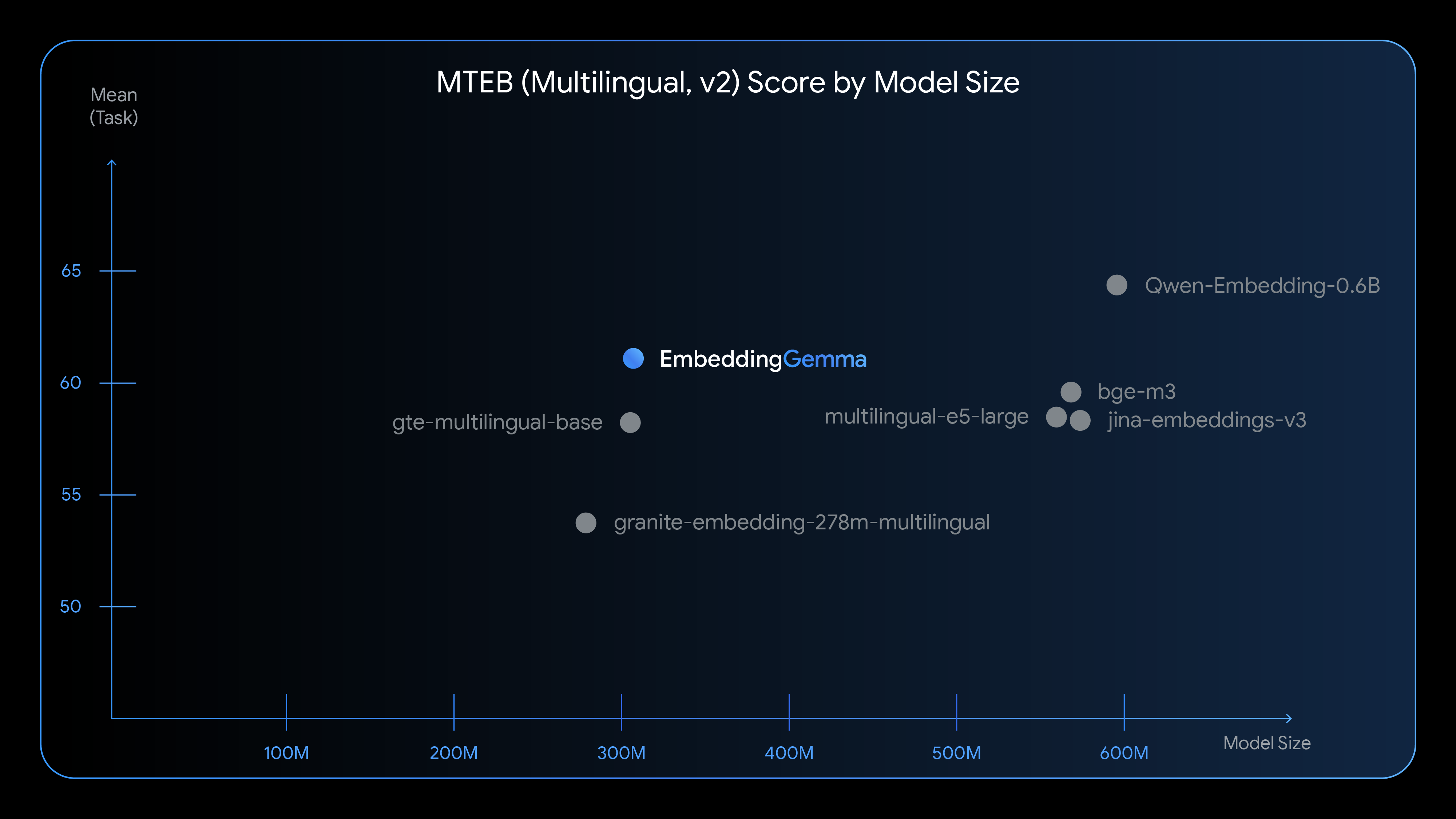
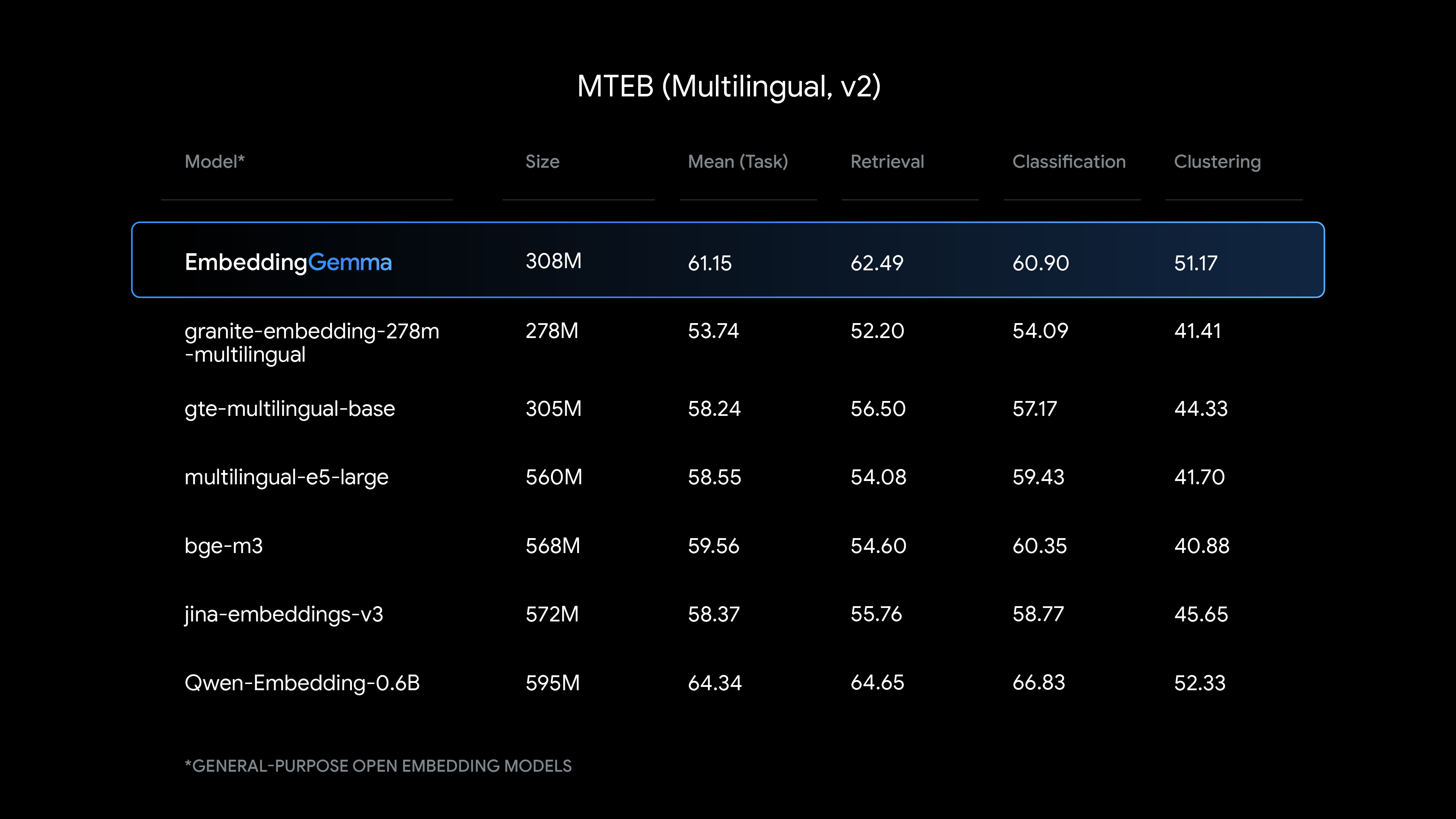
How does EmbeddingGemma compare to other embedding models in its class? The model achieves the highest ranking among open multilingual text embedding models under 500M parameters on the Massive Text Embedding Benchmark (MTEB), outperforming competitors nearly twice its size while maintaining significantly lower computational requirements.
The benchmark results demonstrate consistent performance across different embedding dimensions:
These results showcase how EmbeddingGemma maintains strong performance even when using reduced dimensionality, providing developers with flexibility in balancing accuracy against computational requirements.
Matryoshka Representation Learning: Flexible Embeddings for Diverse Needs
What makes EmbeddingGemma’s embeddings particularly adaptable to different application requirements? The implementation of Matryoshka Representation Learning (MRL) allows the model to generate multiple embedding sizes from a single trained model, enabling developers to dynamically adjust the trade-off between storage efficiency and retrieval precision without retraining.
This technical innovation means that instead of maintaining multiple models for different precision requirements, developers can use EmbeddingGemma and simply truncate the output embeddings to their desired dimensionality:
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("google/embeddinggemma-300m")
# Generate full 768-dimensional embeddings
full_embeddings = model.encode(["Your text here"])
# Truncate to 512 dimensions for balanced performance
truncated_512 = full_embeddings[:, :512]
# Use 256 dimensions for maximum efficiency
truncated_256 = full_embeddings[:, :256]
# Minimum footprint with 128 dimensions
truncated_128 = full_embeddings[:, :128]
This flexibility is particularly valuable for mobile applications where storage constraints might vary significantly across devices and use cases.
On-Device Deployment: Privacy and Performance Combined
How does EmbeddingGemma enable truly private AI applications? By running entirely on-device, the model ensures that sensitive user data never leaves their hardware, making it ideal for applications in healthcare, finance, legal, and other privacy-sensitive domains where data confidentiality is paramount.
The model’s efficiency metrics are impressive:
-
Sub-200MB RAM usage with quantization -
Less than 15ms embedding inference time for 256 input tokens on EdgeTPU -
Support for standard consumer hardware including mobile phones, laptops, and desktops -
Complete offline functionality with no internet connection required
Author’s Reflection: The privacy implications of on-device processing cannot be overstated. In my experience, many organizations want to implement AI features but hesitate due to data governance concerns. EmbeddingGemma effectively removes this barrier, enabling innovation while maintaining strict data protection standards that would be difficult to achieve with cloud-based solutions.
Practical Implementation: Building RAG Pipelines with EmbeddingGemma
How can developers implement a complete RAG pipeline using EmbeddingGemma? The model integrates seamlessly with popular tools and frameworks to create end-to-end solutions that retrieve relevant information and generate contextually appropriate responses entirely on-device.
A typical RAG implementation involves two key stages:
# Stage 1: Retrieve relevant context using EmbeddingGemma
from sentence_transformers import SentenceTransformer
import numpy as np
# Initialize the model
model = SentenceTransformer("google/embeddinggemma-300m")
# Sample document database (in practice, this would be pre-embedded)
documents = [
"Mars is the fourth planet from the Sun and is known as the Red Planet.",
"Venus is the second planet from the Sun and is Earth's closest planetary neighbor.",
"Jupiter is the largest planet in our solar system, with a prominent Great Red Spot.",
"Saturn is the sixth planet from the Sun and is famous for its spectacular ring system."
]
# Generate document embeddings (typically done offline)
doc_embeddings = model.encode(documents)
# User query
query = "Which planet is called the Red Planet?"
query_embedding = model.encode([query])
# Calculate similarities and find most relevant documents
similarities = np.dot(query_embedding, doc_embeddings.T)
most_relevant_idx = np.argmax(similarities)
retrieved_context = documents[most_relevant_idx]
# Stage 2: Generate answer using Gemma 3n with retrieved context
# (Implementation would depend on specific generative model integration)
This approach ensures that the retrieval step—critical for RAG accuracy—benefits from EmbeddingGemma’s high-quality embeddings while maintaining all processing on the user’s device.
Integration Ecosystem: Seamless Compatibility with Popular Tools
What development tools and frameworks support EmbeddingGemma? The model features extensive integration support across the machine learning ecosystem, enabling developers to incorporate it into existing workflows with minimal friction.
Supported platforms include:
-
Hugging Face Ecosystem (transformers, Sentence-Transformers, transformers.js) -
Vector Databases (Weaviate, and other similar systems) -
On-Device Inference Frameworks (llama.cpp, MLX, Ollama, LiteRT) -
Development Tools (LMStudio, LangChain, LlamaIndex) -
Cloud Platforms (Cloudflare Workers AI, Vertex AI)
This broad compatibility ensures that teams can adopt EmbeddingGemma without overhauling their existing technology stack, significantly reducing implementation time and complexity.
Optimization Techniques: Maximizing Performance in Production
How can developers optimize EmbeddingGemma for specific production environments? The model supports various quantization configurations that reduce memory usage while preserving quality, making it adaptable to different hardware constraints.
Quantization performance comparisons:
*Mixed Precision refers to per-channel quantization with int4 for embeddings, feedforward, and projection layers, and int8 for attention (e4_a8_f4_p4).
These optimization options allow developers to fine-tune the model’s resource consumption based on their specific accuracy and performance requirements.
Use Case Examples: Real-World Applications Across Industries
What practical problems can EmbeddingGemma solve for developers and organizations? The model enables a wide range of applications that benefit from on-device processing, multilingual support, and high-quality embeddings.
Personal Knowledge Management
Users can search across personal files, messages, emails, and notifications without internet connectivity, with all processing occurring locally on their devices. This is particularly valuable for professionals handling sensitive information who cannot rely on cloud-based solutions.
Industry-Specific Chatbots
Organizations can develop customized chatbots that leverage proprietary knowledge bases without exposing sensitive data to external servers. The combination of EmbeddingGemma for retrieval and Gemma 3n for generation creates a complete offline solution.
Mobile Agent Systems
EmbeddingGemma can classify user queries to relevant function calls, enabling more sophisticated mobile agents that understand user intent and can trigger appropriate actions based on semantic understanding rather than simple keyword matching.
Author’s Reflection: The versatility of EmbeddingGemma continues to impress me. While benchmarking the model, I discovered that its consistent performance across languages and domains makes it unusually reliable for production use. This reliability, combined with its efficiency, addresses a critical gap in the on-device AI landscape.
Training and Data Considerations: Building a Responsible Model
What data and training approaches ensure EmbeddingGemma’s quality and safety? The model was trained on a diverse dataset of approximately 320 billion tokens including web documents, code, technical documentation, and synthetic task-specific data across 100+ languages.
Data processing included rigorous filtering:
-
CSAM (Child Sexual Abuse Material) filtering at multiple stages -
Sensitive data filtering to remove personal information -
Content quality and safety filtering aligned with responsible AI policies
This comprehensive approach ensures that the model benefits from diverse training data while maintaining high standards of safety and responsibility.
Comparative Analysis: Choosing the Right Embedding Solution
When should developers choose EmbeddingGemma over other embedding models? The decision depends on specific application requirements, with EmbeddingGemma excelling in scenarios where privacy, offline operation, or resource constraints are primary considerations.
For most large-scale, server-side applications, Google’s Gemini Embedding model via the Gemini API may provide higher quality and maximum performance. However, for on-device, offline use cases, EmbeddingGemma offers unmatched advantages in privacy, speed, and efficiency.
Implementation Guide: Getting Started with EmbeddingGemma
What are the practical steps for integrating EmbeddingGemma into a project? The process is straightforward thanks to extensive documentation and ecosystem support.
Installation and Basic Usage
pip install -U sentence-transformers
from sentence_transformers import SentenceTransformer
# Download and initialize the model
model = SentenceTransformer("google/embeddinggemma-300m")
# Generate embeddings for text
embeddings = model.encode(["Your text to embed here"])
# For specific use cases, use tailored prompts
query = "task: search query | query: What is the capital of France?"
document = "title: European Capitals | text: Paris is the capital of France."
query_embedding = model.encode([query])
document_embedding = model.encode([document])
Optimization for Production
Developers should consider:
-
Using appropriate quantization based on hardware constraints -
Pre-computing embeddings for static content -
Selecting the optimal embedding dimension for their use case -
Implementing caching strategies for frequent queries
Future Directions: The Evolution of On-Device Embeddings
What does EmbeddingGemma’s development suggest about the future of on-device AI? The model represents a significant step toward increasingly sophisticated AI capabilities running directly on consumer devices, reducing reliance on cloud services while improving privacy and responsiveness.
As hardware continues to improve and model optimization techniques advance, we can expect further innovations in this space, with models like EmbeddingGemma paving the way for more accessible, efficient, and private AI applications across industries.
Action Checklist: Implementing EmbeddingGemma in Your Projects
-
Assess Requirements: Determine your specific needs for dimensionality, accuracy, and hardware constraints -
Choose Integration Method: Select from supported frameworks based on your existing infrastructure -
Implement Embedding Generation: Incorporate embedding creation into your data processing pipeline -
Set Up Retrieval System: Develop similarity search capabilities using your preferred vector database or custom implementation -
Optimize Performance: Experiment with different dimensions and quantization settings to find the optimal balance for your use case -
Test Thoroughly: Validate performance across your specific documents and query types -
Deploy and Monitor: Implement in production and monitor performance metrics
One-Page Overview: EmbeddingGemma Essentials
Core Characteristics:
-
308 million parameters (100M model parameters + 200M embedding parameters) -
Supports 100+ languages with state-of-the-art multilingual performance -
768-dimensional embeddings with Matryoshka support down to 128 dimensions -
2048-token context window -
Quantized version uses less than 200MB RAM
Performance Highlights:
-
Highest-ranked open multilingual embedding model under 500M parameters on MTEB -
Sub-15ms inference time for 256 tokens on EdgeTPU -
Maintains quality even with reduced dimensionality through MRL
Use Cases:
-
Mobile RAG applications -
Offline semantic search -
Multilingual document retrieval -
Privacy-sensitive AI features
Integration Support:
-
Hugging Face ecosystem -
Popular vector databases -
On-device inference frameworks -
Cloud AI platforms
Frequently Asked Questions
What hardware requirements does EmbeddingGemma have?
EmbeddingGemma is designed to run on consumer hardware including mobile phones, laptops, and desktops. The quantized version requires less than 200MB of RAM, making it accessible for most modern devices.
How does EmbeddingGemma handle different languages?
The model was trained on data from 100+ languages and demonstrates strong performance in cross-lingual retrieval tasks. It can understand queries in one language and retrieve relevant documents in other languages.
Can I fine-tune EmbeddingGemma for my specific domain?
Yes, the model supports fine-tuning for specific domains, tasks, or languages. Google provides guidance and resources for effective fine-tuning to adapt the model to particular use cases.
What is the difference between EmbeddingGemma and Gemini Embedding models?
EmbeddingGemma is designed for on-device, offline use with strong performance in a compact size. Gemini Embedding models are larger, server-based solutions that may offer higher performance for applications where cloud processing is acceptable.
How does Matryoshka Representation Learning benefit practical applications?
MRL allows developers to adjust embedding dimensions based on their specific needs for storage efficiency versus retrieval accuracy without retraining the model. This flexibility is valuable for applications with varying resource constraints.
What types of applications benefit most from EmbeddingGemma?
Applications requiring privacy, offline operation, low latency, or multilingual support benefit most from EmbeddingGemma. This includes mobile apps, edge computing scenarios, and situations involving sensitive data.
How does EmbeddingGemma ensure responsible AI practices?
The model was trained with rigorous data filtering including CSAM detection, sensitive data removal, and content quality measures. It also adheres to Google’s responsible AI policies and prohibited use guidelines.
What support is available for developers implementing EmbeddingGemma?
Extensive documentation, integration guides, and examples are available through Google’s developer resources. The model also benefits from broad ecosystem support across popular frameworks and tools.
