NVIDIA Orchestrator-8B:8B 参数模型如何在效率与性能上击败 GPT-5
「核心问题:一个只有 8B 参数的小模型,是怎么做到在最难的 Humanity’s Last Exam(HLE)上拿到 37.1% 分数,超过 GPT-5 的 35.1%,同时成本只有后者的 30%、速度快 2.5 倍的?」
答案在于一个全新的范式——「Orchestrator(编排者)」。它不再依赖单一巨型模型硬算,而是让一个小模型成为“指挥大脑”,动态调度一整套异构工具和专家模型(包括 GPT-5、Claude Opus 4.1、数学模型、代码模型、搜索、代码解释器等),把复杂任务拆解后交给最合适、最划算的工具去解决。
这篇博客将完整拆解 NVIDIA 最新发布的 Orchestrator-8B(ToolOrchestra 项目)的核心思想、训练方法、实际效果,以及如果你想自己跑通整个系统,该怎么一步步操作。
为什么需要 Orchestrator?单体大模型的三大痛点
「本节核心问题:为什么 GPT-5 这种顶级模型在面对真正难的问题时仍然效率低下?」
-
计算成本爆炸:HLE 这类多学科、需要深度推理的题目,GPT-5 平均要消耗巨量 token 和金钱才能勉强答对。 -
工具使用不理性:直接给 GPT-5 开工具,它要么过度依赖自己(自我增强偏差),要么每一步都调用最贵的模型,完全不考虑性价比。 -
缺乏用户可控性:用户无法指定“我愿意为这题最多花 0.5 美元”或“我不想用某个厂商的模型”。
Orchestrator 的思路很简单:「用一个小模型专门负责“决策”,把推理、工具调用、成本控制全部交给它」,而真正的重型计算交给外部专家工具。这样既能达到甚至超越最强单体模型的准确率,又能把成本和延迟压到极低。
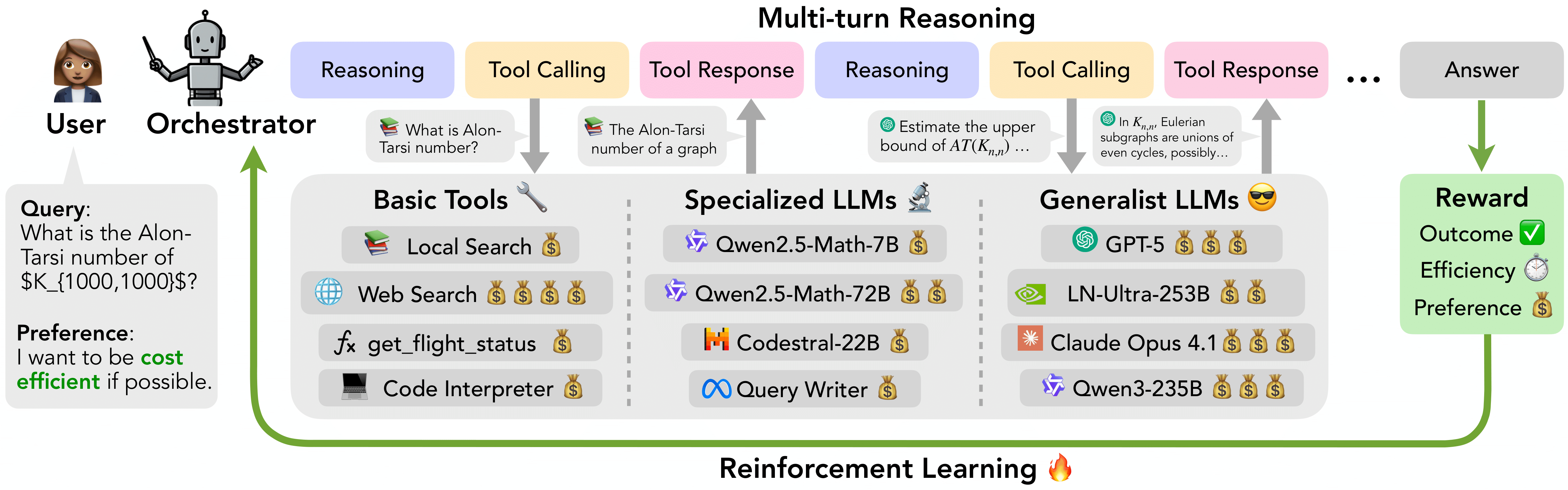
图片来源:NVIDIA 官方公开图
Orchestrator-8B 核心能力一览
| 能力维度 | 具体表现 |
|---|---|
| 准确率 | HLE 37.1%(GPT-5 35.1%)、τ²-Bench 80.2%(GPT-5 单模型 77.7%) |
| 成本效率 | 同等准确率下仅需 GPT-5 的 30% 费用 |
| 速度 | 平均 2.5 倍加速 |
| 工具调度灵活性 | 可同时调度基础工具、专长模型(数学、代码)、通用大模型(GPT-5、Claude) |
| 用户偏好对齐 | 支持指定对每个工具的偏好权重(0~1),模型会严格遵守 |
| 泛化能力 | 对未见过的工具、未见过的价格配置也能快速适应 |
它到底是怎么训练出来的?—— ToolOrchestra 方法论
「本节核心问题:一个小模型是怎么学会在正确性、成本、用户偏好三者之间做最优决策的?」
答案是端到端的多目标强化学习(RL),核心是 「GRPO(Group Relative Policy Optimization)」 + 精心设计的复合奖励函数。
奖励函数包含三个部分:
-
「Outcome Reward(结果奖励)」:答案对不对,0 或 1。 -
「Efficiency Reward(效率奖励)」:每一步工具调用的金钱成本和延迟,越低奖励越高。 -
「Preference Reward(偏好奖励)」:用户给每个工具设定偏好分数 pa∈[0,1],模型调用时会尽量贴近用户偏好。
最终奖励 = 结果正确 × 归一化的效率分数 × 偏好对齐分数
只有答对的轨迹才会有非零奖励,答错直接归零,这迫使模型必须在保证正确的前提下拼命省钱、尊重偏好。
「个人反思」:这套奖励设计让我印象最深刻的地方在于——它把“省钱”这件事从“软约束”变成了“硬优化目标”。过去我们总觉得省钱是副产品,现在它直接决定了梯度方向,这才是真正把效率写进模型 DNA 的做法。
数据是怎么来的?ToolScale 数据集
为了支撑 RL 训练,NVIDIA 构建了自动化的多轮工具交互数据生成流水线,产出了 ToolScale 数据集(已开源),包含:
-
GeneralThought-430K(过滤版) -
全新合成的 ToolScale 多轮工具交互数据
这些数据覆盖 10 个不同领域,包含复杂环境状态、工具调用、验证答案,完全可自动评估,完美适合 RL 训练。
实际跑分对比:8B 小模型把 GPT-5 按在地上摩擦
HLE(Humanity’s Last Exam)成绩
| 模型 | 得分 | 相对成本 | 速度倍数 |
|---|---|---|---|
| Orchestrator-8B | 37.1% | 30% | 2.5× |
| GPT-5 | 35.1% | 100% | 1× |
| Claude Opus 4.1 | <35.1% | 极高 | 慢 |
| Qwen3-235B-A22B | 远低于37.1% | 高 | 慢 |
τ²-Bench(函数调用 + 工具调度)
| 工具集 | 模型作为 Orchestrator | τ²-Bench 得分 | 成本 | 延迟 |
|---|---|---|---|---|
| 仅基础工具 + 小模型 | Qwen3-8B | 40.7 | 1.6 | 2.3 |
| 基础工具 + 专长模型 + 通用大模型(全套) | GPT-5 | 62.3 | 18.2 | 14.5 |
| 基础工具 + 专长模型 + 通用大模型(全套) | 「Orchestrator-8B」 | 「80.2」 | 「10.3」 | 「8.6」 |
可以看到,Orchestrator-8B 只用了 GPT-5 约 56% 的成本,就把性能拉开将近 18 个点。
「工具调用次数统计(跨三个基准平均)」
| Orchestrator 模型 | GPT-5 调用次数 | GPT-5-mini | 搜索 | 代码解释器 | 其他模型 |
|---|---|---|---|---|---|
| GPT-5 自己 | 2.7 | 5.6 | 0.5 | 1.0 | 很少 |
| Claude Opus 4.1 | 6.2 | 0.2 | 1.0 | 1.4 | 很少 |
| 「Orchestrator-8B」 | 「1.6」 | 1.7 | 1.8 | 0.8 | 适度使用 |
Orchestrator-8B 真正做到了“该用贵的才用贵”,而不是像某些模型一样每一步都狂砸 GPT-5。
环境搭建与完整复现指南(可直接复制运行)
「本节核心问题:我自己想跑通 Orchestrator-8B,该怎么最快上手?」
# 1. 克隆代码库
git clone https://github.com/NVlabs/ToolOrchestra.git
cd ToolOrchestra
# 2. 下载索引和模型(需要 HuggingFace 账号登录)
git clone https://huggingface.co/datasets/multi-train/index
export INDEX_DIR='/your/path/to/index'
git clone https://huggingface.co/multi-train/ToolOrchestrator
export CHECKPOINT_PATH='/your/path/to/checkpoint'
# 3. 创建训练环境
conda create -n toolorchestra python=3.12 -y
conda activate toolorchestra
pip install -r requirements.txt
pip install -e training/rollout
# 4. 创建检索服务环境
conda create -n retriever python=3.12 -y
conda activate retriever
conda install pytorch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 pytorch-cuda=12.1 -c pytorch -c nvidia
pip install transformers datasets pyserini
conda install -c pytorch -c nvidia faiss-gpu
pip install uvicorn fastapi
# 5. 创建 vLLM 服务环境(用于托管各种专家模型)
conda create -n vllm1 python=3.12 -y
conda activate vllm1
pip install torch transformers vllm
cd evaluation/tau2-bench
pip install -e .
# 6. 设置环境变量
export HF_HOME="/your/huggingface/cache"
export REPO_PATH="/your/path/to/ToolOrchestra"
export CKPT_DIR="/your/path/to/checkpoint"
申请搜索 API(必须)
去 https://app.tavily.com 申请免费 Key(每月有一定免费额度足够测试)
export TAVILY_KEY="tvly-xxxxxx"
评估跑通(最快验证是否成功)
# 评估 HLE(需要 retriever + vllm1 环境都启动)
cd evaluation
python run_hle.py
# 评估 FRAMES
python run_frames.py
# 评估 τ²-Bench
cd tau2-bench
python run.py
如果你只想快速体验推理,不想训练:
# 直接下载官方发布模型
git lfs install
git clone https://huggingface.co/nvidia/Orchestrator-8B
模型基于 Qwen3-8B 微调,8B 参数,兼容 vLLM、Transformers 直接加载。
进阶:如何改造成自己的私有化编排系统
-
修改 LLM_CALL.py中的get_llm_response函数,可接入自己内网的 vLLM、OpenAI-compatible API、Ollama 等。 -
修改 eval_hle.py和eval_frames.py中的tool_config,增删工具。 -
修改 tools.json增加自定义函数工具。 -
如需并行跑多个实验,修改 training/resume_h100.py中的实验名即可。
一页速览(One-page Summary)
| 项目 | 内容 |
|---|---|
| 模型 | Orchestrator-8B(基于 Qwen3-8B) |
| 参数量 | 8B |
| HLE 得分 | 37.1%(GPT-5 35.1%) |
| 成本 | ≈ GPT-5 的 30% |
| 速度 | 2.5 倍 |
| 训练方法 | GRPO + 多目标奖励(准确率 + 效率 + 用户偏好) |
| 关键创新 | 小模型做编排者 + 异构工具集 + 端到端效率优化 |
| 数据集 | ToolScale(开源) |
| 代码 & 模型 | https://github.com/NVlabs/ToolOrchestra |
| 模型下载 | https://huggingface.co/nvidia/Orchestrator-8B |
实用操作清单(直接照做即可跑通)
-
申请 Tavily Key -
克隆仓库 + 下载模型 -
创建三个 conda 环境(toolorchestra / retriever / vllm1) -
启动 vLLM 服务托管专家模型(至少启动一个 GPT-like 模型) -
运行 python run_hle.py看到 37.x% 即成功
常见问答(FAQ)
「Q1:Orchestrator-8B 能直接商用吗?」
只能用于研究与开发,许可证为 NVIDIA 专用许可证,商用前需联系 NVIDIA。
「Q2:一定要用 GPT-5 吗?可以全部换成本地模型吗?」
完全可以。把所有外部 LLM 换成自己 vLLM 托管的 Llama-3.3-70B、Qwen3-235B 等,性能会有下降但成本几乎为零。
「Q3:为什么训练要用 GRPO 而不是 PPO?」
GRPO 是分组相对策略优化,在多目标场景下收敛更快、更稳定,官方论文里专门提到这一点。
「Q4:用户偏好是怎么设定的?」
在调用时传入一个字典,如 {"gpt-5": 0.3, "local-search": 1.0, "claude": 0.0},模型会尽量少用 Claude。
「Q5:HLE 数据集公开了吗?」
HLE 本身没有公开,但官方提供了完整评估脚本,只要拿到题目 JSONL 就能跑。
「Q6:8B 模型推理要多少显存?」
FP16 下约 18~20GB,INT8 量化后 10GB 左右,单张 4090 完全够用。
「Q7:能不能只用 Orchestrator-8B 自己推理,不调用任何外部模型?」
可以,但性能会大幅下降(降到 20% 左右),它的核心价值就是“聪明地调用别人”。
「Q8:未来会开源训练代码和完整数据集吗?」
目前已开源推理、评估、数据合成流水线,RL 训练主脚本也已放出,基本可以完整复现。
结语:编排者才是未来
Orchestrator-8B 用最直接的数据证明了一件事:「在 agent 时代,真正稀缺的不是算力,而是“会用算力”的智慧」。
一个 8B 的小模型,通过学习在正确的时间把正确的问题交给正确的工具,就能击败几千亿参数的巨型模型,还省下 70% 的钱。这不是参数战争的胜利,而是架构和训练范式的胜利。
当我们不再把“越大越好”当作唯一信仰,而是开始认真思考“如何最聪明地使用所有可用资源”,AI 才能真正走向高效、可控、可落地的未来。
Orchestrator-8B 只是第一步,但已经足够震撼。
(全文约 3800 字)
