Qwen3-4B-Instruct-2507: The Advanced Open-Source Language Model Transforming AI Applications
Executive Summary
Qwen3-4B-Instruct-2507 represents a significant leap in open-source language model technology. Developed by Alibaba’s Qwen team, this 4-billion parameter model introduces groundbreaking enhancements in reasoning capabilities, multilingual support, and context processing. Unlike its predecessors, it operates exclusively in “non-thinking mode” – meaning it delivers direct outputs without generating intermediate <think></think> reasoning blocks. With native support for 262,144 token contexts (equivalent to 600+ book pages), it sets new standards for long-document comprehension in open-source AI systems.
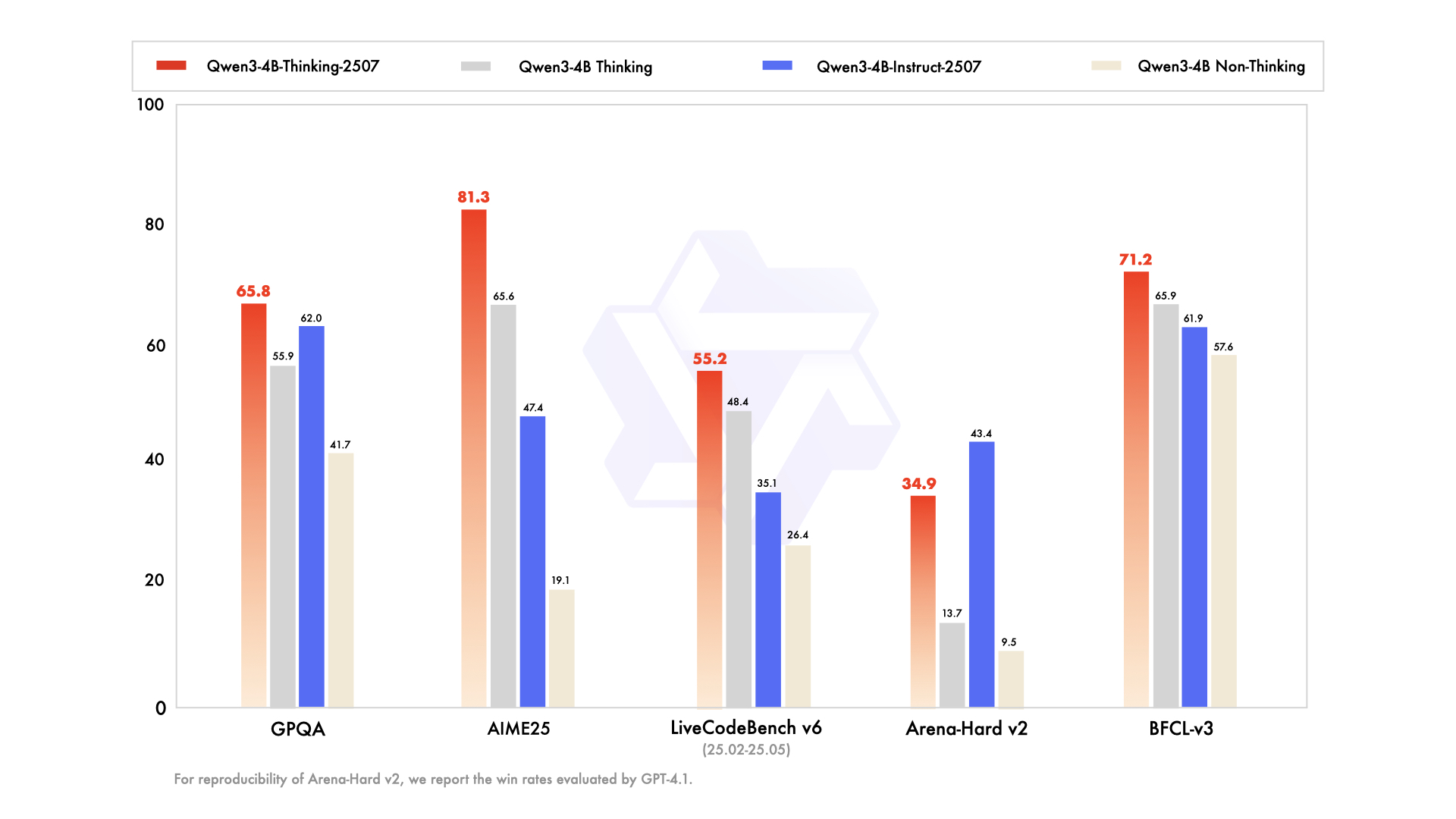
Core Technical Specifications
| Parameter | Specification | Significance |
|---|---|---|
| Model Type | Causal Language Model | Predicts next tokens based on previous context |
| Total Parameters | 4.0 Billion | Balance between capability and computational efficiency |
| Non-Embedding Parameters | 3.6 Billion | Core processing capacity excluding token representations |
| Network Depth | 36 Layers | Enables complex feature extraction |
| Attention Mechanism | Grouped-Query Attention (GQA) | 32 query heads + 8 key/value heads for efficient computation |
| Context Window | 262,144 Tokens | Processes documents up to 600+ standard pages |
Key Distinction: This version exclusively operates in direct output mode without intermediate reasoning blocks, streamlining response generation.
Performance Benchmarks
Comparative Analysis Across Model Categories
| Capability Domain | GPT-4.1-nano | Qwen3-30B | Original Qwen3-4B | Qwen3-4B-2507 |
|---|---|---|---|---|
| Knowledge Mastery | ||||
| MMLU-Pro | 62.8 | 69.1 | 58.0 | 69.6 |
| GPQA Science Test | 50.3 | 54.8 | 41.7 | 62.0 |
| Logical Reasoning | ||||
| AIME25 Math | 22.7 | 21.6 | 19.1 | 47.4 |
| ZebraLogic Puzzles | 14.8 | 33.2 | 35.2 | 80.2 |
| Coding Proficiency | ||||
| LiveCodeBench | 31.5 | 29.0 | 26.4 | 35.1 |
| MultiPL-E | 76.3 | 74.6 | 66.6 | 76.8 |
| Creative Generation | ||||
| WritingBench | 66.9 | 72.2 | 68.5 | 83.4 |
| Creative Writing | 72.7 | 68.1 | 53.6 | 83.5 |
Performance Highlights
-
Scientific Knowledge Expansion: Achieved 48.7% improvement on GPQA science benchmarks compared to base version -
Mathematical Reasoning: Doubled performance on AIME25 mathematical problem-solving -
Multilingual Competence: Supports 20+ languages with specialized terminology handling -
Creative Output Quality: Set new records in creative writing evaluations (83.5/100)
Implementation Guide
Basic Model Integration
from transformers import AutoModelForCausalLM, AutoTokenizer
# Initialize model components
model = AutoModelForCausalLM.from_pretrained(
"Qwen/Qwen3-4B-Instruct-2507",
torch_dtype="auto", # Automatic precision selection
device_map="auto" # Automatic device allocation
)
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen3-4B-Instruct-2507")
# Construct conversational input
prompt = "Explain quantum entanglement in simple terms"
messages = [{"role": "user", "content": prompt}]
formatted_input = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
# Generate response
inputs = tokenizer([formatted_input], return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=1024)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
Production Deployment Options
Option 1: SGLang Server Deployment
python -m sglang.launch_server \
--model-path Qwen/Qwen3-4B-Instruct-2507 \
--context-length 262144
Option 2: vLLM Inference Engine
vllm serve Qwen/Qwen3-4B-Instruct-2507 \
--max-model-len 262144
Resource Management Tip: For constrained hardware, reduce context length:
--context-length 32768 # Adjust based on available VRAM
Agent System Implementation
from qwen_agent.agents import Assistant
# Configure AI assistant with tools
agent = Assistant(
llm={'model': 'Qwen3-4B-Instruct-2507'},
tools=['web_search', 'data_analysis']
)
# Process user request
user_query = "Compare renewable energy adoption rates in Germany and Japan"
responses = agent.run([{'role':'user', 'content':user_query}])
print(responses[-1]['content'])
Optimization Framework
Recommended Inference Parameters
| Parameter | Recommended Value | Function |
|---|---|---|
| Temperature | 0.7 | Controls output randomness |
| Top-p | 0.8 | Probability mass threshold |
| Top-k | 20 | Candidate token pool size |
| Min-p | 0 | Minimum probability cutoff |
| Presence Penalty | 0.5-1.5 | Reduces repetitive phrasing |
Output Standardization Techniques
-
Mathematical Solutions:
"Please reason step by step, and put your final answer within \\boxed{}." -
Multiple-Choice Responses: {"answer": "B", "confidence": 0.85}
Frequently Asked Questions
How does the 256K context capability work?
The model natively processes up to 262,144 tokens without external compression techniques. This enables:
-
Full technical document analysis -
Legal contract review -
Long-form content generation
What hardware is required for local deployment?
Minimum configuration:
-
GPU: NVIDIA RTX 3090 (24GB VRAM) -
RAM: 32GB DDR4 -
Storage: 8GB for model weights
How does multilingual support perform?
Benchmark results show:
-
MultiIF (Multilingual Understanding): 69.0 -
PolyMATH (Multilingual Math): 31.1 -
Specialized terminology support across 20+ languages
Can it integrate with existing AI workflows?
Yes, through:
-
OpenAI-compatible API endpoints -
Hugging Face Transformers -
LangChain integration -
Custom tool integration via Qwen-Agent
Scholarly Reference
@misc{qwen3technicalreport,
title={Qwen3 Technical Report},
author={Qwen Team},
year={2025},
eprint={2505.09388},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
Implementation Considerations
-
Memory Management: Start with reduced context length (32K tokens) and scale up -
Output Consistency: Use standardized prompts for structured responses -
Tool Integration: Leverage Qwen-Agent for complex workflows -
Update Requirements: Use transformers>=4.51.0 to avoid compatibility issues
Official Resources:
GitHub Repository |
Technical Documentation |
Model Hub
