MiniCPM-V 4.5:手机可运行的GPT-4o级多模态模型——全面解析与实用指南
如果你正在寻找一款既能在手机上流畅运行,又具备GPT-4o级别视觉语言能力的多模态模型,那么面壁最新推出的MiniCPM-V 4.5或许会成为你的首选。这款模型在保持轻量级(仅80亿参数量)的同时,在视觉语言理解、长视频处理、OCR与文档解析等核心能力上,甚至超越了GPT-4o-latest、Gemini 2.0 Pro等知名大模型。接下来,我们将从模型基础、性能表现、核心功能、实用操作指南到部署方式,全面拆解这款“小而强”的端侧多模态模型,帮你搞清楚它到底能做什么、怎么用、是否适合你的需求。
一、MiniCPM-V 4.5基础信息:轻量级架构,端侧友好
在深入了解功能前,我们先搞清楚MiniCPM-V 4.5的“底子”——它的架构、参数量和核心依赖,这些是理解它“为何能在手机上跑且性能强”的关键。
1.1 核心参数概览
| 项目 | 详情 |
|---|---|
| 模型系列 | MiniCPM-V系列最新版本(当前最强端侧多模态模型) |
| 基础架构 | 基于Qwen3-8B(语言模型)与SigLIP2-400M(视觉模型)构建 |
| 总参数量 | 80亿(8B) |
| 端侧运行能力 | 支持手机(如iPhone、iPad M4)、普通电脑本地运行(CPU/GPU均可) |
| 核心设计目标 | 在轻量级硬件上实现GPT-4o级别的单图、多图及视频理解能力 |
| 官方资源链接 | GitHub:https://github.com/OpenBMB/MiniCPM-o 在线Demo:http://101.126.42.235:30910/ |
从参数能看出,MiniCPM-V 4.5的核心优势在于“轻量高性能”——8B参数量远低于Qwen2.5-VL 72B(720亿参数量),但性能却能超越后者,这为它在手机、普通电脑等端侧设备运行奠定了基础。
二、性能评估:8B参数量超越GPT-4o,30B以下最优
很多人会问:“这么轻量的模型,性能真的能打吗?”我们直接看权威评估数据——在OpenCompass(涵盖8个流行视觉语言基准的综合评估平台)上,MiniCPM-V 4.5的平均分达到77.2,这个成绩让它在同级别模型中脱颖而出。
2.1 关键评估结果
- •
超越多款知名模型:仅8B参数量,却在视觉语言能力上超过了GPT-4o-latest(OpenAI最新多模态模型)、Gemini 2.0 Pro(Google旗舰模型),以及开源领域的强模型Qwen2.5-VL 72B。 - •
30B参数量以下最优:在参数量30B(300亿)以下的多模态模型(MLLM)中,MiniCPM-V 4.5的性能排名第一,成为轻量级模型中的“性能标杆”。
2.2 评估可视化参考
以下两张图表直观展示了MiniCPM-V 4.5与其他模型的性能对比(数据来源:MiniCPM-V 4.5官方评估):
-
性能雷达图(覆盖多维度视觉语言能力):
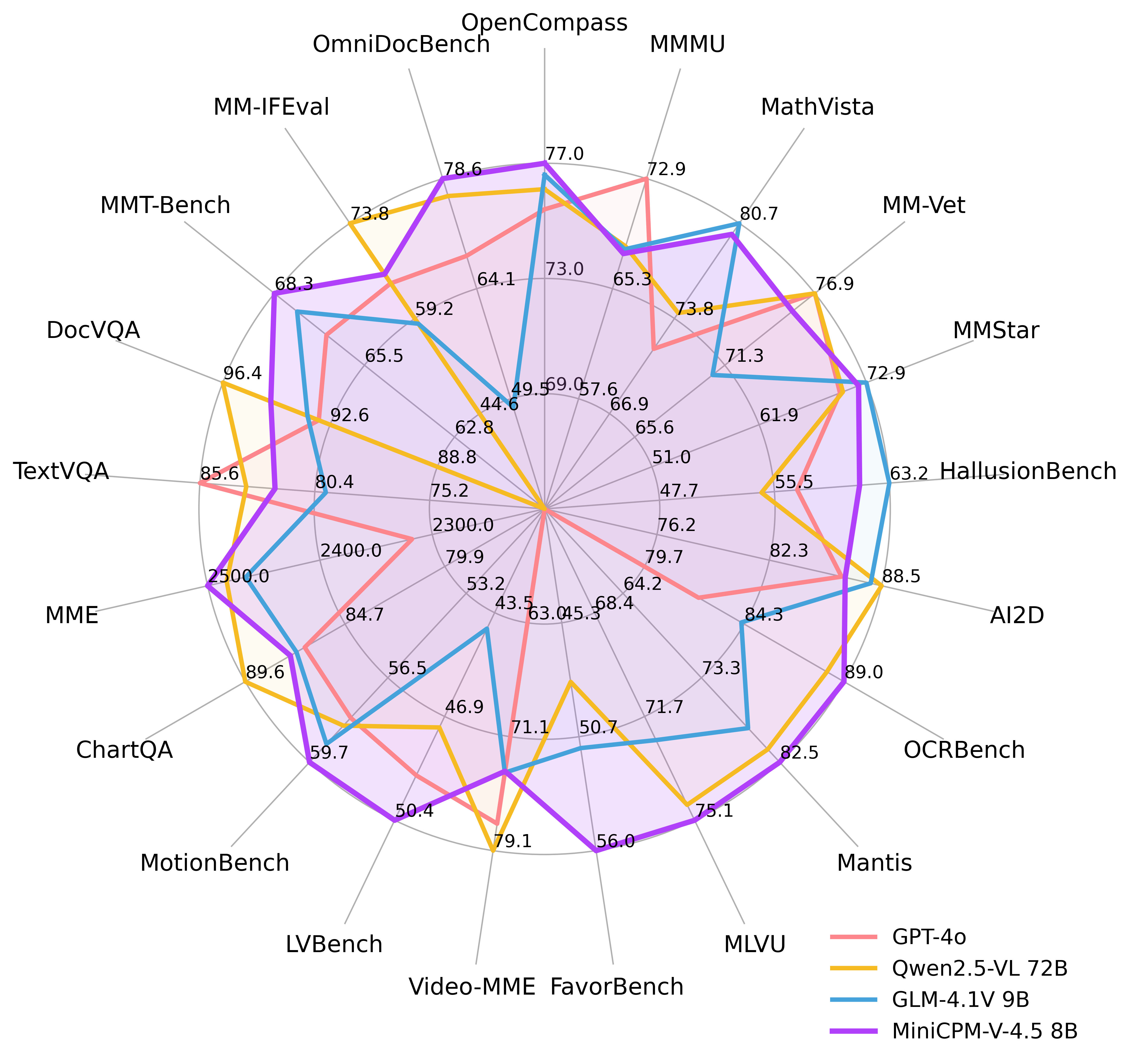
-
详细评估结果对比图:

从评估来看,MiniCPM-V 4.5打破了“参数量越大性能越强”的固有认知,尤其适合对硬件资源有限,但又需要高性能多模态能力的场景(如手机端应用、普通办公电脑本地处理)。
三、核心功能解析:从视频理解到OCR,覆盖多场景需求
MiniCPM-V 4.5的功能设计围绕“实用”展开,无论是日常高频使用,还是复杂专业场景,都能找到对应的解决方案。我们逐一拆解它的核心功能,以及这些功能能解决什么实际问题。
3.1 高效处理高帧率与长视频:3D-Resampler技术是关键
很多多模态模型处理视频时会遇到“帧越多、计算量越大”的问题,导致手机或普通电脑无法处理长视频或高帧率视频。MiniCPM-V 4.5通过3D-Resampler技术解决了这个痛点。
- •
技术原理(通俗解读):3D-Resampler能把大量视频帧“压缩”成少量token(模型能理解的基本单位)。比如,6个448×448分辨率的视频帧,其他多模态模型通常需要1536个token来处理,而MiniCPM-V 4.5仅需64个token——相当于压缩了96倍。 - •
实际优势: - •
不增加模型推理成本的前提下,能处理更多视频帧; - •
支持最高10FPS的高帧率视频理解(比如运动场景、快速变化的画面); - •
轻松应对长视频(在Video-MME、LVBench、MotionBench等视频评估基准上表现顶尖)。
- •
适用场景:比如用手机拍摄一段1分钟的运动视频,想让模型分析视频中的动作;或者处理监控长视频,提取关键信息——这些场景下,MiniCPM-V 4.5不会因为视频长、帧率高而卡顿。
3.2 可控的快/深度思考双模式:兼顾效率与复杂问题
不同使用场景对“速度”和“精度”的需求不同:比如日常问“图片里有什么”,需要快;而分析“图片中的地质结构是否符合某种特征”,需要更深度的推理。MiniCPM-V 4.5支持一键切换快/深度思考模式,完美平衡效率与性能。
| 模式 | 适用场景 | 优势 | 缺点 |
|---|---|---|---|
| 快思考模式 | 日常高频使用(如图片内容识别、简单问答) | 效率高,响应快,适合频繁调用 | 不适合复杂问题(如深度推理) |
| 深度思考模式 | 复杂问题(如专业文档解析、视频内容深度分析) | 推理更精准,能解决复杂多步骤问题 | 响应时间比快思考模式长 |
操作方式:在调用模型时,通过enable_thinking参数控制(enable_thinking=True为深度思考,False为快思考),具体代码会在“实用指南”部分展示。
3.3 强大的OCR与文档解析:处理高分辨率与复杂格式
OCR(文字识别)和文档解析是很多办公、学术场景的刚需,但不少模型处理高分辨率图片、复杂表格或手写体时表现不佳。MiniCPM-V 4.5在这方面的能力尤为突出。
3.3.1 OCR功能亮点
- •
支持高分辨率图片:能处理任意长宽比、最高180万像素的图片(比如1344×1344分辨率),且视觉token用量比其他模型少4倍(减少计算压力); - •
性能领先:在OCRBench(OCR领域权威评估)上,超过GPT-4o-latest和Gemini 2.5等商用模型; - •
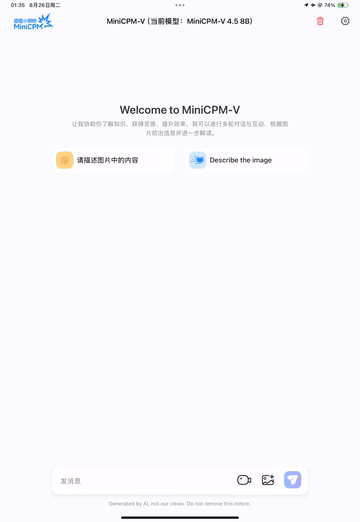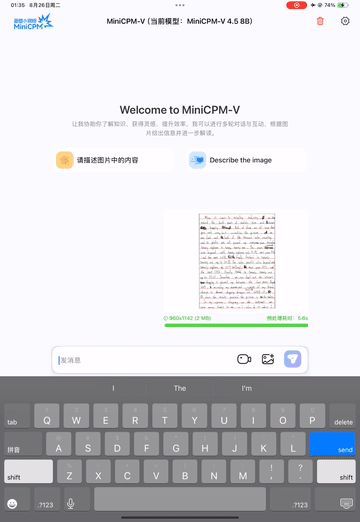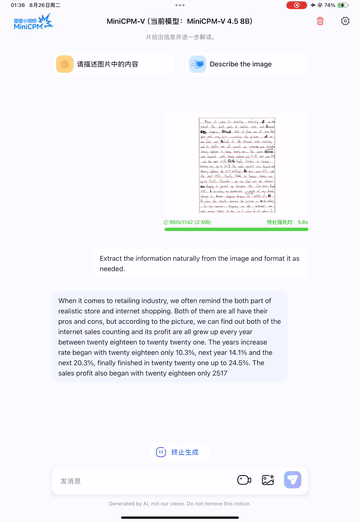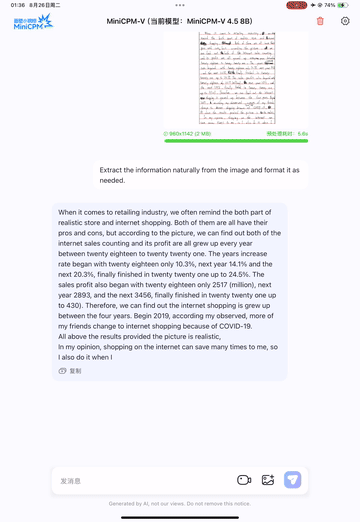
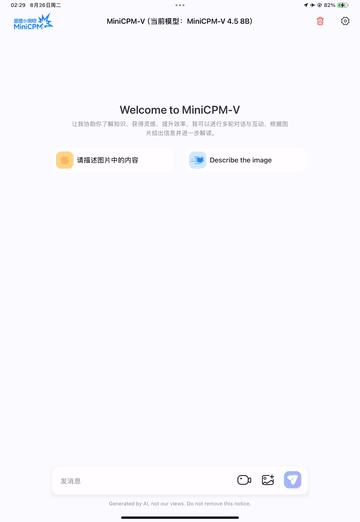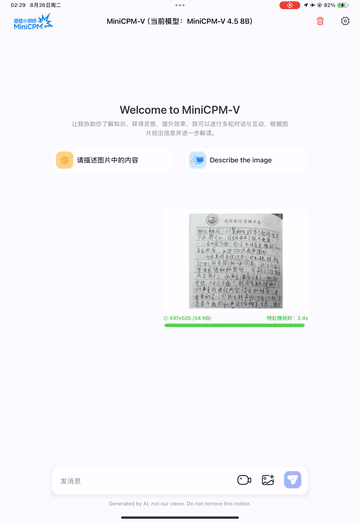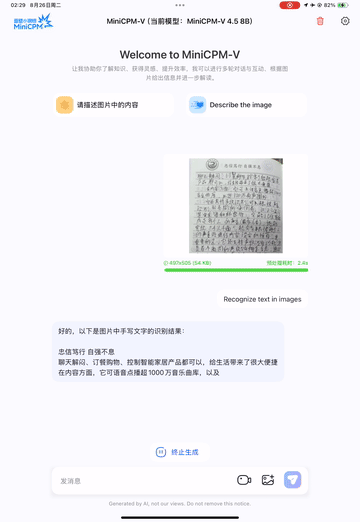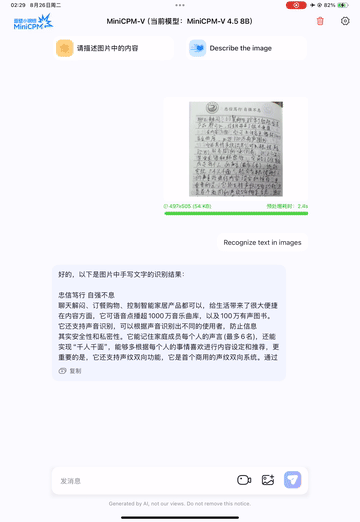
支持手写体OCR:无论是英文手写还是中文手写,都能准确识别(官方提供了手写体识别示例,如下图)。
英文手写体OCR示例:
中文手写体OCR示例:
3.3.2 文档解析能力
- •
PDF解析顶尖:在OmniDocBench(文档解析评估)上,MiniCPM-V 4.5在通用多模态模型中表现第一; - •
处理复杂格式:支持复杂表格、多栏文档、混合图文的PDF解析,比如学术论文中的数据表格、企业财报中的复杂排版。
适用场景:比如用手机拍摄一份手写笔记,通过模型识别成可编辑文字;或者在电脑上解析一份几十页的学术PDF,提取其中的表格数据——这些场景下,MiniCPM-V 4.5能替代传统OCR工具,且精度更高。
3.4 可信性与多语言支持:覆盖更广泛场景
除了基础功能,MiniCPM-V 4.5还在“可信性”和“多语言”上做了优化,满足专业与跨境需求。
- •
可信性:基于RLAIF-V和VisCPM技术,模型生成内容的可信度更高,在MMHal-Bench(模型可信性评估)上超过GPT-4o-latest,减少“一本正经胡说八道”的情况; - •
多语言支持:支持30+种语言,包括中文、英文、日语、法语、西班牙语等,不仅能识别多语言图片/文档,还能进行多语言对话。
适用场景:比如跨境企业处理多语言合同文档;或者学术研究中,分析其他语言的论文图片——多语言能力让模型不再受语言限制。
四、实用指南:如何使用MiniCPM-V 4.5?(附完整代码)
了解了功能后,最关键的是“怎么用”。MiniCPM-V 4.5支持多种使用方式(本地CPU/GPU、手机、在线Demo),我们重点讲解最常用的“Python代码调用”(图片交互、视频交互),以及本地部署的关键步骤。
4.1 环境准备:需要安装哪些工具?
在使用前,需先安装必要的Python库,以下是完整的安装命令(适用于Windows、macOS、Linux):
# 基础依赖(模型加载、图片处理)
pip install torch pillow transformers
# 视频处理依赖(如需处理视频)
pip install decord scipy numpy
# 量化模型支持(如需使用int4、GGUF等量化格式)
pip install autoawq llama-cpp-python
# 高吞吐量推理支持(如需SGLang/vLLM)
pip install sglang vllm
4.2 单图/多图交互:基础使用示例
我们以“分析图片中的地貌,并回答旅行注意事项”为例,展示完整的代码流程(支持多轮对话)。
4.2.1 代码示例
# 1. 导入必要库
import torch
from PIL import Image
from transformers import AutoModel, AutoTokenizer
# 2. 设置随机种子(保证结果可复现)
torch.manual_seed(100)
# 3. 加载模型和Tokenizer
# 注意:trust_remote_code=True用于加载模型的自定义代码
model = AutoModel.from_pretrained(
'openbmb/MiniCPM-V-4_5', # 模型名称(也可使用openbmb/MiniCPM-o-2_6)
trust_remote_code=True,
attn_implementation='sdpa', # 注意力实现方式,可选sdpa或flash_attention_2
torch_dtype=torch.bfloat16 # 数据类型,提升推理效率
)
# 模型设置为评估模式,并加载到GPU(无GPU可删除.cuda(),使用CPU推理)
model = model.eval().cuda()
# 加载Tokenizer(用于处理文本输入)
tokenizer = AutoTokenizer.from_pretrained(
'openbmb/MiniCPM-V-4_5',
trust_remote_code=True
)
# 4. 加载图片(替换为你的图片路径)
image = Image.open('./assets/minicpmo2_6/show_demo.jpg').convert('RGB')
# 5. 设置思考模式(False=快思考,True=深度思考)
enable_thinking = False
# 6. 第一轮对话:询问图片中的地貌
question1 = "What is the landform in the picture?"
# 构建对话历史(格式:list of dict,包含角色和内容)
msgs = [{'role': 'user', 'content': [image, question1]}]
# 调用模型生成回答
answer1 = model.chat(
msgs=msgs,
tokenizer=tokenizer,
enable_thinking=enable_thinking
)
# 打印第一轮回答
print("第一轮回答:")
print(answer1)
print("-" * 50)
# 7. 第二轮对话:基于历史上下文,询问旅行注意事项
# 更新对话历史(添加助手的回答和新的用户问题)
msgs.append({"role": "assistant", "content": [answer1]})
question2 = "What should I pay attention to when traveling here?"
msgs.append({"role": "user", "content": [question2]})
# 调用模型生成第二轮回答(无需重复设置enable_thinking,默认沿用之前的设置)
answer2 = model.chat(
msgs=msgs,
tokenizer=tokenizer
)
# 打印第二轮回答
print("第二轮回答:")
print(answer2)
4.2.2 输出结果示例
# 第一轮回答
The landform in the picture is karst topography. Karst landscapes are characterized by distinctive, jagged limestone hills or mountains with steep, irregular peaks and deep valleys—exactly what you see here These unique formations result from the dissolution of soluble rocks like limestone over millions of years through water erosion.
This scene closely resembles the famous karst landscape of Guilin and Yangshuo in China’s Guangxi Province. The area features dramatic, pointed limestone peaks rising dramatically above serene rivers and lush green forests, creating a breathtaking and iconic natural beauty that attracts millions of visitors each year for its picturesque views.
# 第二轮回答
When traveling to a karst landscape like this, here are some important tips:
1. Wear comfortable shoes: The terrain can be uneven and hilly.
2. Bring water and snacks for energy during hikes or boat rides.
3. Protect yourself from the sun with sunscreen, hats, and sunglasses—especially since you’ll likely spend time outdoors exploring scenic spots.
4. Respect local customs and nature regulations by not littering or disturbing wildlife.
By following these guidelines, you'll have a safe and enjoyable trip while appreciating the stunning natural beauty of places such as Guilin’s karst mountains.
4.2.3 关键参数说明
- •
attn_implementation:注意力机制实现方式,sdpa是PyTorch原生支持的高效方式,flash_attention_2需要额外安装FlashAttention库,速度更快; - •
torch_dtype=torch.bfloat16:使用16位浮点数,比32位(float32)更节省显存,且性能损失小; - •
enable_thinking:控制思考模式,复杂问题建议设为True,简单问题设为False以提升速度。
4.3 视频交互:使用3D-Resampler处理视频
接下来展示如何用MiniCPM-V 4.5处理视频(以“描述视频内容”为例),核心是利用3D-Resampler技术压缩视频帧。
4.3.1 代码示例
# 1. 导入必要库(含视频处理相关)
import torch
from PIL import Image
from transformers import AutoModel, AutoTokenizer
from decord import VideoReader, cpu # 用于读取视频帧
from scipy.spatial import cKDTree
import numpy as np
import math
# 2. 加载模型和Tokenizer(与图片交互一致)
model = AutoModel.from_pretrained(
'openbmb/MiniCPM-V-4_5',
trust_remote_code=True,
attn_implementation='sdpa',
torch_dtype=torch.bfloat16
)
model = model.eval().cuda()
tokenizer = AutoTokenizer.from_pretrained(
'openbmb/MiniCPM-V-4_5',
trust_remote_code=True
)
# 3. 视频处理配置参数(无需修改,按默认即可)
MAX_NUM_FRAMES = 180 # 视频打包后最大接收帧数
MAX_NUM_PACKING = 3 # 视频帧最大打包数量(1-6)
TIME_SCALE = 0.1 # 时间尺度,用于映射帧的时间戳
# 4. 辅助函数:用于视频帧采样和打包(3D-Resampler核心逻辑)
def map_to_nearest_scale(values, scale):
"""将帧时间戳映射到最近的时间尺度"""
tree = cKDTree(np.asarray(scale)[:, None])
_, indices = tree.query(np.asarray(values)[:, None])
return np.asarray(scale)[indices]
def group_array(arr, size):
"""将数组按指定大小分组(用于帧打包)"""
return [arr[i:i+size] for i in range(0, len(arr), size)]
def encode_video(video_path, choose_fps=3, force_packing=None):
"""
处理视频:采样帧、计算打包数量、生成时间戳ID
参数:
video_path: 视频文件路径
choose_fps: 目标帧率(如3表示每秒取3帧)
force_packing: 强制打包数量(默认自动计算)
返回:
frames: 采样后的图片帧列表
frame_ts_id_group: 分组后的时间戳ID(用于3D-Resampler)
"""
# 均匀采样函数
def uniform_sample(l, n):
gap = len(l) / n
idxs = [int(i * gap + gap / 2) for i in range(n)]
return [l[i] for i in idxs]
# 读取视频
vr = VideoReader(video_path, ctx=cpu(0))
fps = vr.get_avg_fps() # 视频原始帧率
video_duration = len(vr) / fps # 视频总时长(秒)
# 计算打包数量和采样帧数
if choose_fps * int(video_duration) <= MAX_NUM_FRAMES:
packing_nums = 1
choose_frames = round(min(choose_fps, round(fps)) * min(MAX_NUM_FRAMES, video_duration))
else:
packing_nums = math.ceil(video_duration * choose_fps / MAX_NUM_FRAMES)
if packing_nums <= MAX_NUM_PACKING:
choose_frames = round(video_duration * choose_fps)
else:
choose_frames = round(MAX_NUM_FRAMES * MAX_NUM_PACKING)
packing_nums = MAX_NUM_PACKING
# 采样视频帧
frame_idx = [i for i in range(0, len(vr))]
frame_idx = np.array(uniform_sample(frame_idx, choose_frames))
# 强制设置打包数量(如需)
if force_packing:
packing_nums = min(force_packing, MAX_NUM_PACKING)
# 打印视频信息
print(f"视频路径:{video_path},时长:{video_duration:.2f}秒")
print(f"采样帧数:{len(frame_idx)},打包数量:{packing_nums}")
# 读取采样帧并转换为图片
frames = vr.get_batch(frame_idx).asnumpy()
frames = [Image.fromarray(v.astype('uint8')).convert('RGB') for v in frames]
# 生成帧的时间戳ID并分组
frame_idx_ts = frame_idx / fps # 帧的时间戳(秒)
scale = np.arange(0, video_duration, TIME_SCALE) # 时间尺度
frame_ts_id = map_to_nearest_scale(frame_idx_ts, scale) / TIME_SCALE
frame_ts_id = frame_ts_id.astype(np.int32)
frame_ts_id_group = group_array(frame_ts_id, packing_nums)
return frames, frame_ts_id_group
# 5. 处理视频(替换为你的视频路径)
video_path = "video_test.mp4"
target_fps = 5 # 目标帧率(每秒5帧)
force_packing = None # 不强制打包数量,自动计算
frames, frame_ts_id_group = encode_video(video_path, target_fps, force_packing)
# 6. 询问视频内容并调用模型
question = "Describe the video"
msgs = [
{'role': 'user', 'content': frames + [question]}, # 内容:帧列表 + 问题
]
# 调用模型生成回答(需指定temporal_ids参数,启用3D-Resampler)
answer = model.chat(
msgs=msgs,
tokenizer=tokenizer,
use_image_id=False,
max_slice_nums=1,
temporal_ids=frame_ts_id_group # 视频帧的时间戳ID分组
)
# 打印回答
print("视频分析结果:")
print(answer)
4.3.2 关键说明
- •
encode_video函数是视频处理的核心,它会根据视频时长和目标帧率,自动计算“打包数量”(确保帧数量不超过模型限制); - •
temporal_ids=frame_ts_id_group是启用3D-Resampler的关键参数,必须传入,否则模型会按普通图片帧处理,无法发挥视频压缩优势; - •
无GPU时,删除 model.eval().cuda()中的.cuda(),改用CPU推理(速度会慢一些,但普通电脑可运行)。
五、本地部署与多平台支持:从电脑到手机都能用
MiniCPM-V 4.5的一大优势是“多平台兼容”,无论你是想在普通电脑上本地运行,还是在手机(iPhone/iPad)上使用,都有对应的解决方案。
5.1 不同平台部署方式对比
| 目标平台 | 部署工具/格式 | 优势 | 适用场景 | 相关链接 |
|---|---|---|---|---|
| 普通电脑(CPU) | llama.cpp、ollama | 无需GPU,高效CPU推理 | 无显卡或低配置电脑 | llama.cpp:https://github.com/tc-mb/llama.cpp ollama:https://github.com/tc-mb/ollama |
| 电脑(GPU) | SGLang、vLLM | 高吞吐量、内存高效,适合批量处理 | 有GPU(如RTX 3060及以上)的电脑 | SGLang:https://github.com/tc-mb/sglang vLLM:官方文档内提及支持 |
| 手机(iOS) | 官方iOS Demo | 直接在iPhone/iPad上运行,支持本地交互 | 移动端场景(如现场图片/OCR识别) | https://github.com/tc-mb/MiniCPM-o-demo-iOS |
| 本地WebUI | Gradio WebUI | 可视化界面,无需写代码 | 非开发人员,需直观操作 | 官方文档提及“quick local WebUI demo”,可参考GitHub Cookbook |
| 在线使用 | 官方在线Demo | 无需部署,直接试用 | 快速测试模型功能 | http://101.126.42.235:30910/ |
5.2 量化模型:进一步降低硬件门槛
如果你的设备硬件资源有限(如电脑只有4GB内存),可以使用MiniCPM-V 4.5的量化模型——通过减少模型参数的精度,降低内存占用,同时尽量保留性能。
官方提供的量化格式及大小:
- •
格式:int4、GGUF、AWQ; - •
大小:16种不同规格(可根据设备内存选择,如int4格式仅需约4GB内存即可运行); - •
获取链接: - •
int4:https://huggingface.co/openbmb/MiniCPM-V-4_5-int4 - •
GGUF:https://huggingface.co/openbmb/MiniCPM-V-4_5-gguf - •
AWQ:需通过AutoAWQ工具加载,参考https://github.com/tc-mb/AutoAWQ
- •
六、许可证与商用说明:免费研究,商用需注册
很多用户关心“使用这个模型是否需要付费?商用是否允许?”,我们根据官方文档整理了关键信息:
6.1 许可证类型
| 类别 | 许可证类型 | 说明 |
|---|---|---|
| 代码(GitHub repo) | Apache-2.0 License | 开源免费,可修改、分发,需保留版权声明 |
| 模型权重 | MiniCPM Model License | 学术研究免费,商用需注册 |
6.2 商用流程
-
学术研究:无需申请,直接免费使用模型权重; -
商用使用: - •
步骤1:填写官方问卷进行注册(问卷链接:https://modelbest.feishu.cn/share/base/form/shrcnpV5ZT9EJ6xYjh3Kx0J6v8g); - •
步骤2:注册通过后,即可免费商用模型权重。
- •
6.3 免责声明
- •
模型生成内容仅为学习和研究使用,不代表模型开发者(面壁)的观点或立场; - •
开发者不对使用模型产生的任何问题负责,包括但不限于数据安全、舆论风险、误用导致的损失。
七、FAQ常见问题解答
我们整理了用户可能关心的高频问题,所有答案均基于官方文档内容:
Q1:MiniCPM-V 4.5和之前的MiniCPM系列模型(如MiniCPM-o、MiniCPM-V)有什么区别?
A1:MiniCPM-V 4.5是当前MiniCPM-V系列中最新、性能最强的模型,主要提升包括:① 视觉语言能力大幅超越前代,在OpenCompass上平均分77.2;② 新增3D-Resampler技术,支持高效视频处理;③ 支持快/深度思考双模式;④ OCR和文档解析能力显著提升,超过GPT-4o-latest。
Q2:没有高端GPU,能在普通电脑上运行MiniCPM-V 4.5吗?
A2:可以。官方支持llama.cpp和ollama工具进行CPU推理,即使没有GPU,普通电脑(如8GB内存)也能运行;如果内存较小(如4GB),建议使用int4或GGUF量化模型,进一步降低内存占用。
Q3:处理长视频时,MiniCPM-V 4.5最大能支持多长时间的视频?
A3:取决于目标帧率和打包数量。例如,目标帧率设为3FPS,最大打包数量为3(MAX_NUM_PACKING=3),则最大支持的视频时长约为(MAX_NUM_FRAMES * MAX_NUM_PACKING)/ 目标帧率 =(180*3)/3 = 180秒(3分钟)。实际使用中,可通过调整choose_fps(目标帧率)参数灵活控制。
Q4:OCR功能能处理手写体吗?支持哪些语言的OCR?
A4:① 支持手写体OCR,官方提供了中文和英文手写体的识别示例,效果优秀;② OCR支持的语言与模型多语言能力一致,共30+种,包括中文、英文、日语、法语等。
Q5:商用MiniCPM-V 4.5需要付费吗?问卷注册有什么要求?
A5:① 商用无需付费,注册通过后即可免费使用;② 问卷注册主要是收集商用单位信息(如企业名称、使用场景),官方未提及额外要求,正常填写即可。
Q6:快思考模式和深度思考模式在性能上有多大差距?怎么切换?
A6:① 性能差距主要体现在复杂问题上:快思考模式适合简单任务(如图片内容识别),响应快;深度思考模式适合复杂推理(如专业文档分析),精度更高,但响应时间更长;② 切换方式:调用model.chat时,通过enable_thinking参数控制(True为深度思考,False为快思考)。
Q7:能用来解析PDF文档吗?支持复杂表格吗?
A7:可以。MiniCPM-V 4.5基于LLaVA-UHD架构,能处理高分辨率PDF,且在OmniDocBench(文档解析评估)上表现顶尖,支持复杂表格、多栏文档、混合图文的PDF解析,适合学术论文、企业财报等场景。
Q8:有办法在Android手机上运行MiniCPM-V 4.5吗?
A8:官方目前已提供iOS Demo(支持iPhone和iPad,如iPad M4),Android端暂未推出官方Demo,但可通过开源工具(如llama.cpp的Android版本)尝试本地部署,具体可关注官方GitHub(https://github.com/OpenBMB/MiniCPM-o)获取最新动态。
八、相关技术与引用
如果想深入了解MiniCPM-V 4.5的技术细节,可参考以下官方相关项目:
- •
VisCPM:https://github.com/OpenBMB/VisCPM(视觉语言模型技术) - •
RLHF-V:https://github.com/RLHF-V/RLHF-V(强化学习对齐技术) - •
LLaVA-UHD:https://arxiv.org/pdf/2403.11703(高分辨率图像处理架构) - •
RLAIF-V:https://github.com/RLHF-V/RLAIF-V/(模型可信性优化技术)
论文引用
如果你的研究或项目中使用了MiniCPM-V 4.5,可引用以下论文:
@article{yao2024minicpm,
title={MiniCPM-V: A GPT-4V Level MLLM on Your Phone},
author={Yao, Yuan and Yu, Tianyu and Zhang, Ao and Wang, Chongyi and Cui, Junbo and Zhu, Hongji and Cai, Tianchi and Li, Haoyu and Zhao, Weilin and He, Zhihui and others},
journal={Nat Commun 16, 5509 (2025)},
year={2025}
}
九、总结
MiniCPM-V 4.5的推出,为“端侧高性能多模态模型”提供了新的可能——它以8B参数量实现了超越GPT-4o-latest的视觉语言能力,支持手机、普通电脑等轻量设备运行,同时覆盖视频理解、OCR、文档解析等多场景需求。无论是学术研究、日常办公,还是商用开发,这款模型都能以“低硬件门槛、高实用价值”的特点,解决实际问题。
如果你想尝试使用,可先通过官方在线Demo(http://101.126.42.235:30910/)快速测试功能,再根据自己的设备和需求,选择本地部署或量化模型。后续官方也会持续更新功能,建议关注GitHub仓库获取最新动态。
