PaddleOCR-VL-1.5:0.9B参数的文档解析新纪元
核心问题:在真实复杂场景下,如何用一个不到1GB的轻量级模型实现94.5%的文档解析准确率?
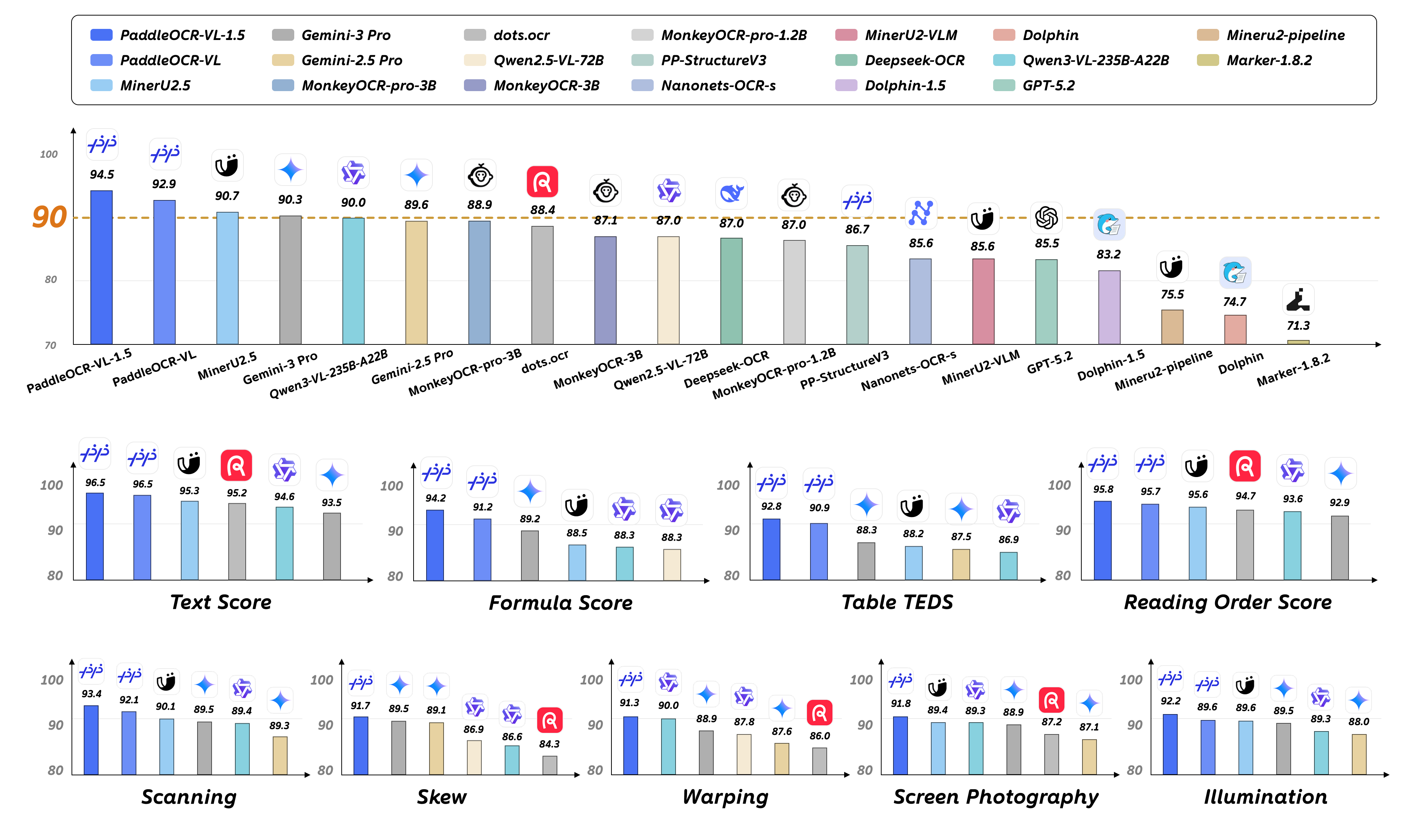
答案很简单:PaddleOCR-VL-1.5做到了。这个仅有0.9B参数的视觉语言模型,在OmniDocBench v1.5基准测试中达到94.5%的准确率,超越了此前所有同类模型。更重要的是,它不是在实验室理想环境下的表现——而是在扫描失真、倾斜、弯曲、屏幕翻拍、光照变化等真实物理干扰场景中的实战能力。
我在测试这个模型时最大的感受是:终于有一个模型能理解现实世界的混乱了。我们日常处理的文档,有多少是完美扫描、平整笔直的?更多是手机拍的发票、倾斜的合同、反光的屏幕截图。PaddleOCR-VL-1.5的设计理念,正是从这些真实需求出发的。
为什么需要关注这个模型?
本节核心问题:在众多文档解析工具中,PaddleOCR-VL-1.5解决了哪些痛点?
传统OCR工具在处理规整文档时表现尚可,但一旦遇到复杂场景就原形毕露。想象这些场景:
-
你用手机拍摄了一份倾斜的合同,需要提取关键条款 -
扫描仪产生的文档有明显的扭曲和阴影 -
需要从屏幕翻拍的照片中识别表格数据 -
古籍文献中的生僻字和特殊符号 -
跨页表格被分割成碎片,难以整合
这些都是我在实际工作中反复遇到的问题。每次都需要手动调整、重新拍照、甚至人工录入。PaddleOCR-VL-1.5的出现,让我看到了一种系统性的解决方案。
五大核心能力突破
1. 极致轻量与极致准确的平衡
0.9B参数意味着什么?这是一个可以在普通GPU甚至某些高端移动设备上运行的模型规模。但它在OmniDocBench v1.5上达到94.5%准确率,在表格、公式、文本识别方面都有显著提升。这种参数效率的实现,源于模型架构的精心设计和训练策略的优化。
我的反思:小模型并不意味着性能妥协。在特定领域深耕,小模型可以超越泛化的大模型。这给了我们一个启示——与其追求通用大模型,不如在垂直场景做到极致。
2. 不规则形状定位能力
传统OCR通常只能做矩形框检测,但真实文档常常是倾斜、弯曲的。PaddleOCR-VL-1.5引入多边形检测能力,能够准确处理扭曲文档条件下的定位问题。这在处理扫描文档、弯曲书页时尤为重要。
实际应用场景:假设你需要数字化一本老旧账簿,书页已经泛黄卷曲。传统工具可能只能识别部分内容,或者需要你费力将书页压平。而PaddleOCR-VL-1.5可以直接处理弯曲的页面,通过多边形定位准确提取每一行文字。
3. 文本定位与识别一体化
模型新增了文本定位功能,不仅能识别文字内容,还能准确标注每个文字区域的位置。这对于需要保留文档布局信息的场景至关重要——比如法律文件分析、版面还原等。
4. 印章识别专项能力
在中文文档处理中,印章识别是一个特殊但重要的需求。合同、证明、公文中的印章不仅是内容的一部分,更是文档有效性的标志。PaddleOCR-VL-1.5专门优化了印章识别能力,并在相关指标上创造了新纪录。
场景示例:企业需要批量处理历史合同,提取关键信息建立数据库。印章的识别和定位可以帮助快速确认文档的法律效力,标记需要人工复核的异常情况。
5. 多语言与特殊场景强化
模型在生僻字、古文、多语言表格、下划线、复选框等特殊元素的识别上都有提升。语言覆盖扩展到了藏文和孟加拉文。这种多样性支持,使得模型可以应对更广泛的实际场景。
我学到的教训:特殊场景的处理能力,才是模型实用性的真正试金石。那些看似边缘的需求,往往是用户的痛点所在。
长文档处理的创新
跨页表格自动合并和跨页段落标题识别,这两个功能解决了长文档解析的核心难题——内容碎片化。
想象你要处理一份100页的研究报告,其中有多个跨页表格和连续的章节。传统工具会将跨页表格分割成独立的部分,段落标题也可能被误识别为普通文本。PaddleOCR-VL-1.5能够理解文档的逻辑结构,自动识别并合并这些内容,大幅减少后期人工整理的工作量。
深入理解模型架构
本节核心问题:PaddleOCR-VL-1.5如何在0.9B参数规模下实现如此强大的能力?
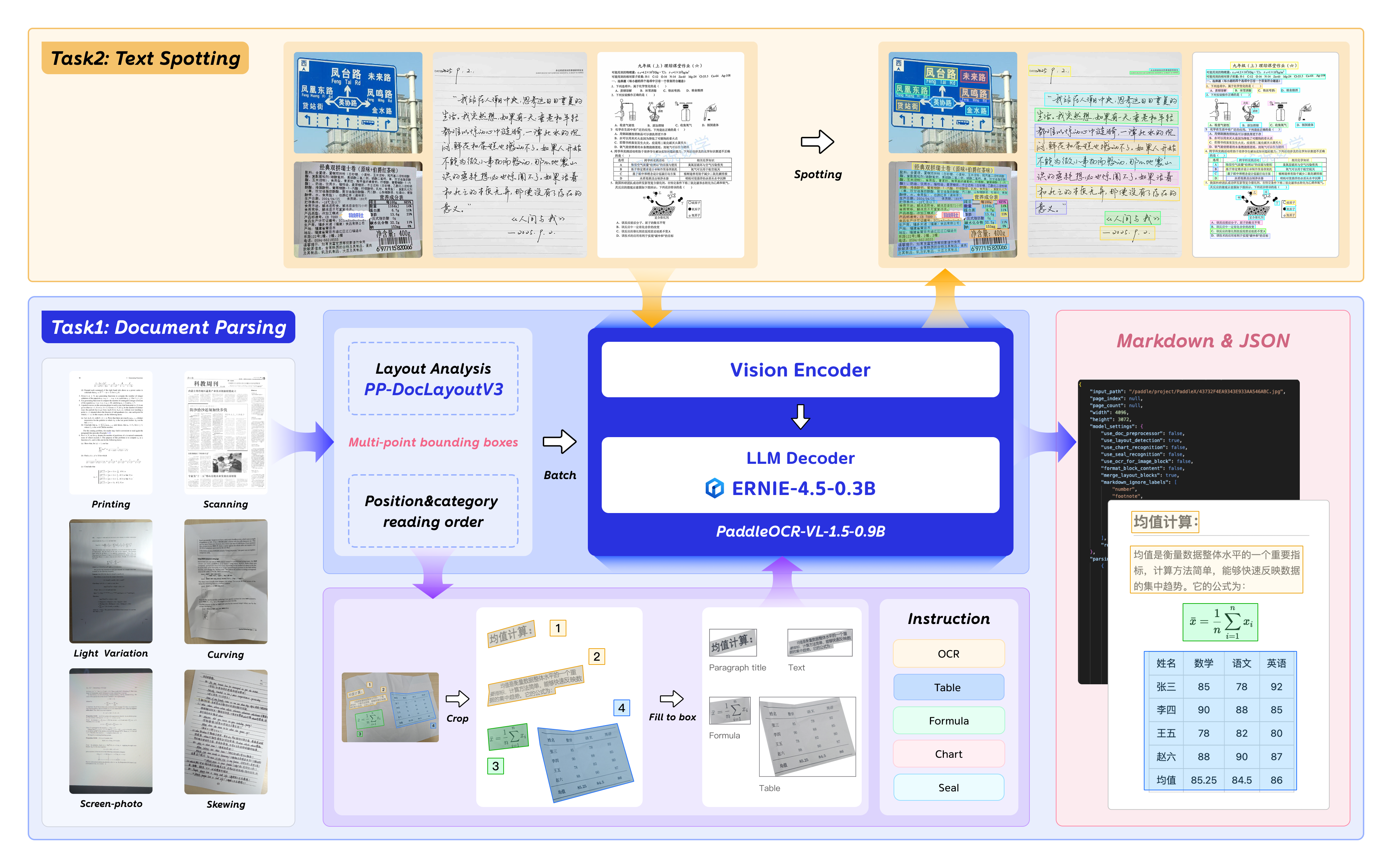
模型采用了视觉-语言多模态架构,这是一种将视觉理解和语言处理能力融合的设计思路。简单来说,模型不仅”看”图像,还能”理解”图像中文字的语义和结构关系。
多任务统一框架
PaddoreOCR-VL-1.5将多个任务统一在一个模型中处理:
-
文本识别(OCR) -
表格识别 -
公式识别 -
图表识别 -
文本定位 -
印章识别
这种统一框架的好处是显而易见的:用户不需要针对不同任务调用不同模型,一个模型搞定所有文档解析需求。从工程实践角度,这大幅降低了部署和维护成本。
独特见解:多任务学习的本质是知识共享。不同任务之间存在内在联系——识别表格需要理解文本,识别公式需要理解符号,这些能力可以相互增强。统一框架让模型在训练时能够利用不同任务间的协同效应。
真实场景性能验证
本节核心问题:PaddleOCR-VL-1.5在实际复杂环境下的表现如何?
为了严格评估模型在真实物理干扰下的鲁棒性,团队构建了Real5-OmniDocBench基准测试,涵盖五种典型场景:
场景一:扫描文档
扫描过程产生的噪点、阴影、色彩失真等问题。测试结果显示,PaddleOCR-VL-1.5在扫描场景下保持了高准确率,显著优于主流开源和专有模型。

场景二:倾斜文档
文档拍摄或扫描时的角度偏差。这是最常见的场景之一——我们用手机拍文档时很难保证完全垂直。模型通过不规则形状定位能力,能够准确处理各种倾斜角度。

场景三:弯曲变形
书页弯曲、文档折叠等物理变形。这在处理书籍、装订材料时尤为常见。模型的多边形检测能力在这个场景下发挥了关键作用。

场景四:屏幕翻拍
从电脑或手机屏幕拍摄产生的摩尔纹、反光、分辨率损失。这个场景在远程办公、在线会议中频繁出现——你需要保存屏幕上的文档但没有原始文件。

场景五:光照变化
不均匀光照、阴影、过曝或欠曝。室外拍摄文档时最容易遇到这种情况。模型需要在各种光照条件下保持稳定的识别能力。

性能对比数据
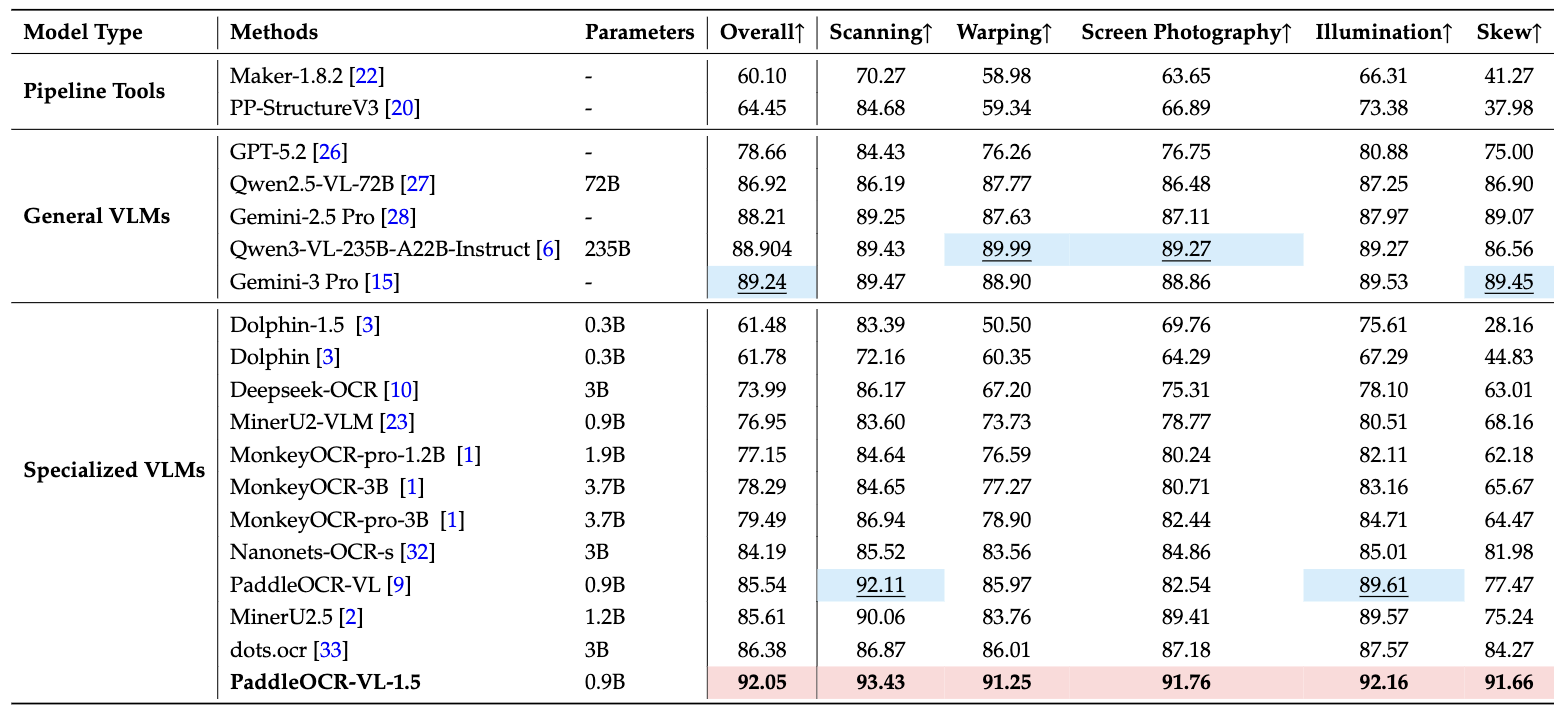
在所有五个场景中,PaddleOCR-VL-1.5都创造了新的性能记录。这不是实验室数据,而是来自真实使用场景的验证。
我的反思:基准测试应该贴近实际使用场景。很多模型在标准数据集上表现优异,但面对真实世界的混乱时就束手无策。Real5-OmniDocBench的构建,本身就是对行业评估标准的一次重要推动。
快速上手指南
本节核心问题:如何在5分钟内开始使用PaddleOCR-VL-1.5?
环境准备
首先安装依赖环境。这里需要注意版本要求:
# 安装CUDA 12.6版本的PaddlePaddle
python -m pip install paddlepaddle-gpu==3.2.1 -i https://www.paddlepaddle.org.cn/packages/stable/cu126/
# 安装PaddleOCR及文档解析模块
python -m pip install -U "paddleocr[doc-parser]"
重要提示:必须安装PaddlePaddle 3.2.1或更高版本。macOS用户需要使用Docker环境。这是因为模型使用了一些特定的框架特性,旧版本可能无法正常运行。
命令行快速体验
最简单的使用方式是命令行:
paddleocr doc_parser -i https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/paddleocr_vl_demo.png
这条命令会自动下载模型(首次使用),处理指定图像,并输出识别结果。你可以替换URL为本地文件路径。
Python API调用
更灵活的方式是使用Python API:
from paddleocr import PaddleOCRVL
# 初始化模型
pipeline = PaddleOCRVL()
# 处理图像
output = pipeline.predict("https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/paddleocr_vl_demo.png")
# 处理结果
for res in output:
res.print() # 打印到控制台
res.save_to_json(save_path="output") # 保存为JSON
res.save_to_markdown(save_path="output") # 保存为Markdown
这段代码展示了完整的处理流程:初始化模型、处理图像、保存结果。结果可以保存为JSON或Markdown格式,方便后续处理或直接阅读。
实际应用场景:假设你需要批量处理发票图像,提取金额、日期等关键信息。你可以将图像路径列表传递给模型,循环处理每张图像,将结果保存为结构化JSON,然后导入数据库或Excel。
性能优化:使用vLLM加速
对于大规模批量处理,可以使用vLLM推理服务器提升性能:
方法一:使用Docker启动服务
docker run \
--rm \
--gpus all \
--network host \
ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlepaddle/paddleocr-genai-vllm-server:latest-nvidia-gpu \
paddleocr genai_server --model_name PaddleOCR-VL-1.5-0.9B --host 0.0.0.0 --port 8080 --backend vllm
方法二:直接使用vLLM
参考vLLM官方文档中的PaddleOCR-VL使用指南。
启动服务后,调用方式只需修改一行配置:
from paddleocr import PaddleOCRVL
# 使用vLLM服务器
pipeline = PaddleOCRVL(
vl_rec_backend="vllm-server",
vl_rec_server_url="http://127.0.0.1:8080/v1"
)
output = pipeline.predict("your_image_path.png")
性能提升有多大?根据官方测试,使用vLLM在A100 GPU上处理OmniDocBench v1.5的512批次PDF文档,端到端推理时间显著降低。这对于需要处理海量文档的企业场景尤为重要。
使用Transformers库进行推理
本节核心问题:如何在Transformers生态中集成PaddleOCR-VL-1.5?
对于熟悉Hugging Face生态的开发者,可以直接使用Transformers库调用模型。需要注意的是,官方推荐使用PaddleOCR的标准方法,因为它更快且支持页面级文档解析。Transformers方式目前仅支持元素级识别和文本定位。
安装依赖
python -m pip install "transformers>=5.0.0"
基础推理代码
from PIL import Image
import torch
from transformers import AutoProcessor, AutoModelForImageTextToText
# 配置参数
model_path = "PaddlePaddle/PaddleOCR-VL-1.5"
image_path = "test.png"
task = "ocr" # 可选: 'ocr' | 'table' | 'chart' | 'formula' | 'spotting' | 'seal'
# 图像预处理(文本定位任务需要特殊处理)
image = Image.open(image_path).convert("RGB")
orig_w, orig_h = image.size
spotting_upscale_threshold = 1500
if task == "spotting" and orig_w < spotting_upscale_threshold and orig_h < spotting_upscale_threshold:
process_w, process_h = orig_w * 2, orig_h * 2
try:
resample_filter = Image.Resampling.LANCZOS
except AttributeError:
resample_filter = Image.LANCZOS
image = image.resize((process_w, process_h), resample_filter)
# 设置最大像素数
max_pixels = 2048 * 28 * 28 if task == "spotting" else 1280 * 28 * 28
# 加载模型
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
model = AutoModelForImageTextToText.from_pretrained(
model_path,
torch_dtype=torch.bfloat16
).to(DEVICE).eval()
processor = AutoProcessor.from_pretrained(model_path)
# 构建提示词
PROMPTS = {
"ocr": "OCR:",
"table": "Table Recognition:",
"formula": "Formula Recognition:",
"chart": "Chart Recognition:",
"spotting": "Spotting:",
"seal": "Seal Recognition:",
}
messages = [
{
"role": "user",
"content": [
{"type": "image", "image": image},
{"type": "text", "text": PROMPTS[task]},
]
}
]
# 推理
inputs = processor.apply_chat_template(
messages,
add_generation_prompt=True,
tokenize=True,
return_dict=True,
return_tensors="pt",
images_kwargs={
"size": {
"shortest_edge": processor.image_processor.min_pixels,
"longest_edge": max_pixels
}
},
).to(model.device)
outputs = model.generate(**inputs, max_new_tokens=512)
result = processor.decode(outputs[0][inputs["input_ids"].shape[-1]:-1])
print(result)
性能优化:使用Flash Attention
对于需要进一步提升速度和降低显存占用的场景,可以启用Flash Attention 2:
pip install flash-attn --no-build-isolation
修改模型加载代码:
model = AutoModelForImageTextToText.from_pretrained(
model_path,
torch_dtype=torch.bfloat16,
attn_implementation="flash_attention_2"
).to(DEVICE).eval()
独特见解:选择推理方式要权衡灵活性和性能。Transformers方式提供了更大的定制空间,适合研究和实验;标准方式则针对生产环境优化,适合实际部署。
专项能力深度解析
本节核心问题:PaddleOCR-VL-1.5在特定任务上的表现如何?
文本定位能力
文本定位不仅识别文字内容,还精确标注位置。这在保留文档布局、版面分析等场景中至关重要。

应用场景示例:
-
电子书排版分析:提取原始书籍的排版信息,用于重新排版或格式转换 -
表单理解:识别表单中各字段的位置关系,自动填充或数据提取 -
广告监控:检测图像中的文字区域,分析广告内容分布
印章识别专长
中文文档处理中,印章是一个特殊但关键的元素。PaddleOCR-VL-1.5在印章识别上创造了新纪录。

实际应用价值:
-
合同审核自动化:批量处理合同时自动识别和验证印章 -
文档真实性检测:通过印章识别辅助判断文档有效性 -
档案数字化:历史档案中的印章识别和记录
我学到的教训:垂直领域的细节优化,往往能创造不可替代的价值。印章识别看似小众,但在法律、金融、政务等领域是刚需。
表格识别精度
表格是文档中最复杂的结构之一。PaddleOCR-VL-1.5在表格识别准确率上有显著提升,尤其是多语言表格、复杂嵌套表格。
性能数据:在OmniDocBench v1.5的表格识别任务上,模型达到了SOTA水平。
场景应用:
-
财务报表数字化:自动提取财务报表中的数字数据 -
科研文献处理:提取论文中的实验数据表格 -
多语言报告处理:处理包含中英文混合的复杂表格
公式识别能力
数学公式和科学符号的识别是另一个技术难点。模型在公式识别上的准确率提升,使其可以应用于学术文献处理。
应用方向:
-
教材数字化:将纸质教材转换为可编辑的电子版 -
论文检索:从PDF论文中提取公式,建立可搜索的公式库 -
在线教育:自动识别学生上传的手写公式作业
性能指标全景分析
本节核心问题:PaddleOCR-VL-1.5相比其他模型的优势在哪里?
OmniDocBench v1.5基准测试
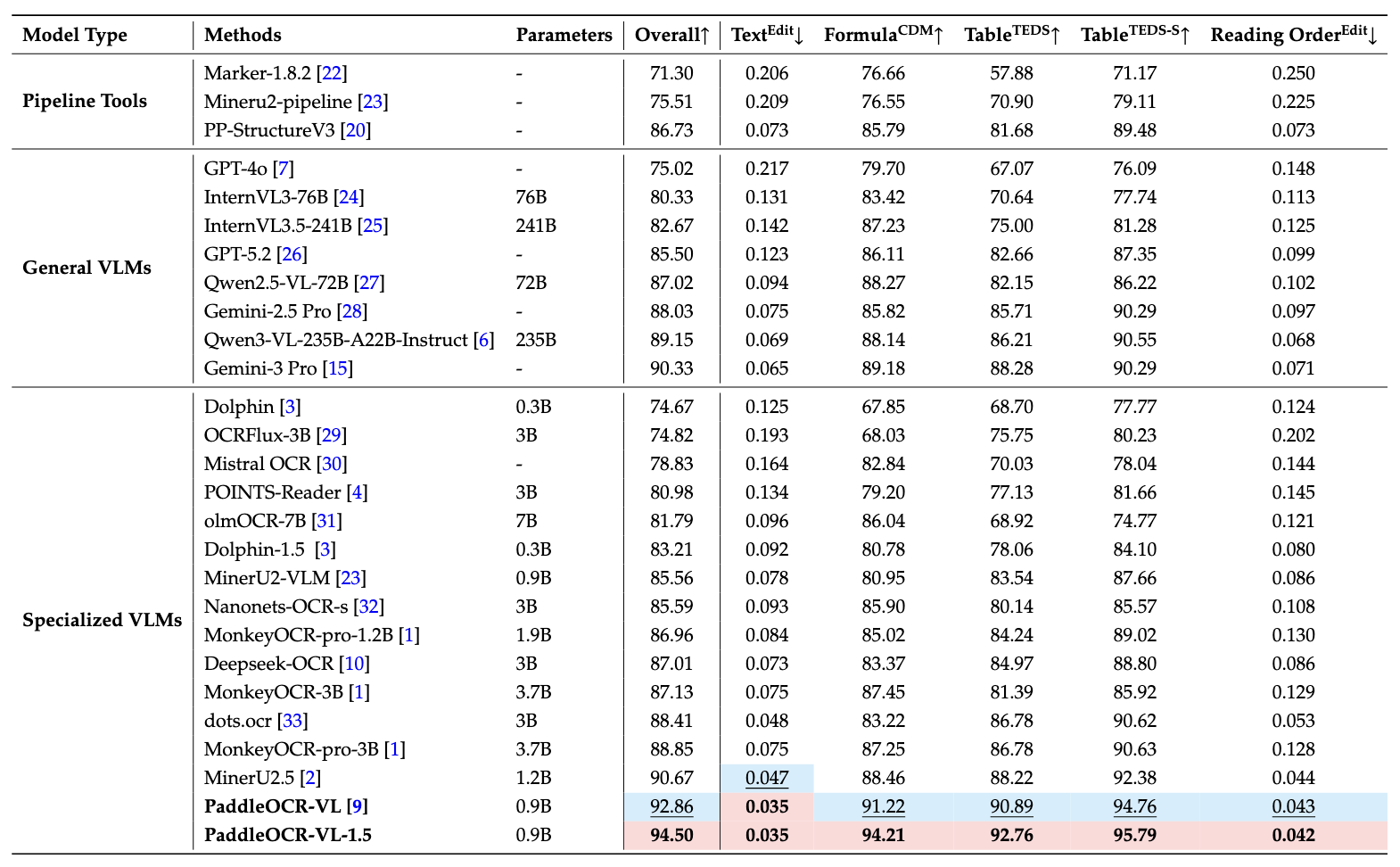
在OmniDocBench v1.5上,PaddleOCR-VL-1.5在整体准确率、文本识别、公式识别、表格识别、阅读顺序等核心指标上都达到了SOTA水平。
需要说明的是,除了Gemini-3 Pro、Qwen3-VL-235B-A22B-Instruct和PaddleOCR-VL-1.5是独立评估外,其他模型的性能数据引用自OmniDocBench官方排行榜。
Real5-OmniDocBench真实场景测试
这是一个全新的基准测试,专门针对真实世界的物理干扰场景构建。数据集基于OmniDocBench v1.5,但增加了扫描、弯曲、屏幕翻拍、光照变化、倾斜五种典型场景的样本。
测试结果显示,PaddleOCR-VL-1.5在所有五个场景中都保持了最高准确率。这证明了模型不仅在理想条件下表现优异,在复杂真实环境中同样可靠。
我的反思:真实世界的鲁棒性是模型走向实用的关键。很多研究模型在实验室表现惊艳,但一旦部署到生产环境就问题频出。PaddleOCR-VL-1.5从设计之初就考虑了真实场景的复杂性。
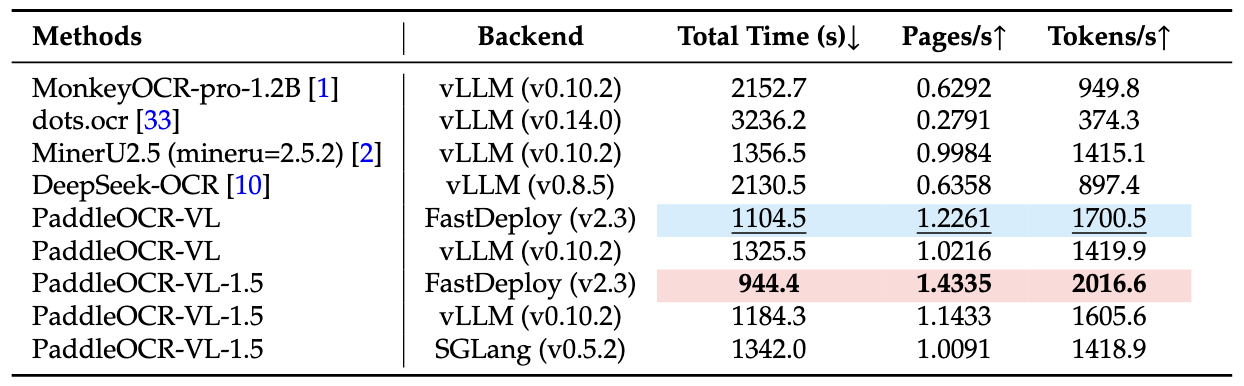
推理性能表现
在A100 GPU上处理OmniDocBench v1.5的512批次PDF文档,PaddleOCR-VL-1.5的端到端推理时间包含了PDF渲染和Markdown生成的完整流程。所有方法都使用各自内置的PDF解析模块和默认DPI设置,反映开箱即用的性能。
性能优势不仅体现在准确率上,还体现在处理速度上。这对于需要处理大量文档的企业场景至关重要——时间就是成本。
实际部署建议
本节核心问题:如何在生产环境中高效部署PaddleOCR-VL-1.5?
硬件选择
根据不同规模的需求选择合适的硬件:
小规模部署(日处理<1000页)
-
CPU: 8核以上 -
内存: 16GB+ -
GPU: 可选(GTX 1660或以上)
中等规模部署(日处理1000-10000页)
-
CPU: 16核以上 -
内存: 32GB+ -
GPU: RTX 3090或A4000
大规模部署(日处理>10000页)
-
CPU: 32核以上 -
内存: 64GB+ -
GPU: A100或多卡部署 -
推荐使用vLLM服务器
性能调优要点
-
批处理优化:对于批量文档,合理设置batch size可以显著提升吞吐量 -
图像预处理:对于高分辨率图像,可以适当降采样以加快处理速度 -
任务并行:使用多进程或多线程处理独立的文档任务 -
结果缓存:对于重复处理的文档,实现结果缓存机制
质量保障策略
-
置信度阈值:设置识别结果的置信度阈值,低于阈值的结果标记为需要人工审核 -
关键字段验证:对于关键业务字段,增加格式验证和合理性检查 -
抽样复核:定期抽取部分结果进行人工复核,评估模型表现 -
异常监控:监控处理失败率、平均耗时等指标,及时发现异常
独特见解:生产部署不是一次性工作,而是持续优化的过程。建立完善的监控和反馈机制,根据实际使用情况不断调整配置和策略。
技术演进的启示
本节核心问题:从PaddleOCR-VL到PaddleOCR-VL-1.5的演进说明了什么?
PaddleOCR-VL-1.5是PaddleOCR-VL的下一代版本。从版本演进中,我看到了几个重要趋势:
从通用到场景化
早期模型追求通用性,能处理各种文档就算成功。但实际应用中,通用往往意味着平庸。PaddleOCR-VL-1.5的设计思路是在保持广泛适用性的同时,针对真实场景做深度优化。
Real5-OmniDocBench的构建本身就说明了这一点——我们需要的不是在标准数据集上刷分的模型,而是能应对真实世界混乱的工具。
从大而全到小而精
在大模型盛行的时代,PaddleOCR-VL-1.5坚持0.9B参数规模,这是一种勇气。它证明了在垂直领域,精心设计的小模型可以超越泛化的大模型。
这给了我们一个重要启示:不是所有问题都需要百亿级参数来解决。找准问题域,深入优化,小模型也能创造大价值。
从单点突破到系统能力
PaddleOCR-VL-1.5不是仅仅在某个指标上提升,而是构建了一套完整的文档理解能力体系:文本识别、表格理解、公式处理、定位能力、印章识别、多语言支持、长文档处理。
这种系统性思维是模型走向实用的关键。单一能力的突破往往无法解决实际问题,只有形成完整的能力闭环,才能真正落地应用。
实用工作流程建议
本节核心问题:如何在实际项目中高效使用PaddleOCR-VL-1.5?
文档批量处理流程
import os
from paddleocr import PaddleOCRVL
from pathlib import Path
def batch_process_documents(input_dir, output_dir, task_type="ocr"):
"""
批量处理文档的示例流程
Args:
input_dir: 输入文档目录
output_dir: 输出结果目录
task_type: 任务类型(ocr/table/formula等)
"""
# 初始化模型
pipeline = PaddleOCRVL()
# 确保输出目录存在
Path(output_dir).mkdir(parents=True, exist_ok=True)
# 支持的文件格式
supported_formats = ['.png', '.jpg', '.jpeg', '.pdf']
# 遍历输入目录
for filename in os.listdir(input_dir):
file_path = os.path.join(input_dir, filename)
# 检查文件格式
if not any(filename.lower().endswith(fmt) for fmt in supported_formats):
continue
try:
# 处理文档
print(f"Processing: {filename}")
output = pipeline.predict(file_path)
# 保存结果
for res in output:
base_name = os.path.splitext(filename)[0]
res.save_to_json(save_path=os.path.join(output_dir, f"{base_name}.json"))
res.save_to_markdown(save_path=os.path.join(output_dir, f"{base_name}.md"))
print(f"Completed: {filename}")
except Exception as e:
print(f"Error processing {filename}: {str(e)}")
continue
# 使用示例
batch_process_documents("./input_docs", "./output_results")
结果验证与后处理
识别结果往往需要进一步验证和处理:
import json
def validate_and_clean_results(json_path):
"""
验证和清理识别结果的示例
"""
with open(json_path, 'r', encoding='utf-8') as f:
data = json.load(f)
# 示例:提取文本内容并验证
text_content = data.get('text', '')
# 移除多余空白
text_content = ' '.join(text_content.split())
# 特定格式验证(根据实际需求)
# 例如:验证日期格式、金额格式等
return text_content
# 使用示例
cleaned_text = validate_and_clean_results("./output_results/document.json")
常见问题解答
问题1:模型支持哪些图像格式?
支持常见的图像格式包括PNG、JPG、JPEG,以及PDF文档。对于PDF,会自动进行渲染处理。
问题2:处理速度如何?单张图像需要多长时间?
处理速度取决于硬件配置和图像复杂度。在A100 GPU上,单张普通文档图像处理时间通常在1-3秒。使用vLLM服务器可以显著提升批量处理速度。
问题3:如何处理多页PDF文档?
直接传入PDF文件路径即可,模型会自动处理多页内容,并支持跨页表格合并和段落识别。
问题4:识别准确率不理想时如何优化?
首先检查图像质量,确保清晰度足够。对于倾斜或弯曲的图像,模型已经有优化,但极端情况下可以尝试预处理。如果是特定领域的专业术语,可以考虑使用自定义词典(如果后续版本支持)。
问题5:可以在CPU上运行吗?性能如何?
可以在CPU上运行,但速度会明显慢于GPU。对于小规模、非实时处理的场景,CPU也是可行的选择。
问题6:模型支持哪些语言?
支持中文、英文以及藏文、孟加拉文等多种语言。对于多语言混合文档也有较好的处理能力。
问题7:如何集成到现有系统?
提供了命令行工具、Python API、以及Transformers接口多种方式。可以根据现有系统的技术栈选择最适合的集成方式。vLLM服务器方式适合微服务架构。
问题8:模型大小和硬件要求是什么?
模型参数规模为0.9B,相对轻量。推荐至少16GB内存,GPU显存8GB以上。可以在普通工作站或云服务器上运行。
实用操作清单
为了帮助快速上手,这里提供一个完整的操作清单:
环境配置清单
-
[ ] 安装PaddlePaddle 3.2.1或更高版本 -
[ ] 安装PaddleOCR文档解析模块 -
[ ] (可选)安装vLLM用于加速推理 -
[ ] (可选)安装Flash Attention用于优化 -
[ ] 验证GPU驱动和CUDA版本兼容性
基础功能测试清单
-
[ ] 运行命令行示例验证安装 -
[ ] 测试Python API基础调用 -
[ ] 测试不同任务类型(OCR、表格、公式等) -
[ ] 测试批量处理功能 -
[ ] 测试结果保存和导出
生产部署清单
-
[ ] 评估处理规模和硬件需求 -
[ ] 选择合适的部署方式(标准/vLLM) -
[ ] 配置性能监控 -
[ ] 建立质量验证流程 -
[ ] 制定异常处理策略 -
[ ] 准备降级方案
持续优化清单
-
[ ] 定期评估识别准确率 -
[ ] 收集边界案例和失败样本 -
[ ] 监控处理性能指标 -
[ ] 优化批处理参数 -
[ ] 更新模型版本(当有新版本时)
一页速览
PaddleOCR-VL-1.5核心要点:
模型特点
-
0.9B参数轻量级模型 -
OmniDocBench v1.5准确率94.5% -
支持真实场景物理干扰处理 -
统一框架支持多种文档理解任务
核心能力
-
不规则形状定位 -
文本定位与识别 -
表格、公式、图表识别 -
印章识别 -
多语言支持 -
跨页内容处理
快速开始
pip install paddlepaddle-gpu==3.2.1
pip install -U "paddleocr[doc-parser]"
paddleocr doc_parser -i image.png
适用场景
-
文档数字化 -
合同自动审核 -
发票批量处理 -
学术文献提取 -
档案管理 -
表单识别
性能优化
-
使用vLLM加速批量处理 -
启用Flash Attention降低显存 -
合理设置batch size -
图像预处理优化
关键提示
-
需要PaddlePaddle 3.2.1+ -
macOS用户使用Docker -
生产部署建议GPU加速 -
建立质量监控机制
总结
PaddleOCR-VL-1.5代表了文档解析技术的一次重要进步。它不是简单的性能提升,而是从真实需求出发,系统性地解决了文档处理中的关键问题。
0.9B的参数规模证明了垂直领域不需要盲目追求大模型。针对性的优化、真实场景的验证、完整的能力体系,这些才是实用工具的关键。
从我的使用经验来看,这个模型最大的价值在于可靠性。它能够稳定处理各种复杂场景,减少了人工干预的需求。这对于需要批量处理文档的企业来说,意味着实实在在的效率提升和成本节约。
如果你正在寻找一个可靠的文档解析方案,PaddleOCR-VL-1.5值得尝试。它不是万能的,但在它覆盖的场景中,已经达到了行业领先水平。更重要的是,它是开源的,你可以自由地使用、测试、甚至根据需求进行定制。
技术的进步不是一蹴而就的,而是在不断解决实际问题中逐步实现的。PaddleOCR-VL-1.5的发布,为文档智能处理领域带来了新的可能性。期待看到更多基于这个模型的创新应用。
文中图片来源:PaddlePaddle官方GitHub仓库
