Qwen-Image-Edit: The No-Fluff Guide to AI-Powered Image Editing for Everyone
Table of Contents
-
What Exactly Is Qwen-Image-Edit? -
Installation in Three Commands -
Your First Edit: 5 Minutes From Zero to Image -
Six Real-World Use Cases—Prompts Included -
Pro Tips: Chain Editing Like a Designer -
Performance Snapshot: Why It’s Called SOTA -
Quick Reference: Parameters & Defaults -
Frequently Asked Questions -
Citation & License
What Exactly Is Qwen-Image-Edit?
Think of Qwen-Image-Edit as a bilingual photo assistant that understands both pictures and words. It is built on the 20-billion-parameter Qwen-Image model and adds two extra skills:
| Core Skill | Plain-English Meaning | What You Can Do |
|---|---|---|
| Semantic Editing | Understand the meaning of the scene | Rotate objects, change art styles, create new character poses |
| Appearance Editing | Keep everything else pixel-perfect | Add a signboard, remove stray hair, recolor one letter |
| Precise Text Editing | Read and rewrite Chinese & English text inside images | Fix typos on posters without the original PSD file |
Installation in Three Commands
The pipeline is already packaged inside Hugging Face’s diffusers library.
Tested on Ubuntu 22.04 + Python 3.10; Windows and macOS work the same way.
# 1. Make sure you have CUDA 11.8+
nvidia-smi
# 2. Install the latest diffusers
pip install --upgrade "git+https://github.com/huggingface/diffusers"
# 3. No step three—the ModelScope loader will pull the 20 B model automatically.
Hardware note:
-
GPU VRAM: at least 12 GB in FP16, 10 GB in BF16. -
No CPU mode: inference would be too slow for practical use.
Your First Edit: 5 Minutes From Zero to Image
Goal
Change a white rabbit to purple fur and add a flash-light background.
Files Needed
-
rabbit.jpg(any RGB image)
Code
from PIL import Image
import torch
from modelscope import QwenImageEditPipeline
# Load once, reuse often
pipe = QwenImageEditPipeline.from_pretrained("Qwen/Qwen-Image-Edit")
pipe = pipe.to("cuda", torch.bfloat16)
# Load your image
image = Image.open("rabbit.jpg").convert("RGB")
# Describe the change in plain English
prompt = "Change the rabbit's color to purple, with a flash light background."
# Run
with torch.inference_mode():
edited = pipe(
image=image,
prompt=prompt,
true_cfg_scale=4.0,
num_inference_steps=50,
generator=torch.manual_seed(42)
).images[0]
edited.save("purple_rabbit.jpg")
Open purple_rabbit.jpg—only the rabbit and background have changed; the rest of the pixels are untouched.
Six Real-World Use Cases—Prompts Included
Below are exact prompts you can copy-paste. The left column links to the official demo so you can see the before-and-after.
| Use Case | Source Image | Prompt | What Happens |
|---|---|---|---|
| 1. Mascot Pose Swap | 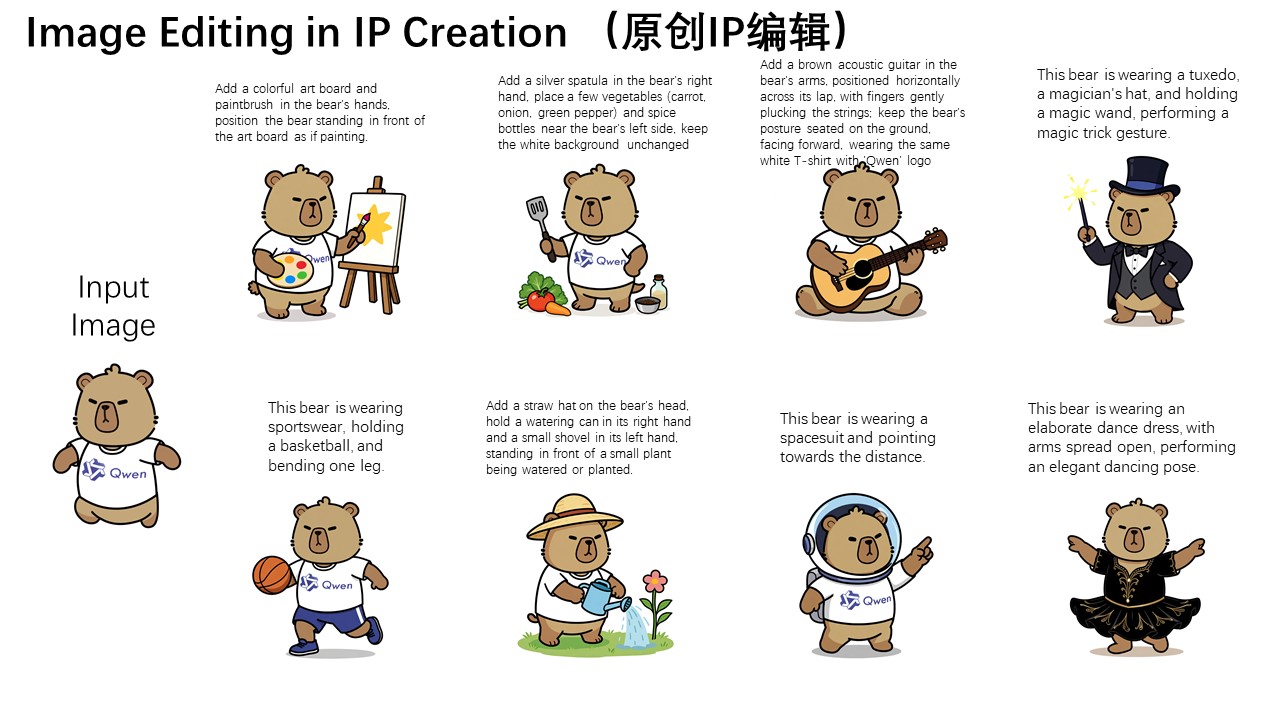 |
"Show the capybara in a thinking pose while keeping the character consistent" |
Same character, new posture |
| 2. MBTI Emoji Pack | Same as above | "INTJ version of the capybara, cool blue tone" |
Generate 16 personality emojis from one base |
| 3. 90° Object Rotation |  |
"Rotate the camera 90° to display its side port" |
You see the previously hidden side |
| 4. Studio Ghibli Style |  |
"Convert the portrait to Studio Ghibli style, soft pastel colors" |
Photorealistic → hand-drawn anime |
| 5. Add a Shop Sign |  |
"Insert a wooden coffee shop sign on the blank wall" |
Sign + realistic reflection |
| 6. Fix Typos in Posters |  |
"Replace 'Hello' with 'Hi', keep the same font" |
New text, identical style |
Pro Tips: Chain Editing Like a Designer
Sometimes one pass is not enough. The official calligraphy example shows how to iterate:
Step-by-Step Chain Edit
| Step | Action | Prompt |
|---|---|---|
| 1 | Draw a red bounding box around the wrong character | "Correct the character inside the red box to 稽" |
| 2 | Model writes the bottom-right part as “日”; draw a smaller red box on that component | "Change the 日 component to 旨" |
| 3 | Repeat until all characters are correct | — |
Why it works:
-
Each edit is local, so VRAM stays low. -
You can review after every step instead of starting over.
Performance Snapshot: Why It’s Called SOTA
Numbers from the official technical report:
| Metric | Improvement over Baseline | Plain-English Meaning |
|---|---|---|
| Structure Preservation | ↑ 9 % | Edited objects still fit the scene naturally |
| Text Accuracy | ↑ 15 % | Fewer garbled characters after edit |
| Human Preference | 74 % win rate | Users prefer Qwen-Image-Edit 3-to-1 |
Quick Reference: Parameters & Defaults
| Parameter | Default | What It Does |
|---|---|---|
true_cfg_scale |
4.0 | How strictly the model follows your prompt (3–5 is safe) |
num_inference_steps |
50 | Quality vs. speed trade-off (30–50 is a good balance) |
negative_prompt |
" " |
Anything you don’t want in the picture, e.g., "blurry, low-res" |
generator |
None |
Pass a seed for reproducible results |
Frequently Asked Questions
-
How is Qwen-Image-Edit different from Stable Diffusion?
Stable Diffusion excels at generating images from scratch. Qwen-Image-Edit is tuned for editing existing images while keeping everything else identical. -
Minimum VRAM?
12 GB in FP16; 10 GB in BF16. -
Commercial use allowed?
Yes, Apache 2.0 license. Keep the license file in your distribution. -
Does it understand Chinese prompts?
Fully bilingual—Chinese and English work equally well. -
Can I edit only a small region?
Yes. Use bounding boxes as shown in the calligraphy example. -
How to reproduce the same result?
Passgenerator=torch.manual_seed(your_number). -
Best
true_cfg_scalerange?
3–5. Below 3, changes are too weak; above 5, artifacts appear. -
Batch processing?
Wrap the pipeline call in a simple Python loop. Each image is processed independently. -
CPU inference possible?
Technically yes, but a single 512×512 edit can take minutes—impractical. -
Watermark?
None. The model outputs clean images.
Citation & License
If this guide helps your project, please cite the original technical report:
@misc{wu2025qwenimagetechnicalreport,
title={Qwen-Image Technical Report},
author={Chenfei Wu and Jiahao Li and Jingren Zhou and Junyang Lin and Kaiyuan Gao and Kun Yan and Sheng-ming Yin and Shuai Bai and Xiao Xu and Yilei Chen and Yuxiang Chen and Zecheng Tang and Zekai Zhang and Zhengyi Wang and An Yang and Bowen Yu and Chen Cheng and Dayiheng Liu and Deqing Li and Hang Zhang and Hao Meng and Hu Wei and Jingyuan Ni and Kai Chen and Kuan Cao and Liang Peng and Lin Qu and Minggang Wu and Peng Wang and Shuting Yu and Tingkun Wen and Wensen Feng and Xiaoxiao Xu and Yi Wang and Yichang Zhang and Yongqiang Zhu and Yujia Wu and Yuxuan Cai and Zenan Liu},
year={2025},
eprint={2508.02324},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2508.02324},
}
License: Apache 2.0 — free for commercial and non-commercial use.
