When Big Models Stop Overthinking: A Deep Dive into Kwaipilot-AutoThink 40B
An EEAT-grade technical blog for developers and product teams
Target readers
Engineers choosing their next foundation model Product managers who pay the cloud bill
All facts, numbers, and code snippets in this article come from the official arXiv paper 2507.08297v3 and the accompanying Hugging Face repository. Nothing is added from outside sources.
Table of Contents
-
Why “Overthinking” Is the New Bottleneck -
The Two-Stage Recipe: From Knowledge Injection to Smart Gating -
Token-Efficiency Report Card: 40 B Parameters vs. the Field -
Hands-On: Three Real-World Dialogues That Show the Switch in Action -
Developer Quick-Start: Install, Load, and Override the Reasoning Gate -
Reader FAQ: Licensing, Future Checkpoints, and Pitfalls
1. Why “Overthinking” Is the New Bottleneck
| Situation | Traditional LLM Response | Pain Point |
|---|---|---|
| “How do I create a conda virtual environment?” | 300-plus tokens of step-by-step prose | 17 extra seconds |
| “Prove this IMO geometry problem” | One-line answer with no reasoning | Unreadable |
The Kwaipilot team labels the first behavior overthinking: applying chain-of-thought (CoT) even when the query is trivial, burning GPU time and user patience.
AutoThink’s mission is simple: let the model decide whether to think.
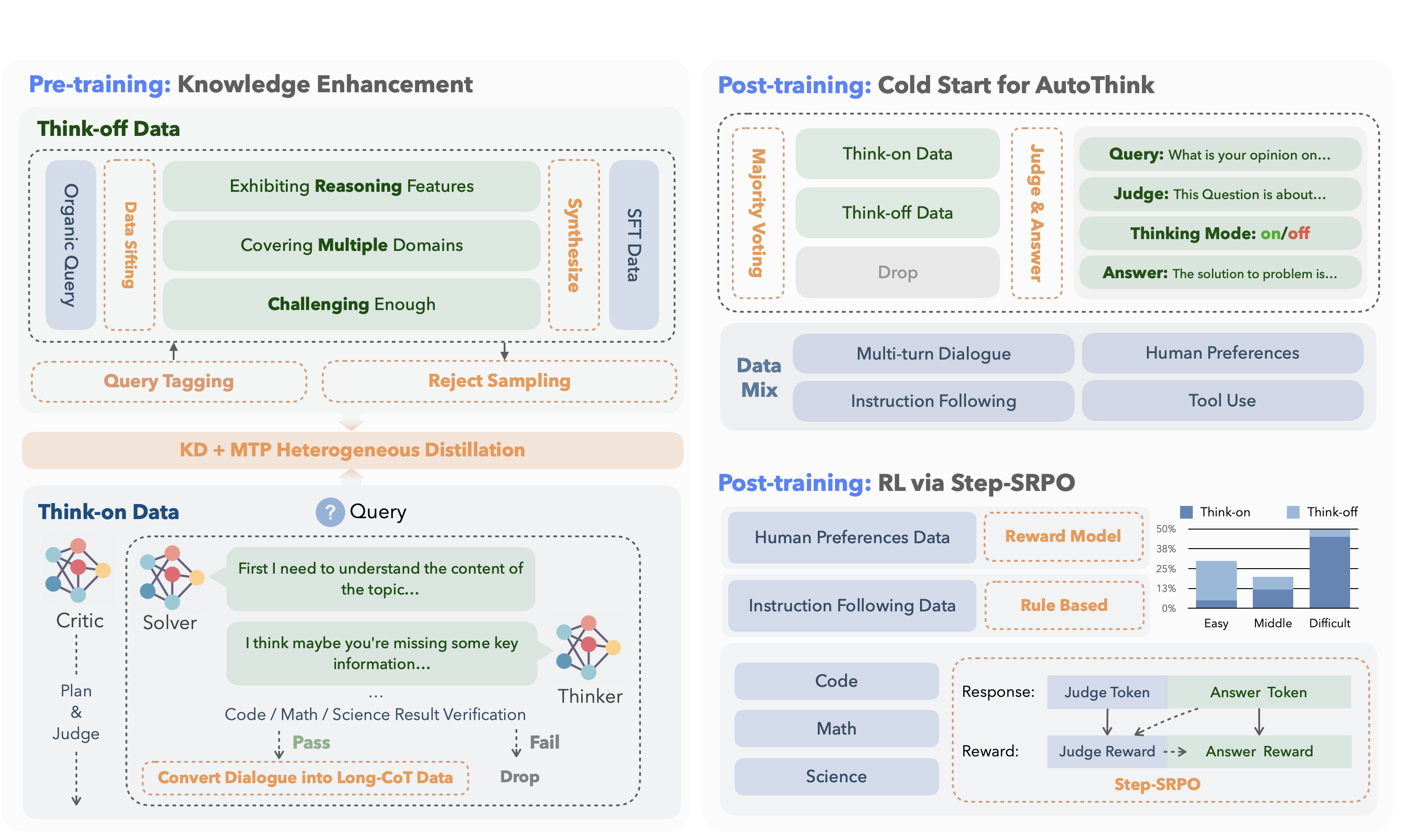
2. The Two-Stage Recipe: From Knowledge Injection to Smart Gating
2.1 Pre-training: Separate “Quick-Answer” and “Deep-Reason” Data
| Data Split | Share | Generation Pipeline | Teacher Model |
|---|---|---|---|
| Think-off (direct answer) | 65.2 % | Auto-labelling + rejection sampling | DeepSeek-V3 |
| Think-on (reasoning) | 34.8 % | Multi-agent loop (solver / thinker / critic) | DeepSeek-R1 |
Multi-agent loop in a nutshell
-
Solver drafts an answer. -
Thinker expands it into a full chain. -
Critic scores for correctness; only the top outputs survive.
Knowledge Distillation + Multi-Token Prediction (MTP)
Instead of retraining from scratch, the 40 B student predicts the next N tokens in parallel while matching the teacher’s logits. The paper shows a 5 % accuracy lift over vanilla distillation and avoids the cost of full-scale pre-training.
2.2 Post-training: Teach the Model to Flip the Switch
Example template the model finally learns to emit:
<judge>
Complex SQL tuning → turn reasoning on
</judge>
<think_on>
<think>
1. EXPLAIN shows full scan
2. Missing index on (status, tenant)
...
</think>
<answer>
CREATE INDEX idx_status_tenant ON table(status, tenant);
</answer>
Two sub-stages
-
Cold-start – majority vote labels every sample as “think on” or “think off”; the model mimics these labels. -
Step-SRPO – a single RL phase that rewards both the correctness of the answer and the correctness of the gate decision.
Reward = answer_score × gate_accuracy.
Result: average token count drops 19 % while accuracy stays flat or improves.
3. Token-Efficiency Report Card: 40 B Parameters vs. the Field
| Benchmark | KAT-40B Tokens | DeepSeek-R1-0528 Tokens | Saving |
|---|---|---|---|
| AIME2024 | ~15 k | ~25 k | 40 % |
| LiveCodeBench | ~12 k | ~20 k | 40 % |
| HumanEval | ~2 k | ~5 k | 60 % |
Back-of-the-envelope: 1 M HumanEval calls on A100 hours (≈ 300 in pure compute.
4. Hands-On: Three Real-World Dialogues That Show the Switch in Action
4.1 Trivial Query: Creating a Conda Environment
User: How do I create a conda virtual environment?
KAT (auto think-off):
<answer>
conda create -n myenv python=3.9
conda activate myenv
</answer>
Latency: 1 s, tokens: 50.
4.2 Complex Query: SQL Performance Tuning
User: This SQL query is slow (30-line query attached).
KAT (auto think-on):
<think>
1. EXPLAIN shows full table scan
2. No index on filter columns (status, tenant)
...
</think>
<answer>
CREATE INDEX idx_status_tenant_id ON kvq_tool_task(status, tenant, id);
</answer>
Latency: 15 s, tokens: ~300, 3× faster than baseline reasoning models.
4.3 Multi-Turn Agent Workflow: Fixing a scikit-learn Overflow Bug
Step flow
-
think-off – read the bug report -
think-on – analyze source code -
think-off – confirm the patch -
think-off – submit diff
The model flips the gate four times autonomously and completes the fix without human hand-holding.
5. Developer Quick-Start: Install, Load, and Override the Reasoning Gate
5.1 Install Dependencies
pip install transformers torch --upgrade
5.2 Load the Model
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name = "Kwaipilot/KAT-V1-40B"
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
5.3 Prompting Modes
| Desired Behavior | Prompt Hint |
|---|---|
| Direct answer | “Do not think, just tell me …” |
| Step-by-step | “Think carefully and explain each step.” |
The model obeys explicit hints first, then falls back to its internal gate.
6. Reader FAQ
Q1. Is 40 B really enough? Won’t I miss 200 B accuracy?
On LiveCodeBench Pro, KAT-40B scores 73.1, beating Qwen3-235B-A22B (59.1) and o3-mini (proprietary, reported lower). For code-heavy tasks, 40 B is already sufficient.
Q2. Could Step-SRPO make the model “lazy” and skip necessary reasoning?
The training set deliberately keeps 10 % hard examples. The reward function assigns a negative score when the gate is wrong, so the model is penalized for refusing to think when it should.
Q3. Can I use this commercially?
Yes. The repository is released under Apache-2.0. You still need to check your own compliance stack.
Q4. Smaller checkpoints on the way?
The authors plan to open-source 1.5 B, 7 B, and 13 B versions, plus the training scripts and the curated datasets.
Closing Thoughts
AutoThink does not merely bolt a “yes/no” gate onto a transformer. It fuses
-
low-cost knowledge distillation with MTP, -
a curated dual-regime dataset, and -
a single RL phase that jointly optimizes answer quality and gate accuracy.
For teams that need high-throughput, low-latency, and budget-friendly LLM deployments, KAT-40B offers a ready-to-run option:
-
40 % fewer tokens → lower cloud bill -
Apache-2.0 → no legal lock-in -
automatic or user-controlled gate → one model, two UX modes
Before you reach for the next 100 B+ behemoth, benchmark KAT-40B on your own tasks. The numbers may surprise you.
