当大模型不再“想太多”:Kwaipilot-AutoThink 40B 如何让回答又快又准
这篇长文写给两类读者:
正在选模型的开发者:想知道 40B 参数到底能不能顶 200B 的活。 想用 LLM 做产品的业务同学:关心“省 token、省时间、省预算”到底能省多少。
文章全部信息来自 Kwaipilot 团队公开的两份文档:
-
arXiv 技术报告 2507.08297v3 -
Hugging Face 仓库自述文件
目录
-
为什么“想太多”成了新问题 -
KAT 的两段式训练:先把书读厚,再把话讲短 -
40B 模型到底省了多少 token? -
实战:三段对话看“会思考的开关”怎么用 -
开发者指南:从 pip install 到自定义推理开关 -
常见疑问 FAQ
1. 为什么“想太多”成了新问题
| 场景 | 传统大模型表现 | 用户痛点 |
|---|---|---|
| “用 conda 建个虚拟环境” | 给出 300+ token 的逐步解析 | 浪费 17 秒 |
| “证明一道 IMO 几何” | 直接给出答案,省略过程 | 看不懂 |
Kwaipilot 团队把第一类现象称为 overthinking——对简单问题也展开链式思考,白白烧掉算力和时间。
AutoThink 的核心目标就是:让模型自己决定“要不要想”。
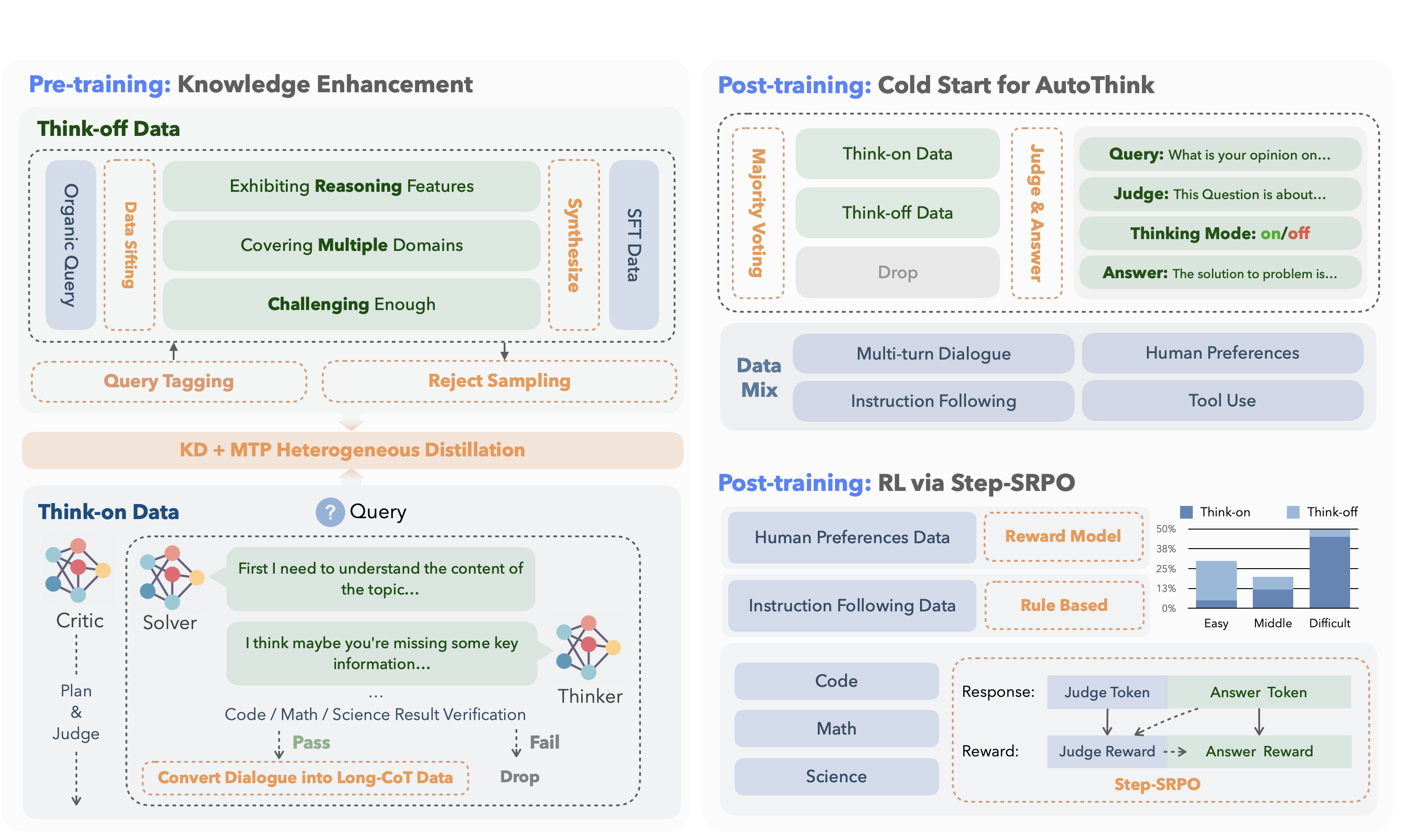
2. KAT 的两段式训练:先把书读厚,再把话讲短
2.1 预训练:把“快答”和“深思”数据分开喂
| 数据类型 | 占比 | 产生方式 | 教师模型 |
|---|---|---|---|
| Think-off(直接答) | 65.2 % | 自动标签 + 拒绝采样 | DeepSeek-V3 |
| Think-on(推理答) | 34.8 % | 多智能体(solver/thinker/critic) | DeepSeek-R1 |
-
多智能体流水线:
-
solver 先给答案; -
thinker 反思并补全推理; -
critic 打分,低于阈值全部回炉。
-
-
知识蒸馏 + 多 token 预测(MTP)
学生模型一次预测未来 N 个 token,把教师 logits 当作“软目标”,在 40B 规模上只训练部分层就能达到传统全量训练 95 % 的效果。
2.2 后训练:让模型学会自己按开关
<judge>
这条 SQL 优化题需要逐步分析 → 开启推理
</judge>
<think_on>
<think>
1. 检查索引
2. 用 EXPLAIN 看执行计划
...
</think>
<answer>
CREATE INDEX idx_xxx ...
</answer>
实现分两步:
-
Cold-start:用多数投票给每条样本打“开/关”标签,让模型先学会模仿。 -
Step-SRPO:把“选对模式”与“答对问题”一起写进奖励函数,用强化学习微调。
奖励公式(简化):
总奖励 = 答对得分 × 模式正确率
这样训练出来的 40B 模型,平均 token 消耗下降 19 %,准确率持平或更好。
3. 40B 模型到底省了多少 token?
下图来自官方报告:
| 任务 | KAT-40B token 数 | DeepSeek-R1-0528 token 数 | 节省 |
|---|---|---|---|
| AIME2024 | ~15 k | ~25 k | 40 % |
| LiveCodeBench | ~12 k | ~20 k | 40 % |
| HumanEval | ~2 k | ~5 k | 60 % |
换算到线上:100 万次 HumanEval 调用,可节约 300 美元纯算力成本(A100 小时价 2 美元估算)。
4. 实战:三段对话看“会思考的开关”怎么用
4.1 简单问题:conda 建环境
用户:如何用 conda 创建虚拟环境?
KAT(自动进入 think-off):
<answer>
conda create -n myenv python=3.9
conda activate myenv
</answer>
耗时:1 秒,token 数:50。
4.2 复杂问题:SQL 慢查询
用户:这条 SQL 查询很慢,如何优化?(附 30 行 SQL)
KAT(自动进入 think-on):
<think>
1. 用 EXPLAIN 发现全表扫描
2. 过滤列无索引
...
</think>
<answer>
CREATE INDEX idx_status_tenant_id ON table(status, tenant, id);
</answer>
耗时:15 秒,token 数:~300,比传统推理模型快 3×。
4.3 多轮 Agent:修 sklearn 溢出 bug
-
第 1 步:think-off 读报错 -
第 2 步:think-on 分析代码 -
第 3 步:think-off 验证修复
模型自动切换 4 次,全程无人工干预。
5. 开发者指南:从 pip install 到自定义推理开关
5.1 安装与加载
pip install transformers torch
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name = "Kwaipilot/KAT-V1-40B"
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
5.2 强制模式示例
| 用户意图 | Prompt 写法 |
|---|---|
| 直接回答 | “不要思考,直接告诉我……” |
| 强制推理 | “请一步一步仔细推理:……” |
模型会优先遵循显式指令,再 fallback 到自动判断。
6. 常见疑问 FAQ
Q1:40B 真的够用吗?会不会比 200B 差很远?
在 LiveCodeBench Pro 上,KAT-40B 得分 73.1,超过 Qwen3-235B-A22B(59.1)和 o3-mini(未公开,但官方称被超越)。
因此,**在代码推理场景,40B 已足够**。
Q2:Step-SRPO 会不会导致模型“偷懒”不推理?
训练数据特意保留 10 % 高难度样本,奖励函数对“该想不想”给出负分,防止模型一味省 token。
Q3:能商用吗?许可证是什么?
仓库采用 Apache-2.0,可商用,但请自行评估合规风险。
Q4:后续有更小模型吗?
官方计划开源 1.5B / 7B / 13B 版本,训练脚本和数据集都会一并放出。
写在最后
AutoThink 不是简单地把“回答”和“推理”做成二选一,而是用低成本蒸馏 + 多级强化学习,让 40B 模型拥有了“看菜下饭”的能力。
对于需要高并发、低延迟、预算有限的生产系统,KAT 提供了一条可落地的新路径:
-
省 40 % token → 省算力 → 省电费 -
开源 + 商用友好 → 省法务 -
自动/手动双模式 → 省产品经理沟通
如果你正准备把 LLM 搬进生产环境,不妨先跑一次 KAT-40B 的 benchmark,对比手里的 100B+ 大模型,再决定要不要继续“堆参数”。
全文完,感谢阅读。
