Title: Gemma 3 QAT Models: How to Run State-of-the-Art AI on Consumer GPUs

The computational demands of large AI models have long been a barrier for developers. With the release of Google’s Gemma 3 Quantization-Aware Trained (QAT) models, this paradigm is shifting—consumer-grade GPUs can now efficiently run even the 27B parameter version of this cutting-edge AI. This article explores the technology behind this breakthrough, its advantages, and practical implementation strategies.
Why Quantization Matters for AI Accessibility
1.1 From H100 to RTX 3090: Democratizing Hardware
Traditional large models like Gemma 27B required 54GB of VRAM (using BF16 precision), necessitating high-end GPUs like the NVIDIA H100. Quantization slashes this requirement to 14.1GB (int4), enabling consumer GPUs like the RTX 3090 to handle the workload. This shift unlocks:
-
Cost Efficiency: Hardware costs drop from tens of thousands to under $1,000 -
Broader Access: Individual developers and small teams gain access to enterprise-level tools -
New Use Cases: Deployment on laptops, mobile devices, and edge hardware
1.2 The Science of Quantization
Quantization compresses models by reducing numerical precision, similar to converting a high-resolution image to a vector format:
| Precision | Bits | VRAM Usage | Example Hardware |
|---|---|---|---|
| BF16 | 16 | 54GB | NVIDIA H100 |
| int8 | 8 | 27GB | NVIDIA A100 |
| int4 | 4 | 14.1GB | NVIDIA RTX 3090 |
Gemma 3’s Quantization Breakthrough
2.1 Quantization-Aware Training (QAT) Explained
Unlike post-training quantization, QAT integrates low-precision simulations during training:
-
Phased Optimization: Introduces quantization in the final 5,000 training steps -
Target Alignment: Uses outputs from the full-precision model as training targets -
Loss Mitigation: Reduces perplexity drop by 54% (evaluated via llama.cpp)
2.2 Real-World Performance
Human evaluations on Chatbot Arena (Elo scores) show minimal performance degradation:
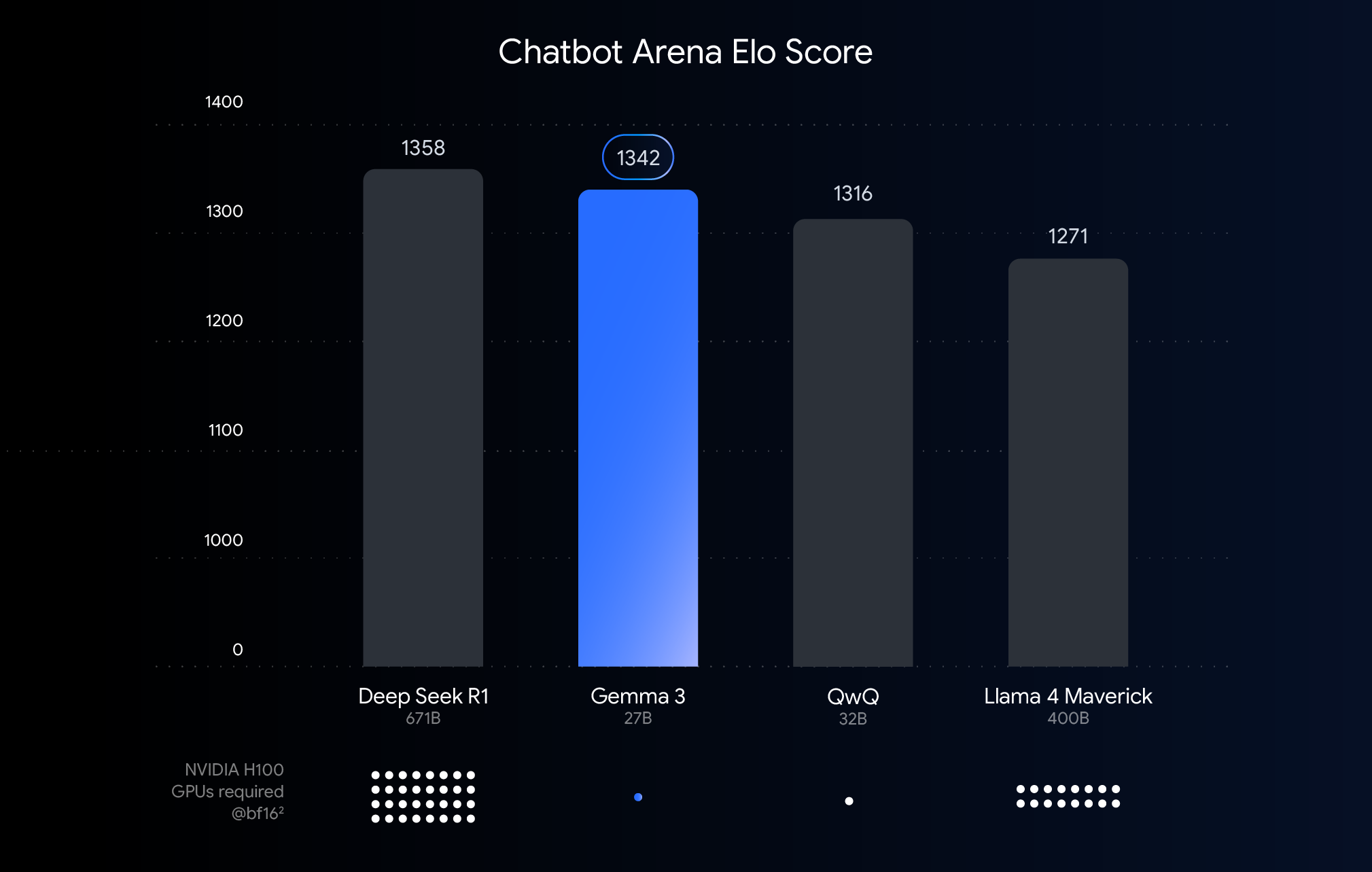
-
27B Model: Retains 98.5% of original performance -
12B Model: Achieves real-time responses on RTX 4060 laptops -
4B Model: 3x faster inference on embedded devices
Step-by-Step Deployment Guide
3.1 Hardware Compatibility Matrix
Match model size to your hardware:
| Model | Precision | VRAM Needed | Compatible Devices |
|---|---|---|---|
| Gemma 27B | int4 | 14.1GB | RTX 3090/4090 |
| Gemma 12B | int4 | 6.6GB | RTX 4060 Laptop GPU |
| Gemma 4B | int4 | 2.6GB | High-end Android phones |
| Gemma 1B | int4 | 0.5GB | Raspberry Pi 5 |
3.2 Tools for Every Platform
Desktop Solutions
-
Ollama: Launch with one command: ollama run gemma3:27b-q4 -
LM Studio: Manage models via a graphical interface -
llama.cpp: Optimized CPU inference
Mobile & Edge Deployment
-
MLX: Native acceleration for Apple M-series chips -
Google AI Edge: Android-compatible quantization
Cloud Integration
-
Hugging Face: Direct API access -
Kaggle: Free GPU resources for prototyping
Technical Deep Dive
4.1 Managing KV Cache Overhead
Beyond model weights, running LLMs requires memory for context (KV cache):
-
Calculation: Memory = 2 × layers × heads × dim × seq_len × bytes -
Optimization: Dynamic batching + context window limits -
Example: Gemma 27B needs +8GB VRAM for 2048-token contexts
4.2 Choosing Quantization Formats
Tailor formats to your use case:
| Format | Strength | Ideal For |
|---|---|---|
| Q4_0 | Speed/accuracy balance | General inference |
| Q5_K_M | Higher precision | Creative tasks |
| Q3_K_L | Extreme compression | Embedded systems |
Community-Driven Innovations
5.1 Third-Party Quantization Options
Beyond Google’s QAT, explore community PTQ solutions:
| Provider | Technique | Use Case |
|---|---|---|
| Bartowski | Mixed-precision量化 | Long-text generation |
| Unsloth | Memory optimization | Multi-task workflows |
| GGML | Hardware-level tuning | Legacy hardware |
5.2 Fine-Tuning Quantized Models
-
Data Strategy: Use outputs from the original model as training labels -
Learning Rate: Apply cosine annealing (start at 1e-5) -
Evaluation: Monitor both perplexity and human feedback
Industry Impact & Future Trends
6.1 Transforming Development Workflows
-
Prototyping: Weeks → hours -
Cost Reduction: 90% lower entry barrier for startups -
Privacy Compliance: Local processing for healthcare/finance data
6.2 Emerging Applications
-
Personal AI Assistants: Local ChatGPT-like systems -
Industrial IoT: Real-time defect detection on factory floors -
Education: AI tutors on decade-old computers
Getting Started
7.1 Quick Implementation Checklist
-
Visit Hugging Face Models -
Select a quantized version matching your hardware -
Load via Ollama/LM Studio -
Test using APIs or a web interface
7.2 Learning Resources
-
Quantization Whitepaper -
Kaggle Performance Benchmarks -
Community tutorials on Gemmaverse
The Democratization of AI
Gemma 3’s quantization isn’t just a technical upgrade—it’s a paradigm shift. By enabling 27B-parameter models to run on gaming GPUs, Google has leveled the playing field between individual developers and tech giants. This quiet revolution is redefining what’s possible in AI, one consumer-grade GPU at a time.
