复杂任务拆解、透明执行、结果可靠,这个开源框架正在重新定义AI代理的开发体验
作为一名长期蹲守在前沿AI技术领域的开发者,我见证了太多“下一个突破性框架”的崛起与沉寂。但当Sentient AI发布ROMA时,我不得不承认——这次有些不同。
还记得那些让人又爱又恨的AI代理开发经历吗?单个任务处理得漂漂亮亮,一旦遇到需要多步推理的复杂问题,系统就会像失去导航的航船,在错误的海洋中打转。直到ROMA的出现,我们终于有了一把打开长视界任务大门的钥匙。
为什么你的AI代理总是在复杂任务上“翻车”?
想象一下:你要求AI代理分析两个城市的气候差异并生成报告。单看每个步骤——搜索数据、提取信息、对比分析、撰写报告——现代大语言模型都能做得不错。但当你把这些步骤串联起来,结果往往令人失望。
问题不在于模型能力,而在于系统架构。
即使是99%可靠的单步处理,串联10步后整体成功率就会骤降到90%以下。更糟的是,传统代理框架像一个个黑盒,当最终结果出错时,你几乎无法定位问题究竟出在哪个环节。
这就是ROMA要解决的核心痛点:长视界任务中的错误累积和调试困难。
ROMA的架构革命:递归任务树的智慧
ROMA的全称是Recursive Open Meta-Agent,这个名字精准地概括了它的核心创新——递归开放的元代理框架。
四阶段控制循环:Atomize → Plan → Execute → Aggregate
ROMA的每个任务节点都遵循着同一套简洁而强大的决策逻辑:
def solve(task):
if is_atomic(task): # 步骤1:原子化判断
return execute(task) # 步骤2:执行原子任务
else:
subtasks = plan(task) # 步骤2:规划分解
results = []
for subtask in subtasks:
results.append(solve(subtask)) # 递归调用
return aggregate(results) # 步骤3:聚合结果
这个看似简单的循环背后,隐藏着解决复杂问题的深层智慧。让我用一个具体例子来说明:
假设你要求ROMA回答“制作预算超过3.5亿美元却未能成为当年票房冠军的电影有哪些?”
Atomizer(原子化器) 首先判断这个任务过于复杂,无法一步完成。
Planner(规划器) 接着将任务分解为:
-
查找预算超过3.5亿美元的电影清单 -
获取相关年份的票房冠军信息 -
对比分析得出最终名单
Executor(执行器) 然后分别执行每个子任务——可能是调用搜索API、查询数据库或使用专业工具。
Aggregator(聚合器) 最后将各个结果整合成连贯的答案。

真正的巧妙之处在于,每个子任务本身也可能经历相同的分解过程,形成一颗真正的任务树。这种递归设计让ROMA能够处理任意复杂度的任务,同时保持代码的简洁性。
信息流设计:透明如玻璃的上下文传递
与传统代理框架最大的不同在于,ROMA让信息流动变得完全透明。任务分解时,上下文自上而下传递;结果聚合时,数据自下而上流动。更重要的是,依赖关系得到严格尊重——需要前序结果的任务会耐心等待,独立任务则并行执行。
这种设计带来的直接好处是可调试性。开发者在任何时刻都能准确知道:
-
当前正在执行什么任务 -
任务的输入是什么 -
得到了什么输出 -
问题出在哪个具体环节
实战表现:用基准测试说话
再优美的架构设计,也需要用实际性能来证明自己。Sentient团队用ROMA构建了一个搜索代理——ROMA Search,并在多个权威基准上进行了测试。
SEAL-0基准:多源推理的终极挑战
SEAL-0专门设计来考验系统处理冲突、噪声信息的能力。在这个堪称“地狱难度”的测试中,ROMA Search交出了令人瞩目的成绩单:
45.6%的准确率,显著超越Kimi Researcher(36%)和Gemini 2.5 Pro(19.8%),成为当前该基准的最先进系统。

FRAMES和SimpleQA:全面领先
在测试多步推理的FRAMES基准上,ROMA Search同样实现了最先进性能。而在事实检索任务SimpleQA上,也达到了接近最先进的水平。
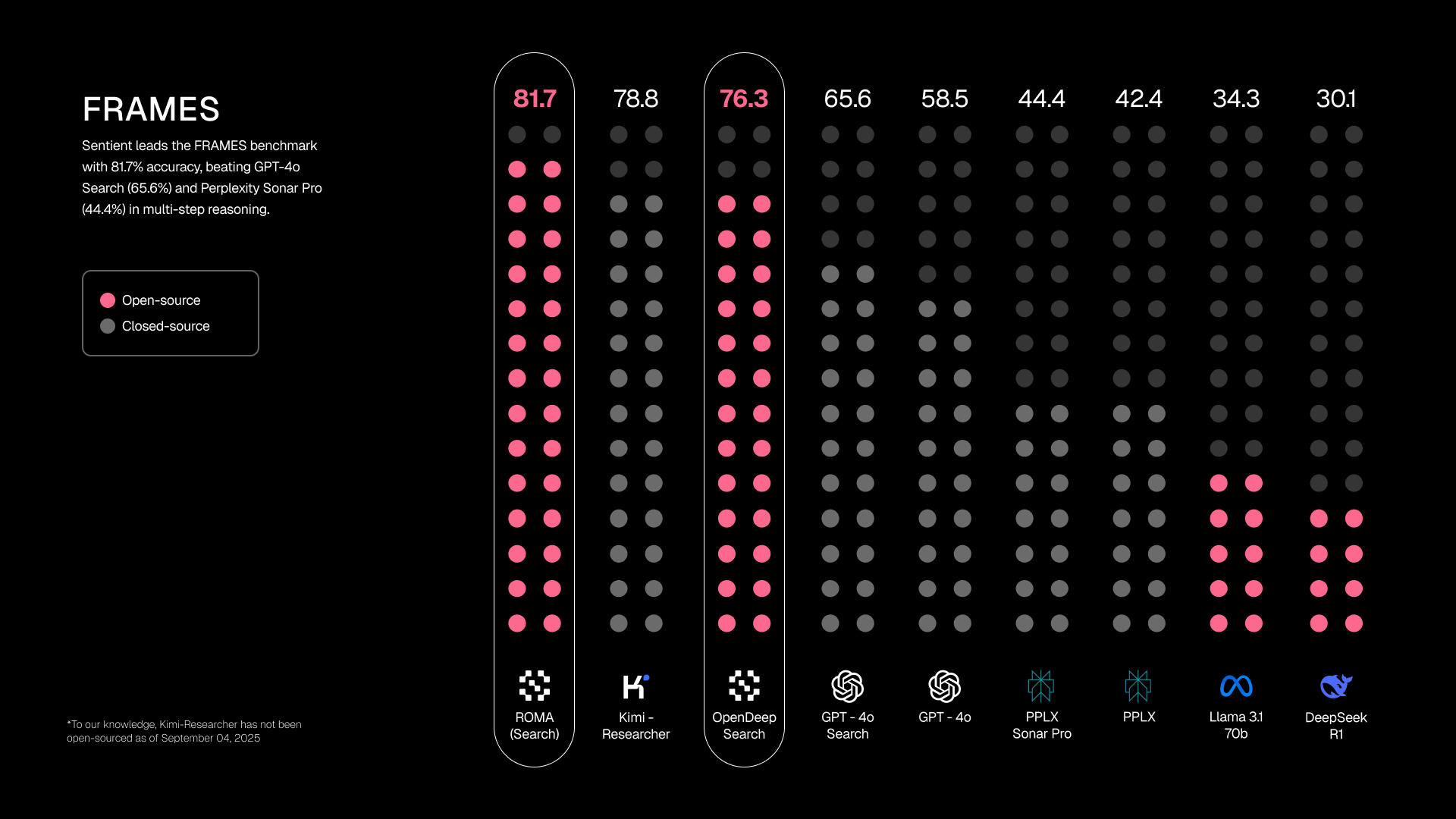
这些结果证明,ROMA的架构优势能够转化为实实在在的性能提升,特别是在需要复杂推理和多方验证的任务上。
五分钟上手:从零搭建你的第一个ROMA代理
理论说再多,不如亲手试一试。ROMA的入门体验堪称惊艳——只需要5分钟,你就能拥有一个全功能的代理系统。
一步到位的环境搭建
git clone https://github.com/sentient-agi/ROMA.git
cd ROMA
./setup.sh
这个简单的命令背后,ROMA为你提供了两种选择:
-
Docker部署(推荐):完整的隔离环境,避免依赖冲突 -
原生安装:更适合开发和定制
无论选择哪种方式,你都将在几分钟内获得一个包含前端界面(localhost:3000)和后端服务(localhost:5000)的完整系统。
预构建代理:开箱即用的强大能力
ROMA贴心地提供了多个预构建代理,让你立即体验框架的强大:
通用任务求解器基于ChatGPT搜索预览,能够处理从技术问题到创意项目的各种任务。这是我个人最喜欢的起点,因为它让你立即感受到ROMA在多步推理上的流畅体验。
深度研究代理专门为复杂研究任务优化,自动将研究问题分解为搜索、分析和合成阶段,并行处理多个信息源,最终生成结构完整的研究报告。
加密分析代理则展示了ROMA在专业领域的应用,集成实时市场数据、链上分析和DeFi指标,为加密货币研究提供深度洞察。
你的第一个自定义代理
创建自定义代理的简单程度可能会让你惊讶:
from sentientresearchagent import SentientAgent
agent = SentientAgent.create()
result = await agent.run("为我创建一个关于AI安全的播客大纲")
这三行代码背后,ROMA正在执行完整的任务分解、规划、执行和聚合流程。你可以通过前端界面实时观察整个执行过程,见证复杂任务如何被一步步解决。
高级特性:为生产环境而生
ROMA不仅仅是一个研究框架,它从一开始就考虑了生产环境的需求。
E2B沙盒集成:安全执行不受信任代码
对于需要代码执行的任务,ROMA提供了与E2B沙盒的无缝集成:
./setup.sh --e2b # 配置E2B模板
./setup.sh --test-e2b # 测试集成效果
这种集成带来了关键优势:
-
🔒 安全隔离:不可信代码在沙盒中运行 -
☁️ 数据同步:自动与S3环境同步数据 -
🚀 高性能访问:通过goofys实现S3文件系统挂载
企业级数据管理
ROMA的数据持久层设计同样令人印象深刻:
-
S3挂载:支持企业级S3存储 -
路径注入防护:全面的安全验证机制 -
凭证安全:AWS凭证在操作前验证 -
动态Docker编排:安全的卷挂载策略
这些特性让ROMA能够满足企业级应用的安全和可靠性要求。
开源生态:与社区共同进化
在技术领域,最令人兴奋的莫过于看到一个项目既解决了实际问题,又构建了健康的生态系统。ROMA采用Apache 2.0许可证,完全开放源代码,鼓励社区参与和贡献。
项目的模块化设计意味着你可以:
-
轻松替换组件: swapping不同的LLM提供商、工具或执行环境 -
扩展新功能:基于清晰的接口添加自定义能力 -
共享改进:社区共同推动框架进化
这种开放性确保了ROMA不会像某些封闭系统那样停滞不前,而是能够随着整个AI社区一起快速进化。
常见问题解答
Q:ROMA与AutoGPT、LangChain等框架有何不同?
A:ROMA的核心差异在于其递归任务树架构和完全透明的执行流程。虽然其他框架也支持任务分解,但ROMA通过统一的四阶段循环和结构化I/O,提供了无与伦比的可调试性和控制力。
Q:ROMA对计算资源的要求高吗?
A:得益于并行执行独立任务的能力,ROMA实际上能够更高效地利用计算资源。对于简单任务,资源消耗与单次模型调用相当;对于复杂任务,并行化反而可以减少总体响应时间。
Q:是否支持本地模型?
A:完全支持。通过LiteLLM集成,ROMA可以连接任何提供兼容API的模型,包括本地部署的Ollama、vLLM等实例。
Q:ROMA适合什么类型的应用场景?
A:特别适合需要多步推理、信息整合和复杂决策的场景,如:深度研究、财务分析、内容创作、数据分析和技术评估等。
Q:生产环境部署的复杂性如何?
A:ROMA提供了Docker化部署和清晰的配置指南,大大降低了生产部署难度。安全特性如沙盒执行和凭证管理也经过了精心设计,满足企业级需求。
未来展望:递归代理的新时代
ROMA的出现标志着AI代理开发的一个转折点。它证明,通过恰当的架构设计,我们完全能够构建出可靠处理复杂任务的AI系统。
但更重要的是,ROMA为整个社区提供了一个共同进化的基础。正如Linux为操作系统发展奠定了基石,ROMA有可能成为智能代理领域的类似基础。
我特别期待看到社区基于ROMA构建的各种创新应用——从科学研究助手到创意合作伴侣,从商业分析工具到教育辅导系统。可能性只受限于我们的想象力。
现在,钥匙已经在你手中。是时候打开那扇通往可靠AI代理世界的大门,探索长视界任务的无限可能了。
准备好开始你的ROMA之旅了吗?访问GitHub仓库获取源代码,加入Discord社区与其他开发者交流,或者阅读技术博客深入了解架构细节。下一个突破性的AI应用,也许就源自你的灵感。
