在开发AI系统时,为LLM代理提供合适的工具可以大大提升它们处理真实任务的能力。这些工具不像传统的软件函数那样固定,而是需要适应代理的非确定性行为。今天,我们来聊聊如何设计和优化这些工具,让它们真正发挥作用。如果你是一个开发者,正试图让你的AI代理更聪明,这篇文章会一步步带你走完整个过程。
想象一下,你在构建一个AI系统,它需要处理像调度会议或分析日志这样的复杂任务。代理可能会调用工具来获取天气信息,或者直接从知识库中推理答案。但有时,它可能会出错,比如误解工具的使用方式。这就是为什么我们需要重新思考工具的设计——不是为其他软件写的,而是专为代理量身定制。
什么是工具?为什么它对LLM代理如此重要?
你可能会问:“工具到底是什么?它和普通的函数有什么区别?”简单来说,在计算中,工具是连接确定性系统和非确定性代理的桥梁。传统的函数如getWeather(“NYC”)每次输入相同,总会输出相同的纽约天气。但代理不同,它面对“今天要带伞吗?”这样的问题时,可能先问位置、调用工具,或者甚至凭记忆回答。有时,它还会出错或幻觉。
工具的目标是扩大代理能有效解决任务的范围,让它们采用多种策略。我们的经验是,对代理“友好”的工具,往往对人类也直观易懂。这意味着,在设计时,我们要考虑代理的局限性,比如上下文长度有限,不能一次性处理太多信息。
如何开始编写工具:从原型到评估
如果你刚起步,别急着写一大堆工具。先建一个快速原型,测试一下代理怎么用它。下面我一步步解释过程。
构建原型
你可能在想:“怎么快速建一个工具原型?”首先,用Claude Code这样的代理来帮忙写工具。如果你用的是外部库或API,给它提供文档——比如llms.txt格式的API文档。
然后,把工具包装成本地MCP服务器或Desktop扩展。这样,你就能在Claude Code或Claude Desktop app中连接和测试。
步骤如下:
-
运行命令连接本地MCP服务器到Claude Code:
claude mcp add <name> <command> [args...]。 -
在Claude Desktop app中,导航到Settings > Developer或Settings > Extensions来连接。
-
或者,直接把工具传入Anthropic API调用,进行程序化测试。
测试时,自己试用工具,找出问题。收集用户反馈,了解预期用例和提示。这能帮你直观感受到哪些工具代理喜欢用,哪些不。
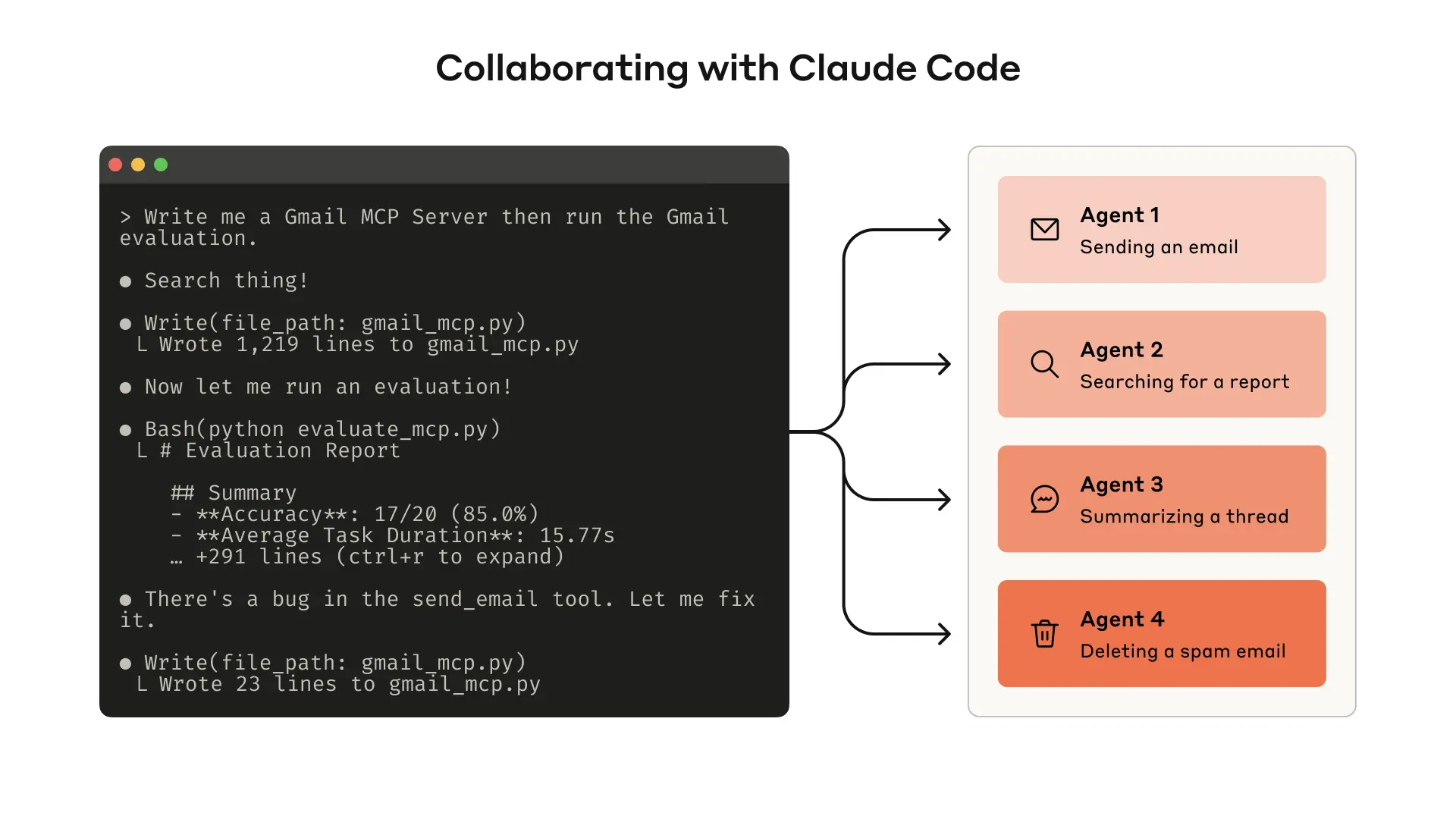
构建评估能系统测量工具性能。你可以用Claude Code自动优化工具。
运行评估
原型建好后,你需要量化代理用工具的表现。怎么做?运行一个全面评估。
首先,生成评估任务。这些任务要基于真实世界用例,用真实数据源和服务。避免简单沙盒环境,要让任务复杂,可能需要多次工具调用。
强任务示例:
-
✦ 下周和Jane安排会议讨论Acme Corp项目。附上上次项目规划会议笔记,并预订会议室。
-
✦ 客户ID 9182报告单次购买被扣三次款。找出所有相关日志,检查其他客户是否受影响。
-
✦ 客户Sarah Chen提交取消请求。准备留存优惠。确定:(1) 他们为什么离开,(2) 最吸引人的优惠,(3) 提供优惠前的风险因素。
弱任务示例(避免这些,因为太简单):
-
✦ 下周和jane@acme.corp安排会议。
-
✦ 搜索支付日志中的
purchase_complete和customer_id=9182。 -
✦ 找客户ID 45892的取消请求。
每个任务配一个可验证响应。验证器可以是简单字符串比较,或用Claude判断。避免太严格的验证器,它可能会因为格式或标点拒绝正确答案。
可选:指定预期工具调用,但别过度,因为任务有多种解决路径。
运行评估时,用简单代理循环:while循环包裹LLM API和工具调用。每个任务一个循环,给代理单一任务提示和你的工具。
在系统提示中,让代理输出推理和反馈块,再输出工具调用和响应。这能触发链式思考,提高智能。
如果你用Claude,开interleaved thinking功能,能类似地探查代理为什么调用或不调用某些工具。
收集指标:准确率、工具调用运行时间、调用次数、令牌消耗、工具错误。这些能揭示常见工作流,帮你合并工具。
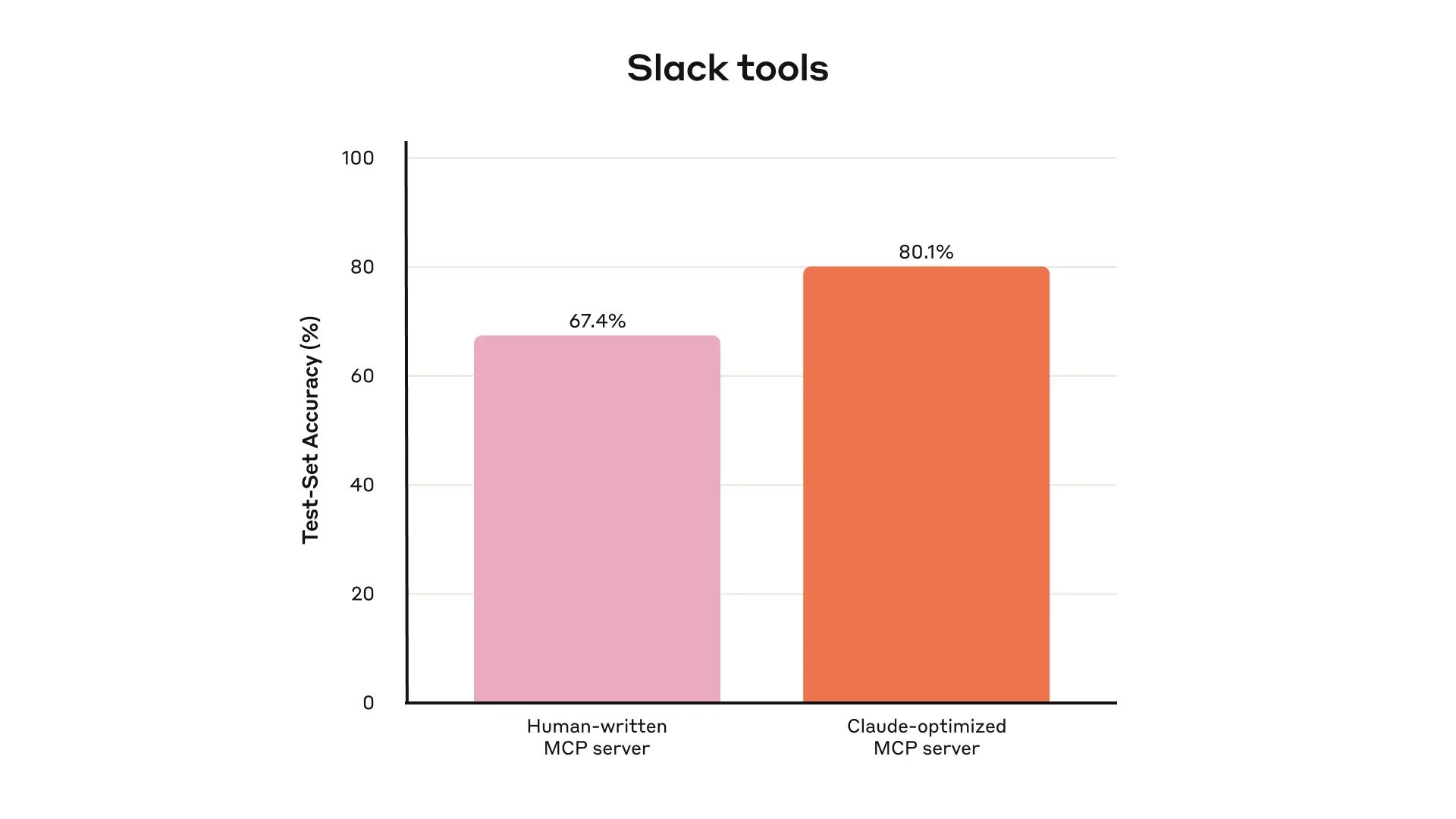
这是内部Slack工具的留出测试集性能。
分析结果时,让代理帮忙。它们能发现工具描述矛盾、实现低效或模式困惑。但注意,代理反馈可能遗漏关键点。
观察代理卡住的地方,读推理和反馈,审原始转录。分析工具调用指标:多余调用可能需调整分页;参数错误可能需更好描述。
例如,Claude的web search工具推出时,我们发现它多加“2025”到query参数,偏置结果。我们通过改进描述修复了。
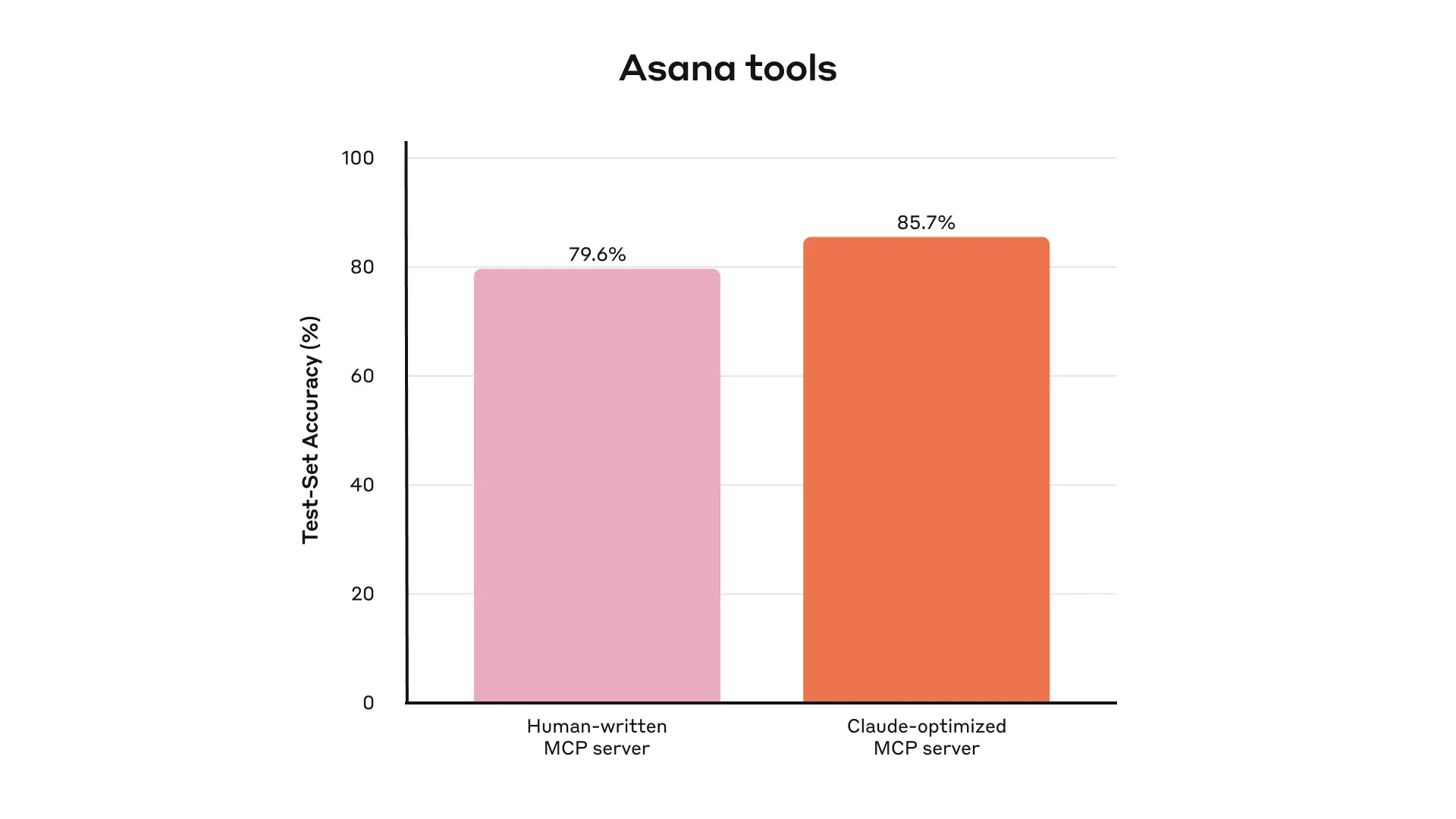
这是内部Asana工具的留出测试集性能。
与代理协作
你甚至能让代理分析结果并改进工具。把评估转录粘到Claude Code,它擅长分析并重构工具,确保一致性。
我们的大部分建议来自用Claude Code优化内部工具。评估基于内部工作空间,镜像真实项目、文档和消息。
用留出测试集避免过拟合。测试显示,即使专家写的工具,Claude也能进一步提升性能。
编写高效工具的原则
通过迭代,我们总结了一些原则,帮助你写出更好工具。
选择合适的工具(以及不该实现的)
你可能好奇:“该实现哪些工具?更多工具更好吗?”不一定。常见错误是简单包装现有功能,而不考虑代理需求。
代理上下文有限,不能像电脑内存那样处理海量数据。例如,搜索地址簿:传统软件逐个检查,但代理如果工具返回所有联系人,就浪费上下文读无关信息。更好是先搜索相关页面。
建议:从少数针对高影响工作流的工具开始,匹配评估任务,再扩展。
工具能合并功能,内部处理多操作。例如:
-
✦ 不是
list_users、list_events、create_event,而是schedule_event找可用时间并调度。 -
✦ 不是
read_logs,而是search_logs只返相关行和上下文。 -
✦ 不是
get_customer_by_id、list_transactions、list_notes,而是get_customer_context一次性编译客户近期信息。
每个工具要有清晰、独特目的。让代理像人类一样细分任务,减少中间输出消耗上下文。
太多或重叠工具会分散代理。仔细规划能回报大。
命名空间你的工具
代理可能访问上百工具,包括他人写的。重叠或模糊工具会困惑代理。
用命名空间分组:按服务(如asana_search、jira_search)或资源(如asana_projects_search、asana_users_search)。
前缀或后缀命名影响评估性能,依LLM而变,根据你的评估选。
这减少上下文加载,转移计算到工具调用,降低错误风险。
从工具返回有意义上下文
工具实现应只返高信号信息。优先相关性而非灵活性,避免低级ID如uuid、256px_image_url、mime_type。用name、image_url、file_type更直接影响代理行动。
代理处理自然语言ID比加密ID好。把UUID解析成语义语言或0索引ID,能减幻觉,提高检索精度。
有时代理需两者:用response_format枚举参数,让代理选“concise”或“detailed”响应。
例如ResponseFormat枚举:
详细响应示例(206令牌):
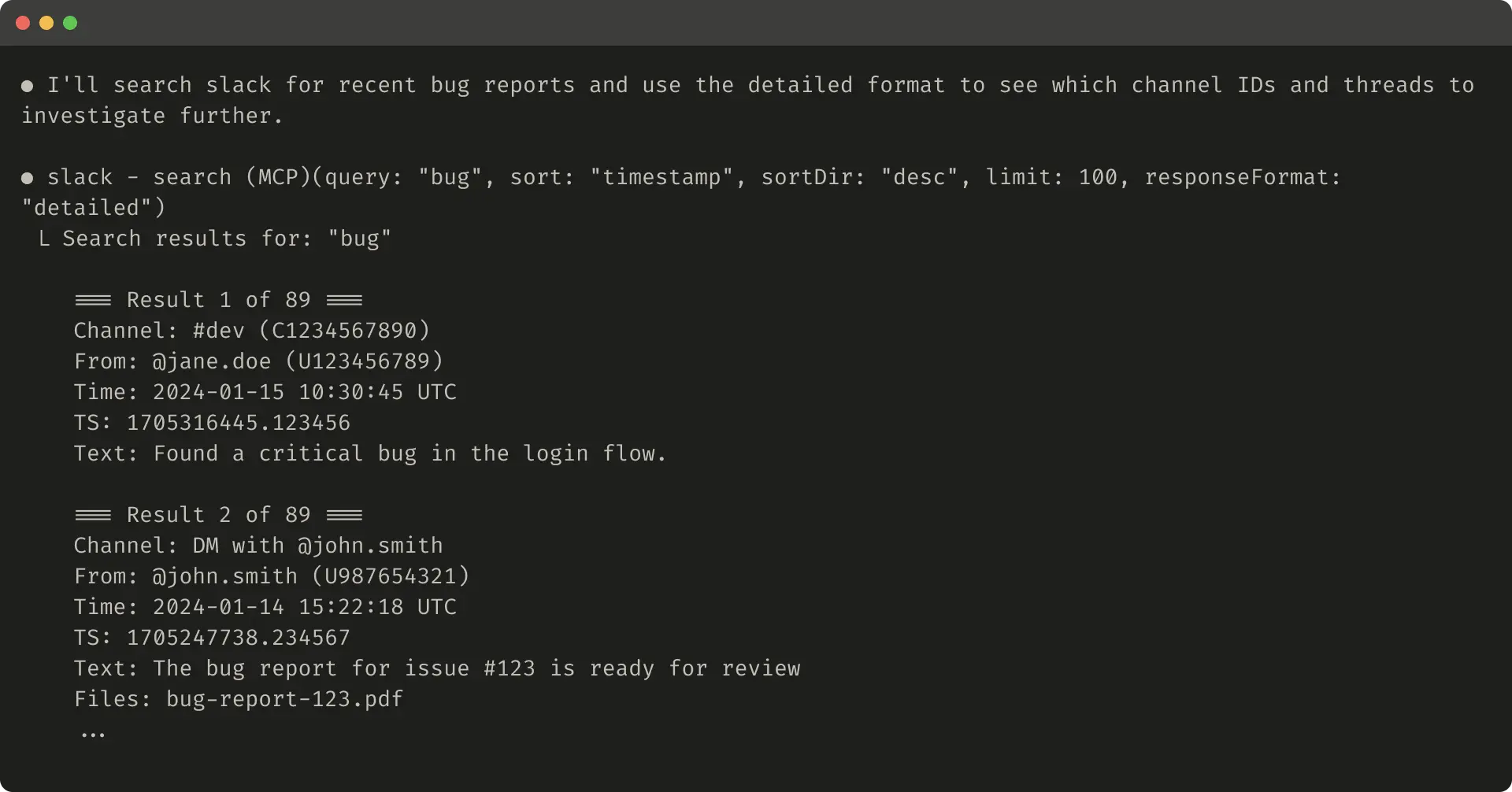
简洁响应示例(72令牌):
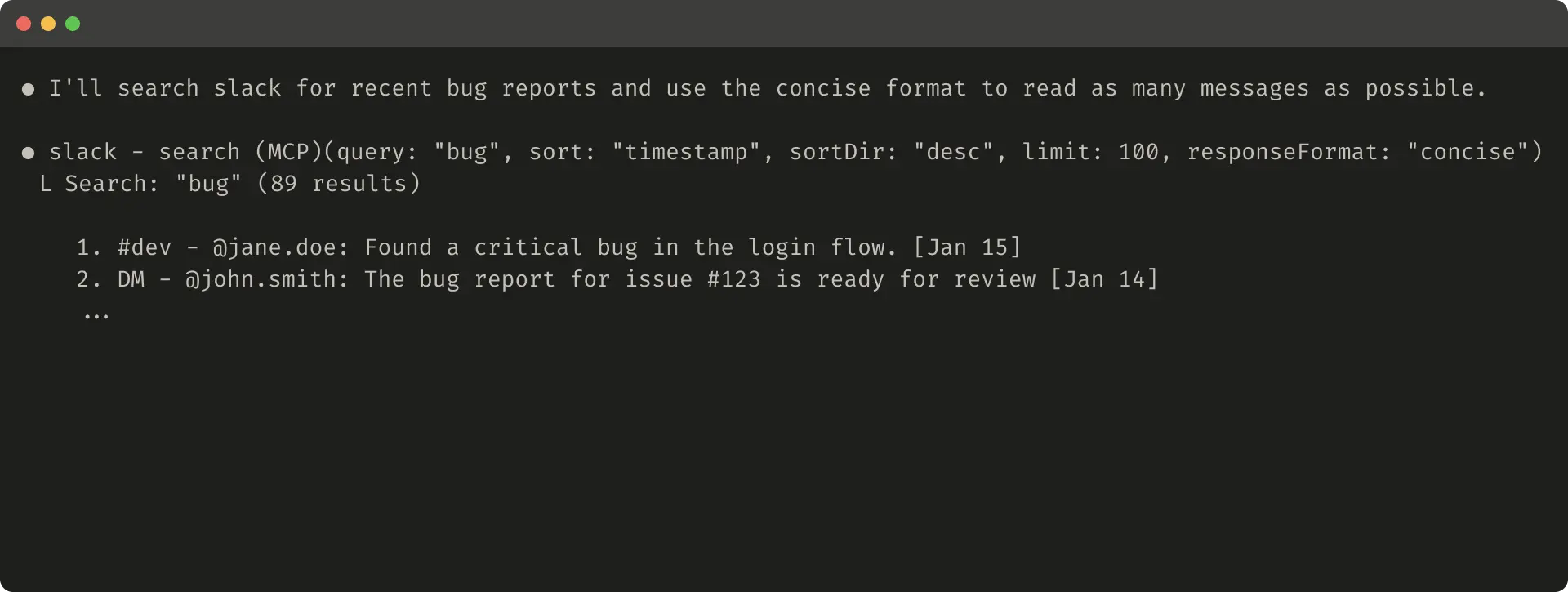
Slack线程用thread_ts标识,详细响应返ID以进一步调用,简洁只返内容,用1/3令牌。
工具响应结构(如XML、JSON、Markdown)影响性能,因LLM训练数据。根据任务和代理选最佳,根据评估。
优化工具响应以节省令牌
质量重要,数量也重要。实现分页、范围选择、过滤、截断,默认值合理。
Claude Code默认限25,000令牌。代理上下文会增长,但高效工具需求不变。
截断时,指导代理:鼓励小针对搜索而非大广搜索。错误响应要具体、可行动,而非模糊代码。
截断响应示例:
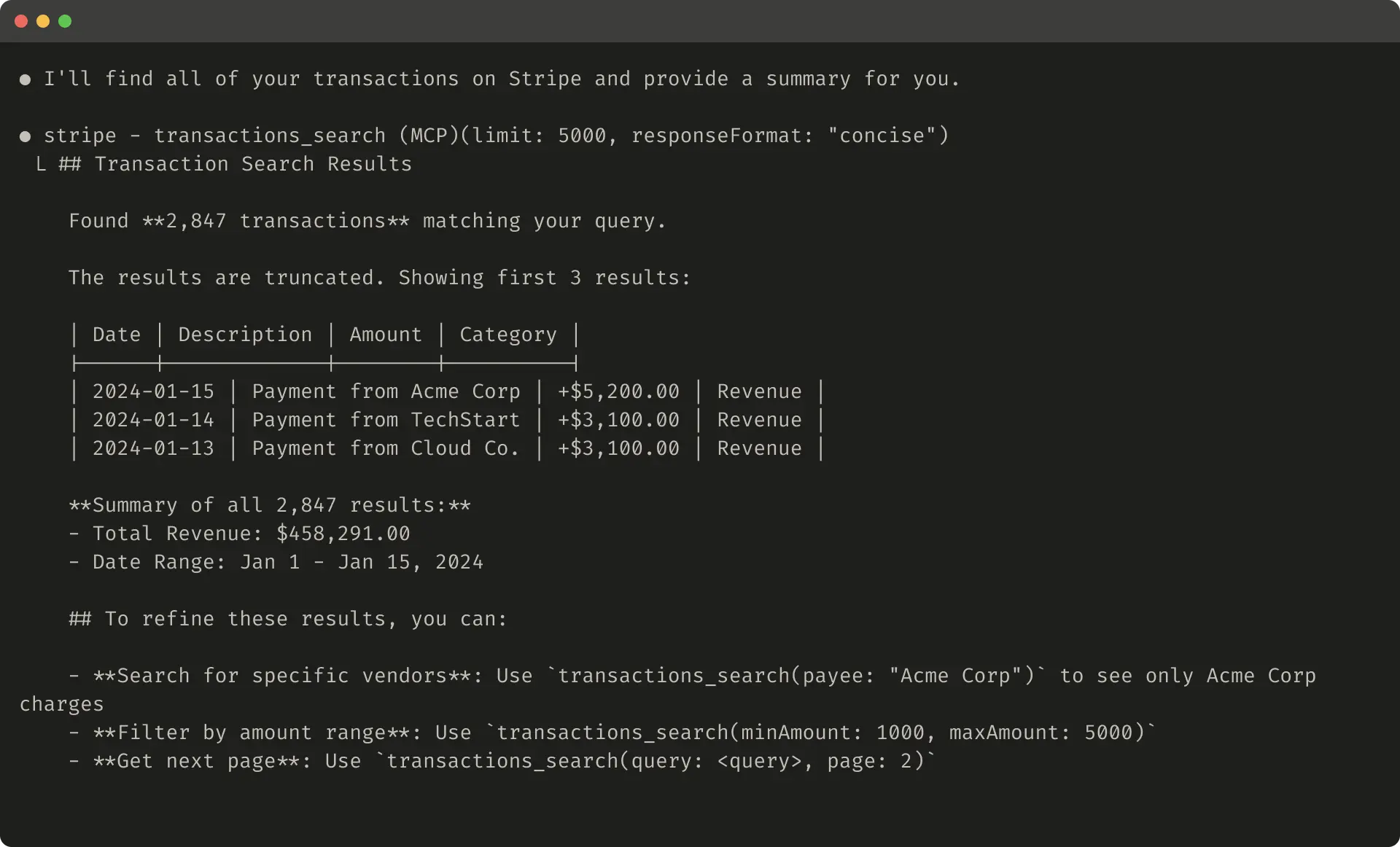
无帮助错误示例:
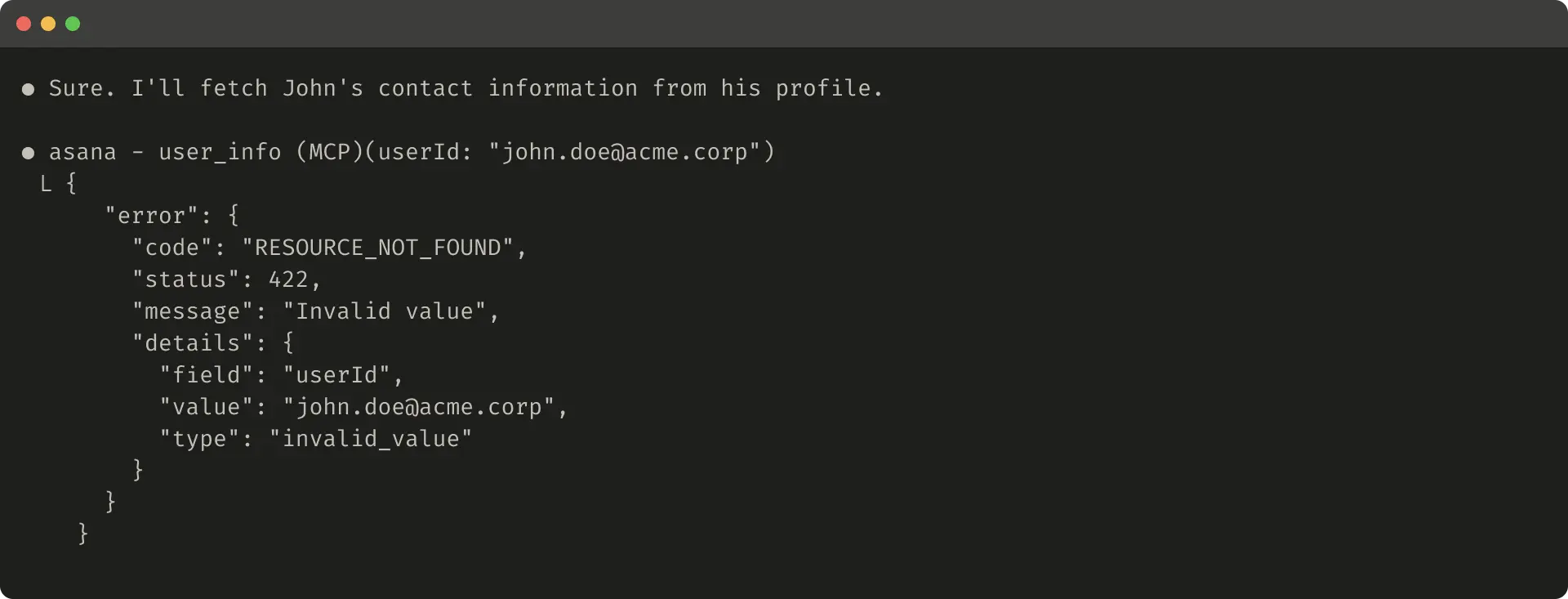
帮助错误示例:
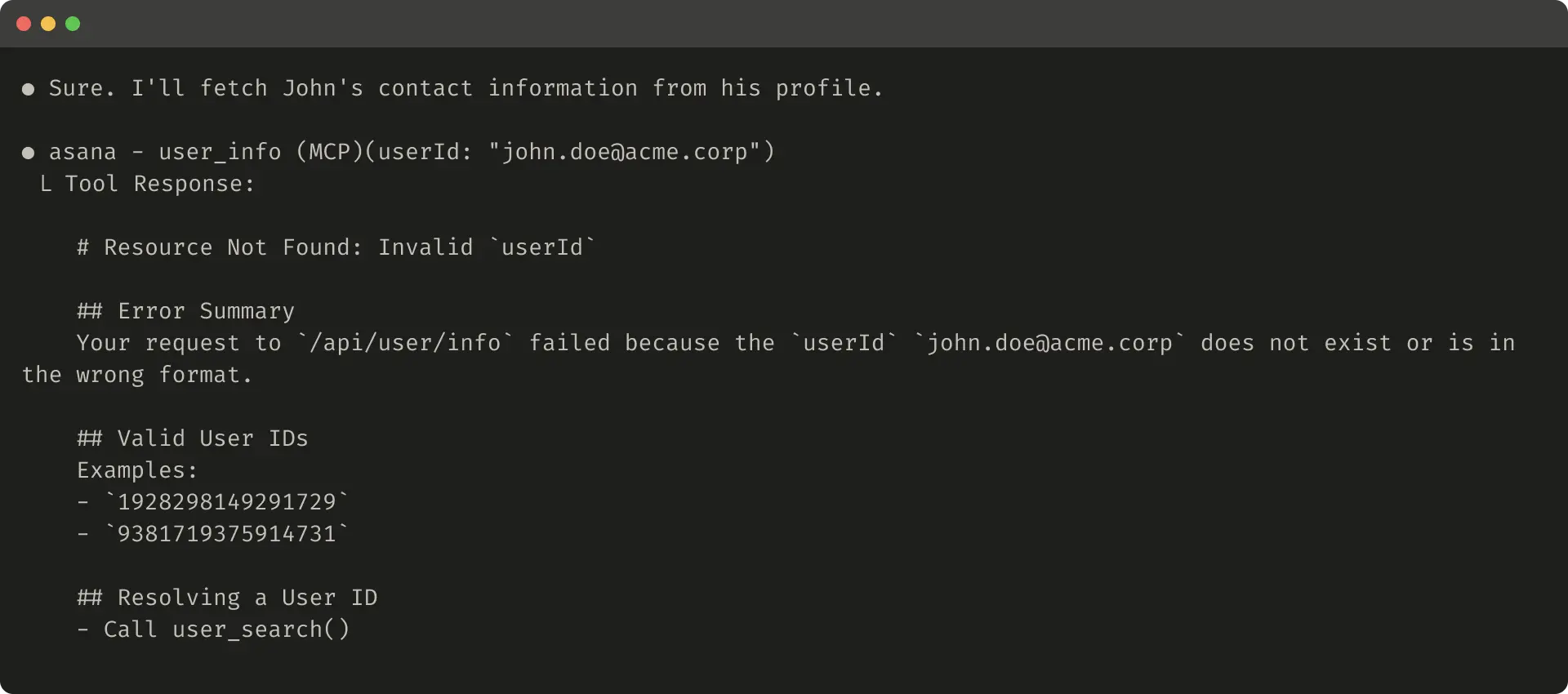
这些能引导代理更高效用工具。
提示工程你的工具描述
最有效方法之一:优化工具描述和规格。这些加载到代理上下文,能引导行为。
写时,像向新员工描述:明确查询格式、术语定义、资源关系。避免歧义,用严格数据模型定义输入输出。参数名清晰:不是user,而是user_id。
用评估测量影响。小改动能大提升。Claude Sonnet 3.5在SWE-bench Verified上达SOTA,通过精确描述减错误,提高完成率。
其他最佳实践:在开发者指南中。Claude工具动态加载到系统提示。MCP服务器用工具注解披露开放世界访问或破坏变更。
展望未来
为代理写工具,需要从确定性转向非确定性。
通过迭代评估,我们发现成功工具有意清晰定义、审慎用上下文、可组合、多样工作流、直观解决真实任务。
未来,代理交互机制会演化,如MCP更新或LLM升级。用系统方法改进工具,能确保工具随代理能力成长。

如何指南:一步步优化你的工具
如何生成评估任务?
-
用Claude Code探索工具,创建提示-响应对。
-
基于真实用例,确保复杂性。
-
配验证响应,避免过拟合策略。
如何分析评估结果?
-
让代理反馈问题。
-
观察卡点,读CoT。
-
审转录和指标,调整参数。
如何用枚举控制响应格式?
用如上ResponseFormat,让代理选详细或简洁,平衡灵活性和效率。
FAQ:常见问题解答
LLM代理的工具和传统API有什么不同?
传统API是确定性合同,工具是代理非确定性合同。代理可能不总调用工具,或出错,所以设计要适应变异。
为什么更多工具不总是更好?
多工具可能分散代理,浪费上下文。聚焦少数高影响工具,能让代理高效策略。
如何避免工具响应浪费上下文?
用分页、过滤、截断。默认限令牌,指导代理小调用。
命名空间怎么帮代理选工具?
分组工具如按服务,减少困惑,清晰边界。
工具描述怎么提示工程?
像教新员工:明确一切,避免歧义。用评估测试改动。
Claude Code怎么帮优化工具?
粘转录,让它分析重构,确保一致。
评估中用什么指标?
准确率、运行时间、调用次数、令牌用、错误。
工具响应结构重要吗?
是的,依LLM训练数据。测试XML、JSON等选最佳。
未来工具设计怎么变?
随代理能力,机制演化,但原则如清晰、效率不变。
通过这些步骤和原则,你能让工具更有效。记住,迭代是关键:建原型、评估、改进,再重复。你的代理会感谢你,因为它们能更好处理真实世界挑战。
