一口气看懂 Google Gemini 3 Pro:架构、长上下文与多模态代理能力全解析
适合人群:计算机/电子/自动化等相关专业毕业生、AI 产品经理、初级算法工程师
阅读收益:10 min 掌握 Gemini 3 Pro 的设计动机、关键指标、适用场景与落地限制
1. 它到底解决了什么问题?
| 老痛点 | Gemini 3 Pro 给出的答案 |
|---|---|
| 长文档/代码库一次读不完 | 原生 1 M token 上下文 ≈ 3 小时视频或 1 万行代码 |
| 多模态需拼接专用模型 | 文本、图像、音频、视频同一套参数 |
| 高推理成本 | 稀疏 MoE,只激活 8% 专家 |
| 代理任务链路断裂 | 官方提供 Antigravity 环境,代码→终端→浏览器一键闭环 |
一句话总结:把“超长多模态输入 + 低成本推理 + 代理闭环”做成可用 API。
2. 模型架构:稀疏 MoE + 1 M 上下文
2.1 稀疏专家怎么工作?
-
每层有 N 组“专家”前馈网络 -
路由网络为每个 token 选 Top-K 专家(K≈2) -
其余专家休眠,计算量≈全参数模型的 8%
好处:参数总量↑,推理 FLOPs↓,显存占用线性增长而非指数增长
2.2 1 M 上下文如何训练?
-
数据:网页、代码、图文对、授权视频、合成数学题 -
预训练:从 4 k → 32 k → 256 k → 1 M 逐步放大窗口 -
后训练:多模态指令微调 + RLHF(人类+评论家双重打分)
| 阶段 | 目标 | 关键 trick |
|---|---|---|
| 4 k | 通用语言建模 | 标准 next-token |
| 32 k | 代码/文档 | 随机跨度式打包 |
| 256 k | 视频字幕对齐 | 帧级时间戳对齐 |
| 1 M | 代理长链推理 | 强化学习奖励 = 答案正确性 + 格式可执行性 |
3. 关键指标:Gemini 3 Pro VS 2.5 Pro
| 基准 | 2.5 Pro | 3 Pro | 提升幅度 |
|---|---|---|---|
| Humanity’s Last Exam(无工具) | 21.6 % | 37.5 % | +74 % |
| ARC-AGI-2(视觉推理) | 4.9 % | 31.1 % | +535 % |
| GPQA Diamond(科学问答) | 84.7 % | 91.9 % | +7.2 % |
| AIME 2025(数学竞赛) | 78 % | 95 %(无工具)/ 100 %(带代码) | +17~22 % |
| MMMU Pro(大学级图文题) | 68 % | 81 % | +13 % |
| Video-MMMU | 83.6 % | 87.6 % | +4 % |
| ScreenSpot Pro(UI 元素定位) | 11.4 % | 72.7 % | +538 % |
| OmniDocBench 1.5(OCR+结构理解) | 0.189 | 0.115 编辑距离 | -39 % |
| SWE-Bench Verified(单轮 GitHub 修 bug) | 59.6 % | 76.2 % | +16.6 % |
| Terminal-Bench 2.0(命令行代理) | 32.6 % | 54.2 % | +21.6 % |
| τ2-bench 工具使用均值 | 73 % | 85.4 % | +12.4 % |
| Vending-Bench 2(长线经营模拟) | 573 $ | 5478 $ 净值 | +855 % |
数据来源:Google DeepMind 官方技术报告,2025-11 版本,均为 pass@1 单尝试 成绩,无多数投票。
4. 多模态能力拆解
4.1 图像:MMMU-Pro
-
题目:大学物理、化学、生物、工程图表选择题 -
形式:10 选项,图文混排 -
做法:模型先看图后看题,一次输出答案 -
结果:81 %,超 GPT-5.1(76 %)与 Claude Sonnet 4.5(68 %)
4.2 视频:Video-MMMU
-
输入:每帧 280 token,1 分钟视频 ≈ 16 k token -
温度:0(保证一致性) -
结果:87.6 %,领先 2.5 Pro 4 个百分点
4.3 UI 定位:ScreenSpot Pro
-
任务:给定自然语言指令,在截图里返回元素坐标 -
技巧:API 开启 media_resolution=extra_high,函数调用capture_screenshot -
结果:72.7 %,把 2.5 Pro 的 11.4 % 甩出几条街
5. 代码与代理:开发者最该关心的四条线
| 场景 | 指标 | 3 Pro 表现 | 一句话点评 |
|---|---|---|---|
| 实时编程 | LMArena Elo | 1501 | 排行榜第一 |
| Web 开发 | WebDev Arena Elo | 1487 | 前端切图、写业务逻辑最稳 |
| 终端代理 | Terminal-Bench 2 | 54.2 % | 过半任务能独立用 bash+git 解决 |
| 修 GitHub Issue | SWE-Bench Verified | 76.2 % | 单轮提交,已接近 Claude Sonnet 4.5 的 77.2 % |
Antigravity 环境把上面四条串成一条闭环:
-
用 Gemini 3 Pro 写代码 -
用 2.5 Computer Use 模型开浏览器查文档 -
Nano Banana 生成示意图 -
一键运行单元测试→自动提交 PR
6. 长上下文压力测试
| 长度 | 测试集 | 指标 | 结果 |
|---|---|---|---|
| 128 k | MRCR v2(8 针检索) | 平均召回 | 77 % |
| 1 M | MRCR v2 单点 | 召回 | 26.3 % |
说明:1 M 场景下“针”埋在 90 % 深度,模型仍能拉回 26 %,对比 2.5 Pro 的 16 % 有绝对提升,但密度越高遗忘越明显,这是目前所有长上下文模型的共同瓶颈。
7. 使用指南:30 分钟上手
7.1 申请 API
-
打开 Google AI Studio -
左侧 Model 选择 gemini-3-pro-preview -
生成 Key,复制到环境变量 export GEMINI_API_KEY=YOUR_KEY
7.2 最小可运行示例(Python)
import google.generativeai as genai
genai.configure(api_key=os.getenv("GEMINI_API_KEY"))
model = genai.GenerativeModel("gemini-3-pro-preview")
response = model.generate_content(
["Solve the integral of x*sin(x^2) dx"],
generation_config={"temperature": 0, "max_output_tokens": 4096}
)
print(response.text)
7.3 多轮长上下文调用
chat = model.start_chat(history=[])
# 第一轮:丢 200k token 的代码库
chat.send_message(long_code_base)
# 第二轮:提问
ans = chat.send_message("Where is the memory leak in the above?")
print(ans.text)
注意:输入超过 128 k 后,价格按 1 M 封顶计费,详见官方价目表。
8. 局限与风险
| 类别 | 具体表现 | 缓解建议 |
|---|---|---|
| 幻觉 | GPQA 仍有 8 % 错误;长上下文针检索 1 M 时召回降至 26 % | 事实性任务加搜索插件,temperature=0 |
| 成本 | 1 M token 输入 ≈ 15 | 先切片检索,再精准窗口 |
| 安全 | 可生成可执行脚本 | 沙箱执行 + 人工 review |
| 延迟 | 1 M 上下文首包 20~30 s | 流式输出 + 切片并发 |
9. FAQ(预测你的下一个问题)
Q1:Gemini 3 Pro 是公开模型吗?
A:目前仅预览版,需通过 Google AI Studio / Vertex AI 申请,权重不开放。
Q2:1 M token 到底能塞多少东西?
A:≈ 70 万汉字,或 3 小时 1080P 视频字幕,或 1 万行 Python 代码。
Q3:稀疏 MoE 会不会降低质量?
A:从 ARC-AGI-2 的 4.9 %→31.1 % 看,激活少但能力反而提升,说明专家分工有效。
Q4:可以本地部署吗?
A:官方未提供本地权重;只能调云 API。
Q5:和 Claude Sonnet 4.5 比怎么选?
A:代码修复两者打平;超长多模态选 Gemini,短文本安全选 Claude。
Q6:训练数据截止到什么时候?
A:报告未披露,但提到包含“2025 年用户交互数据”,可推测最晚 2025 Q2。
10. 一图速览
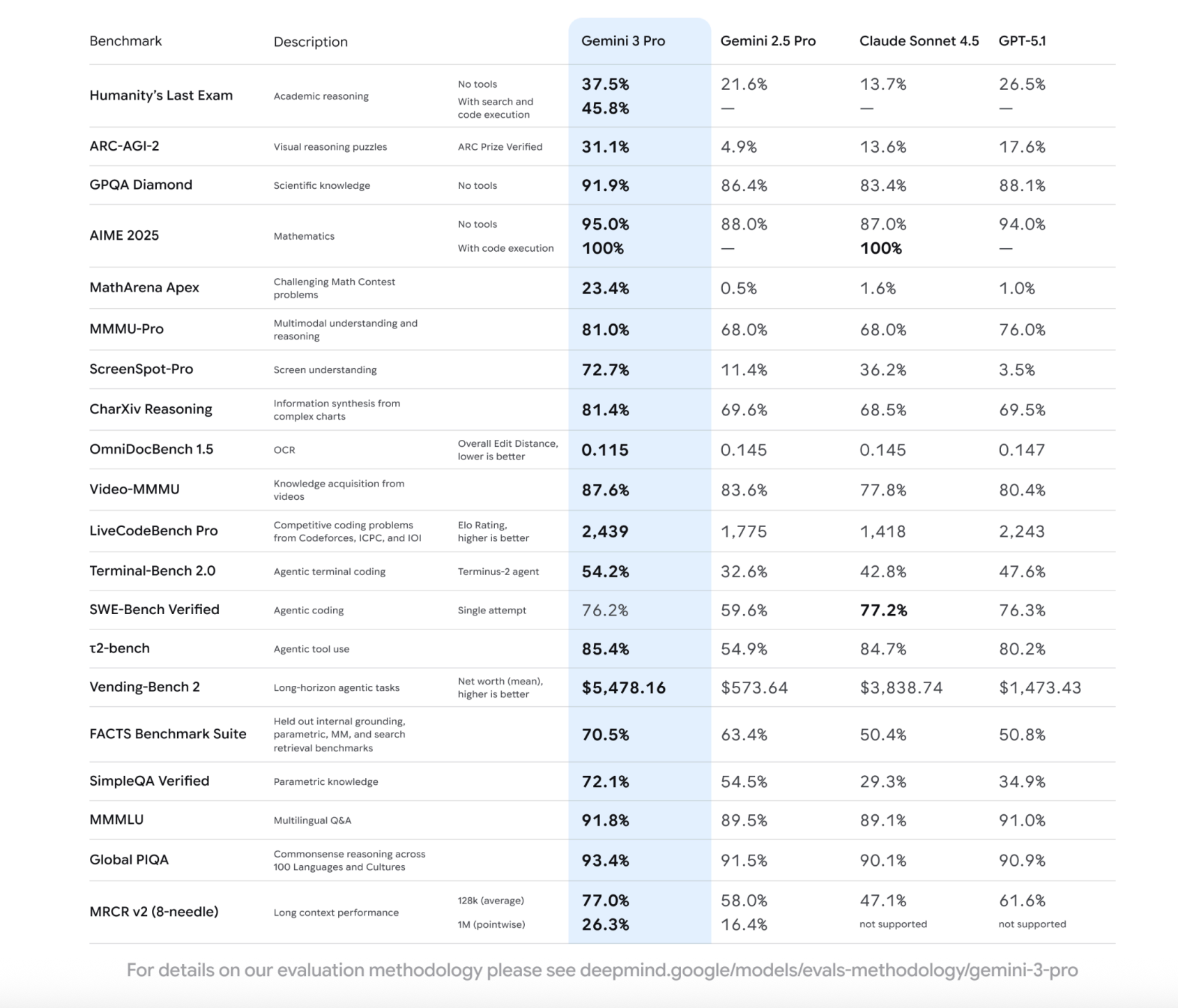
Gemini 3 Pro 在推理、数学、代码、多模态四大维度对比示意
11. 结论:适合干什么,不适合干什么
| 适合 | 不适合 |
|---|---|
| 一次读 200 页 PDF 后问答 | 需要 100 % 事实准确的医疗诊断 |
| 跨模态视频切片检索 | 超低延迟<200 ms 的实时推荐 |
| 单轮 GitHub Issue 自动修 bug | 需要本地私有化权重 |
| 代理流程:写代码→跑测试→提交 | 纯中文古典文学创意写作(仍偏好英文) |
把 Gemini 3 Pro 想成一位“会看图、能写代码、记忆力超长但偶尔说错细节的实习生”,就能快速判断该不该让它上场。
