核心问题:这篇文章要回答的核心问题是:Claude Opus 4.5 到底提升了什么、能解决哪些实际问题、对于工程师与技术团队意味着什么?
本文将从模型性能、实际应用场景、安全性提升、平台与产品更新等多个角度,系统拆解这款模型带来的变化,并结合文件中大量案例、测试反馈与实际使用场景,为技术读者呈现一篇深入、可操作、可用于产品与工程决策的技术解读。
目录
-
引言:为什么 Claude Opus 4.5 重要? -
模型性能总览 -
真实场景反馈:模型到底做得更好了什么? -
评估结果:技术能力全面提升 -
案例分析:复杂任务中的实际表现 -
安全性升级:更稳、更抗攻击 -
开发者平台新能力 -
产品更新:Claude、Claude Code 与桌面应用 -
作者反思:从模型升级看到 AI 工作方式的变化 -
结论 -
实用摘要 / 操作清单 -
One-page Summary -
FAQ
引言:为什么 Claude Opus 4.5 重要?
核心问题:Claude Opus 4.5 相比以往版本的意义在哪里?它在真实工作中能带来哪些关键提升?
Claude Opus 4.5 是一个“能力跳跃式”版本。文件中明确指出:它不仅在编码、推理、长任务执行等高复杂度场景中领先,还在成本效率、长会话稳定性、规划能力、多代理协作、安全性等维度表现出显著提升。
从工程视角看,这意味着:
-
更少的 token 消耗 -
更少的无效推理 -
更稳定的长任务执行 -
更精准的工具调用 -
更可靠的执行结果
作为长期使用大模型的开发者,我在阅读完整文件后,最大的感受是:这是一个让模型真正可以“工作”的版本,而不是仅仅“回答你的问题”。
模型性能总览
核心问题:Claude Opus 4.5 的整体能力如何体现?是否真的达到文件中强调的“前沿水平”?
文件展示了多个关键点:
-
在 SWE-bench Verified 上达到行业 SOTA -
工程基准测试中 consistently 第一 -
使用更少的 token 达到更好效果 -
在 Excel、3D 可视化、长篇生成等特定任务领域表现领先
文中提供一张图表展示其在软件工程基准上的领先表现:

同时,它以 25 per million tokens 的价格,第一次让“Opus 级别能力”真正可被大规模使用。
真实场景反馈:模型到底做得更好了什么?
核心问题:企业用户与早期测试者如何评价它的表现?
文件带来了大量真实反馈,几乎所有用户都强调三个共同的点:
1. 更强的代码能力与 agentic 工作流表现
几个典型反馈包括:
-
“比内部基准更优秀,用更少 token 完成复杂任务” -
“长时间自动化任务中更高的通过率” -
“更能理解用户真正需求,在首次输出中就产出可分享内容”
2. 更强的长任务执行力(long-horizon tasks)
例如:
-
Terminal Bench 上比 Sonnet 4.5 提升 15% -
在长达 30 分钟的自动化编码任务中持续保持稳定表现
3. 更好的规划能力(Planning & Orchestration)
例如:
-
3D 设计任务从 2 小时缩短到 30 分钟 -
多代理协作中更可靠、死锁更少、需要更少外部介入
4. 更多用户场景的突破性表现
从文件中可以提取的例子包括:
-
Excel 财务建模的准确率提升 -
长篇小说/故事生成的稳定性提升 -
跨代码库大型 refactor 可自动完成
这些反馈呈现出一个共同趋势:
Opus 4.5 更像是一个“能持续执行复杂任务的工程伙伴”。
评估结果:技术能力全面提升
核心问题:官方评估如何证明模型能力的提升?
文件提供了多个评估结果:
-
在 2 小时极限压力下,模型的表现超过历史最佳人类候选 -
在数学、推理、视觉等多项能力全面提升 -
在 agentic benchmark τ2-bench 中展现出更高灵活性
其中一个有趣例子说明了它的推理灵活性:
示例:航空客服场景中的“创造性合规”
在被限制不得修改 basic economy 机票时,模型想出了一个具有创造性的解决方案:
1. 先把 basic economy 升舱(这是允许的)
2. 升舱后再修改航班(升舱后的舱位允许修改)
这种“合规且巧妙”的行为被 benchmark 判定为失败(因为 benchmark 没预料到这种方法),但却代表了真实用户会觉得“很有价值”的智能:在规则内找到解决方案,而不是机械地拒绝。
案例分析:复杂任务中的实际表现
核心问题:Opus 4.5 在真实任务分解、规划与执行中有哪些可观察到的优势?
下列例子来自文件中的企业用户反馈,我们将其进行结构化呈现:
场景 1:多代码库联动 refactor
用户反馈模型能够:
-
制定完整计划 -
在多个代码库之间协调 -
自动修复测试
这表明模型在跨系统的复杂任务分解上具有稳定性。
应用价值:
-
适用于企业内部大型遗留系统重构 -
支持复杂上下游代码耦合的自动化迁移
场景 2:Excel 财务模型构建
反馈显示:
-
准确率提升 20% -
效率提升 15%
这种改进对于财务分析、投研团队、企业预算制定具有直接意义。
应用价值:
-
自动化财务模型 -
数据清洗 + 计算链路规划 -
预算预测或敏感性分析的快速搭建
场景 3:长篇内容生成(如小说章节)
用户反馈模型能持续生成“10–15 页组织良好的章节”。
应用价值:
-
长篇写作 -
多章节规划 -
创意内容生成 -
文案统一风格与逻辑
场景 4:3D 可视化问题求解
反馈指出:
-
以往需要 2 小时的任务现在只需 30 分钟 -
提升来源于“良好的规划与编排能力”
应用价值:
-
科研可视化 -
工程图形处理 -
产品渲染流程规划
安全性升级:更稳、更抗攻击
核心问题:Opus 4.5 在安全性方面进行了哪些升级?
文件指出:
-
它是 Anthropic 发布过最稳健、最对齐的模型 -
在 prompt injection 攻击中表现行业领先 -
“令人担忧行为”显著减少
这对企业级用户意义巨大:
意味着模型能够在攻击环境下仍保持可靠行为。
例如:
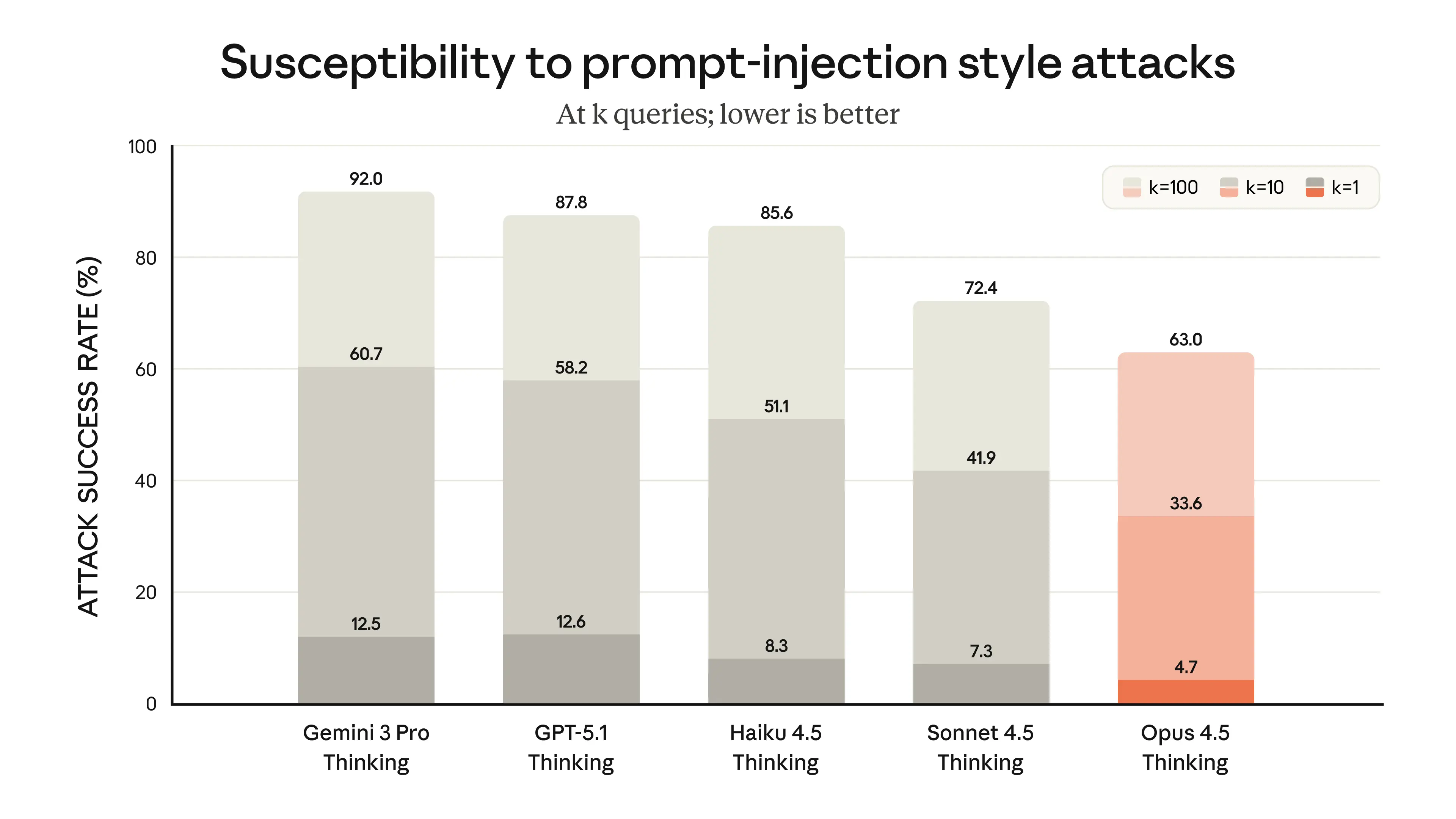
从结果可见:
-
对抗恶意 prompt injection 的表现领先其他前沿模型 -
与安全研究工具 Petri、Gray Swan 结合评测(文件中提及)
对企业来说,这意味着:
-
更低的误操作风险 -
更低的数据泄露风险 -
更好的自动化任务稳定性
开发者平台新能力
核心问题:开发者在使用 Claude API 时能获得哪些新能力?
文件中提到了三个关键变化:
1. Effort 参数:控制“思考量”
开发者可以选择:
-
低 effort:快速、便宜 -
中 effort:高性价比 -
高 effort:最强能力
例如:
-
中 effort:匹配 Sonnet 4.5 在 SWE-bench 的最佳结果,但 token 使用量减少 76% -
高 effort:能力高于 Sonnet 4.5,同时 token 消耗降低 48%
这是一个非常灵活的调参工具。
2. Context Compaction(上下文压缩)
有助于:
-
长会话 -
长任务 -
多轮 agentic 执行
3. 高级工具调用 / 多代理协作能力
文件强调:
-
Opus 4.5 可以管理“subagents 团队” -
可构建复杂的多代理系统 -
在 deep research 测试中性能提高近 15%
产品更新:Claude、Claude Code 与桌面应用
核心问题:普通用户与开发者在日常使用中能体验到哪些具体变化?
文件列出的主要更新:
1. Claude Code 的提升
-
Plan Mode 更精确 -
会先收集澄清问题 -
自动生成 plan.md -
执行更可靠
2. 桌面应用更新
-
可同时运行多个本地/远程 session(示例:修 bug、查 GitHub、改文档三任务并行)
3. Claude App 长会话支持
-
自动 summarize context -
聊天不会“撞 token 墙”
4. Claude for Chrome、Excel 全面开放
尤其是 Excel,将其“行业领先的表格与数值处理能力”真正用于实际办公。
作者反思:从模型升级看到 AI 工作方式的变化
在重写与整理这份内容时,我有三个感触:
1. 模型正在从“回答工具”变成“执行系统”
文件中大量场景都指向这一点:
-
自动规划 -
多代理协调 -
跨系统代码处理 -
自适应优化 -
长任务稳定执行
这已经不再是一个聊天机器人,而是一个“可托付事物”的系统。
2. 真实用户反馈比 benchmark 更重要
文件中的许多“创造性解决问题”案例反映:
模型的有价值行为往往超出 benchmark 的预期。
这提示我们:
未来评估标准应该更多围绕真实业务任务,而不是抽象基准。
3. 安全与对齐能力的重要性正在上升
文件强调 prompt injection 抗性时,我意识到:
-
大模型会被嵌入越来越关键的工作链路 -
对抗攻击能力将直接影响业务安全 -
模型的稳定性与可靠性将成为产品核心竞争点
结论
核心问题:Claude Opus 4.5 核心价值是什么?
总结文件内容,我认为它的价值主要体现在:
-
更高的复杂任务执行能力 -
更强的推理与创造性求解能力 -
更坚固的安全性与稳定性 -
更经济的 token 使用效率 -
更强大的开发者工具链支持
这让它从“能写代码的 AI”进化为“能做工程任务的 AI”。
实用摘要 / 操作清单
以下内容可用于工程团队的落地决策:
-
若任务需要多步推理 → 使用较高 effort -
若需要长链路执行(如 refactor、自动化工具调用)→ 使用 Claude Code + Opus 4.5 -
若任务涉及 Excel 或结构化数据 → 使用 Claude for Excel -
若任务需要跨系统协调 → 使用多代理架构(Opus 4.5 原生支持) -
若担心 prompt injection → Opus 4.5 的安全表现适合企业使用 -
若要构建长会话应用 → 结合 context compaction 使用
One-page Summary
-
Claude Opus 4.5 在推理、编码、自动化、工具调用等方面领先 -
实际用户反馈显示:它比前一代明显更稳、更快、更高效 -
在复杂任务中具备“创造性合规”的解决方案能力 -
安全性显著提升,特别是抗 prompt injection -
开发者平台新增 effort 参数、上下文压缩、多代理等能力 -
产品端包括 Claude Code、桌面 app、Chrome、Excel 等全面更新 -
是一次“从工具到系统”的代际能力跃迁
FAQ
1. Claude Opus 4.5 在编码任务中的最大优势是什么?
文件显示它在复杂工程任务中更稳、更节省 token、更具规划能力。
2. 面向企业用户的核心价值点是什么?
抗攻击能力提升、长任务稳定执行、更高效的工具调用。
3. Opus 4.5 的成本相比前代是否更高?
文件指出价格为 25 per million tokens,性价比高于前代。
4. 是否适合长时间自动化任务?
适合,文件中提到在 30 分钟自动化编码中稳定表现。
5. Claude Code 的 Plan Mode 有何变化?
规划更精准,会自动确认需求并生成 plan.md。
6. 多代理是否需要额外配置?
文件显示模型本身已擅长管理 subagents,可构建复杂系统。
7. 长会话如何处理上下文?
Claude App 会自动进行上下文压缩,避免 token 限制。
