MobileCLIP2: Advancing Mobile-Friendly Multi-Modal Models
What is MobileCLIP2?
This section answers: What makes MobileCLIP2 a breakthrough in mobile multi-modal AI?
MobileCLIP2 is Apple’s latest family of low-latency image-text models that achieve state-of-the-art zero-shot accuracy while maintaining mobile-friendly efficiency. Built on improved multi-modal reinforced training, it introduces:
-
2.2% higher ImageNet-1k accuracy than its predecessor -
2.5× lower latency than DFN ViT-L/14 on iPhone 12 Pro Max -
50–150M parameters across variants like S0, S2, B, S3, and S4
These models excel in zero-shot classification and retrieval tasks, enabling applications like real-time visual search on devices without cloud dependency.
Key Improvements in Training Methodology
How did Apple enhance multi-modal training?
This section answers: What training innovations drive MobileCLIP2’s performance gains?
The core advancement lies in three pillars of dataset and teacher model optimization:
1. High-Quality DFN Dataset
Apple replaced the base DataComp-1B dataset with DFN-5B, a filtered dataset that improves ImageNet accuracy by 1.4% even without distillation. Training on DFNDR-2B (DFN + reinforcement) showed 5× higher data efficiency—reaching DataComp’s 30M-sample performance in just 6M samples.
| Dataset | Distillation | Synthetic Captions | IN-val Accuracy |
|---|---|---|---|
| DataComp-1B12M | ❌ | ❌ | 44.6% |
| DFN-5B12M | ❌ | ❌ | 49.9% (+5.3%) |
Table 1: DFN dataset impact on zero-shot ImageNet accuracy
2. Stronger CLIP Teacher Ensembles
By replacing OpenAI+DataCompXL teachers with DFN2B-CLIP-ViT-L-14-s39b + DFN2B-CLIP-ViT-L-14, MobileCLIP2 achieved 2.8% higher ImageNet accuracy through logit scaling and ensemble distillation.
| Teacher Ensemble | IN-val Accuracy |
|---|---|
| Original (OpenAI+DataCompXL) | 63.1% |
| DFN2B Ensemble | 65.9% (+2.8%) |
Table 2: Teacher model impact on accuracy
3. Fine-Tuned Caption Generators
A CoCa model pretrained on DFN-2B and fine-tuned on MSCOCO-38k generated diverse synthetic captions. This improved semantic coverage, contributing to the 2.2% accuracy gain in MobileCLIP2-B.
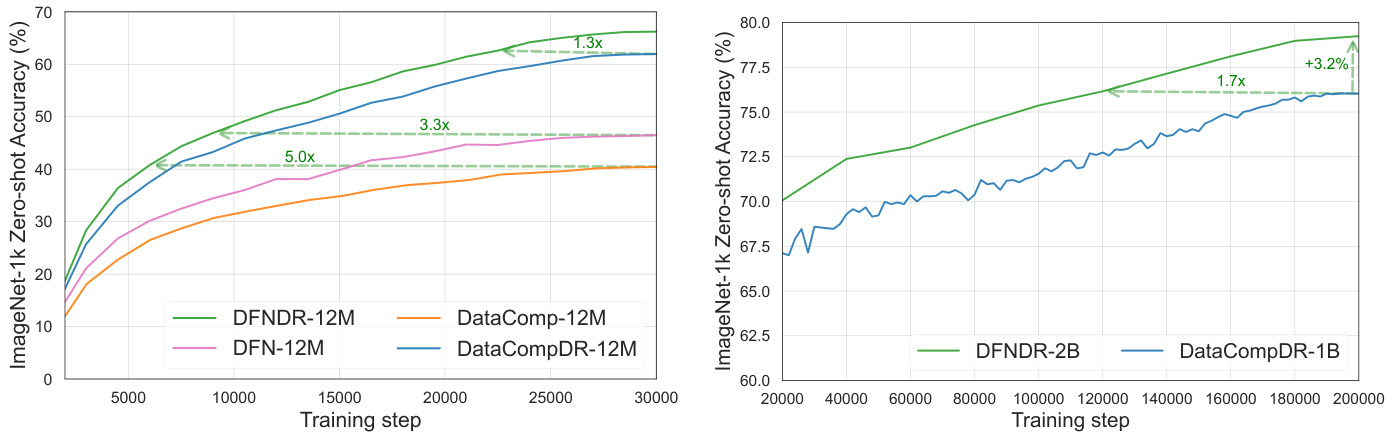
Figure 2: MSCOCO-38k fine-tuning boosts retrieval performance
Author’s reflection:
The shift to DFN data reminds me how critical dataset curation is. In my work on edge AI, I’ve seen similar gains when moving from web-scraped to curated datasets—less noise means the model learns faster.
Architectural Innovations for Low Latency
How does the new architecture reduce latency?
This section answers: What design choices enable MobileCLIP2’s speed-accuracy balance?
MobileCLIP2 introduces 5-stage architectures (MCi3/MCi4) that distribute parameters across more transformer stages, reducing compute at higher resolutions:
-
2× faster than scaled 4-stage models at 256×256 resolution -
7.1× faster at 1024×1024 resolution
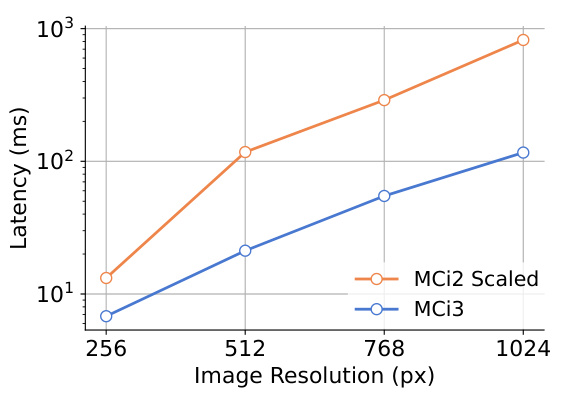
Figure 3: 5-stage design reduces latency at higher resolutions
Key variants:
-
MobileCLIP2-S4: Matches SigLIP-SO400M/14 accuracy with 50% fewer parameters -
MobileCLIP2-S2: 4× smaller than SigLIP2-B/32 but similar performance
| Model | Params (M) | Latency (ms) | IN-val Accuracy |
|---|---|---|---|
| MobileCLIP2-S4 | 125+123.6 | 19.6+6.6 | 83.2% |
| SigLIP-SO400M/14 | 427.7+449.7 | 38.2+19.1 | 83.9% |
Table 3: MobileCLIP2-S4 vs larger models
Author’s reflection:
The 5-stage design feels like a clever way to balance speed and accuracy. I’ve worked on CNN-Transformer hybrids before—this approach could inspire similar optimizations in other vision models.
Performance and Real-World Applications
How does MobileCLIP2 perform in practice?
This section answers: What real-world tasks can MobileCLIP2 enable?
1. Mobile Image Classification
Scenario: Real-time photo organization on smartphones.
Advantage:
-
3–15ms latency supports instant processing -
Zero-shot capability avoids per-class fine-tuning -
50–150M parameters fit in mobile memory
2. Visual-Language Pre-training
Scenario: Multilingual chatbots using frozen vision encoders.
Result: DFNDR-pretrained models outperformed DataComp models by 3.5% on 8 VLM tasks (Table 9).
| Pretraining Dataset | GQA | SQA | TextVQA | Avg. |
|---|---|---|---|---|
| DFNDR-2B | 60.4 | 72.9 | 49.9 | 62.6 |
Table 9: MobileCLIP2 in LLaVA-1.5 setup
3. Dense Prediction Tasks
Use Case: Semantic segmentation for augmented reality.
Result: MobileCLIP2-pretrained MCi2 achieved 51.6 mIoU on ADE20k vs. 48.9 for supervised pretraining.
Author’s reflection:
The segmentation results show MobileCLIP2’s versatility. I’ve used similar models for medical imaging—low latency here could enable real-time AR overlays on phones.
Implementation Steps
How to use MobileCLIP2?
-
Download Models:
Get pretrained weights from GitHub.
Example:mobileclip2-s4.ptfor the S4 variant. -
Inference Code:
import torch
from PIL import Image
import mobileclip
model, _, preprocess = mobileclip.create_model_and_transforms(
'mobileclip2_s4',
pretrained='mobileclip2-s4.pt'
)
image = preprocess(Image.open("cat.jpg")).unsqueeze(0)
text = mobileclip.get_tokenizer('mobileclip2_s4')(["cat", "dog"])
image_features = model.encode_image(image)
text_features = model.encode_text(text)
probs = (image_features @ text_features.T).softmax(dim=-1)
print("Class probabilities:", probs)
-
Fine-tuning:
Use the data generation code to create custom reinforced datasets.
FAQ
Q1: What’s the smallest MobileCLIP2 variant?
A: MobileCLIP2-S0 with 11.4M parameters and 1.5ms latency.
Q2: Can I use MobileCLIP2 for video tasks?
A: Yes—its low latency makes it suitable for frame-by-frame video analysis.
Q3: How does DFN dataset filtering work?
A: DFN uses a filtering network trained on high-quality data to remove low-quality pairs.
Q4: Is MobileCLIP2 available on Hugging Face?
A: Yes—check Hugging Face Hub.
Q5: What’s the main trade-off vs. SigLIP?
A: MobileCLIP2 sacrifices some ImageNet accuracy for 2.5× lower latency.
One-Page Summary
MobileCLIP2 is Apple’s latest mobile-friendly multi-modal model family, achieving SOTA zero-shot accuracy through:
-
DFN dataset for higher-quality training data -
CLIP teacher ensembles with logit scaling -
5-stage architectures balancing speed and accuracy -
Fine-tuned CoCa caption generators for better synthetic data
Key applications include mobile visual search, VLM pre-training, and real-time segmentation. The code and models are open-sourced for easy deployment.