Xiaomi-Robotics-0: How an Open-Source Vision-Language-Action Model Solves Real-Time Inference Bottlenecks
Core Question: When robots need to understand visual commands and execute complex actions within milliseconds, why do traditional models always lag behind? How does Xiaomi-Robotics-0 solve this industry challenge through architectural design?

Image source: SINTEF Digital
Why We Need a New Generation of VLA Models
Core Question of This Section: What fundamental challenges do existing vision-language-action models face in real-world deployment?
Robotics is undergoing a quiet revolution. Over the past five years, we have witnessed the explosive growth of large language models (LLMs) and vision-language models (VLMs). However, when these capabilities are transferred to the physical world—enabling robots to truly “see” their environment, “understand” instructions, and “perform” actions—an awkward gap persists: models are either too large to achieve acceptable inference latency, or they perform poorly when generalizing across different scenarios.
Xiaomi-Robotics-0 was created to fill this gap. This is a 4.7 billion parameter vision-language-action (VLA) model that does not simply concatenate existing VLMs with action control modules. Instead, it rethinks the collaboration between “perception-reasoning-execution” from the architectural level.
The key breakthroughs lie in three dimensions:
-
Cross-embodiment generalization: During pre-training, the model is exposed to data from multiple robot forms, enabling it to adapt to different arm configurations, sensor setups, and task scenarios rather than being limited to a single hardware platform.
-
Real-time inference guarantee: Through asynchronous execution architecture, the model generates action sequences while the robot executes previously generated actions in parallel, eliminating the traditional serial waiting time of “generate-execute-regenerate.”
-
Consumer-grade hardware compatibility: With Flash Attention 2 and bfloat16 precision optimization, the model runs smoothly on ordinary consumer-grade GPUs, lowering the barrier to entry for research and application.
Reflection: When evaluating robot models, we often focus too much on static benchmark scores while neglecting “real-time capability”—a critical metric in real-world scenarios. A model with 95% accuracy but requiring 5 seconds to respond may be far less practical in dynamic environments than a system with 85% accuracy but response times under 100 milliseconds. The design philosophy of Xiaomi-Robotics-0 reminds us that the measurement standard for robot intelligence must include the “time dimension.”
Model Architecture: Collaboration Between VLM and Diffusion Transformer
Core Question of This Section: How does Xiaomi-Robotics-0 use a two-stage training strategy to retain vision-language capabilities while acquiring precise action generation abilities?
The architectural design of Xiaomi-Robotics-0 embodies engineering wisdom of “clear division of labor and efficient collaboration.” The entire system consists of two core components:
Core Architecture Components
| Component | Technical Choice | Functional Position | Parameter Scale |
|---|---|---|---|
| Vision-Language Backbone | Qwen3-VL-4B-Instruct | Processes multi-view image observations and language instructions, generates KV Cache | 4 billion |
| Action Generation Module | Diffusion Transformer (DiT) | Generates continuous action sequences via flow matching, conditioned on KV cache and robot state | 0.7 billion |
| Total | – | – | 4.7 billion |
The key advantage of this decoupled design is that the VLM component can fully utilize pre-trained vision-language understanding capabilities, while the DiT component focuses on learning the mapping from high-level semantics to low-level control signals.
Two-Stage Pre-training Strategy
Stage One: Endowing VLM with Action Understanding
The model first fine-tunes the VLM using “Choice Policies.” This method cleverly handles the multimodal nature of action trajectories—for the same task, there are multiple feasible execution paths. By having the model learn to evaluate the quality of different action sequences rather than directly imitating a single trajectory, the system gains deep understanding of the action space.
During this stage, training data uses a 1:6 mixture ratio of vision-language data to robot trajectories. This ratio is carefully designed: too little VL data leads to catastrophic forgetting, causing the model to lose basic capabilities like visual question answering; too much VL data dilutes the signal for action learning.
Stage Two: Training DiT for Action Generation
Once the VLM possesses action understanding capabilities, this module is frozen and becomes a “multimodal conditioner” for the DiT. The DiT learns the flow matching objective function from scratch, generating precise and smooth action chunks based on the VLM’s visual-language features and the robot’s proprioceptive state.
Reflection: This “understand first, generate later” staged training strategy actually mimics how humans learn new skills—we first understand “what is right” through observation, then practice “how to do it.” In robot learning, this progressive training is often more stable than end-to-end joint training because it sets clear learning objectives for each stage, avoiding gradient conflicts and confused optimization goals.
Data Engine: Balancing Scale and Diversity
Core Question of This Section: What kind of data support is needed to train a VLA model with strong generalization capabilities?
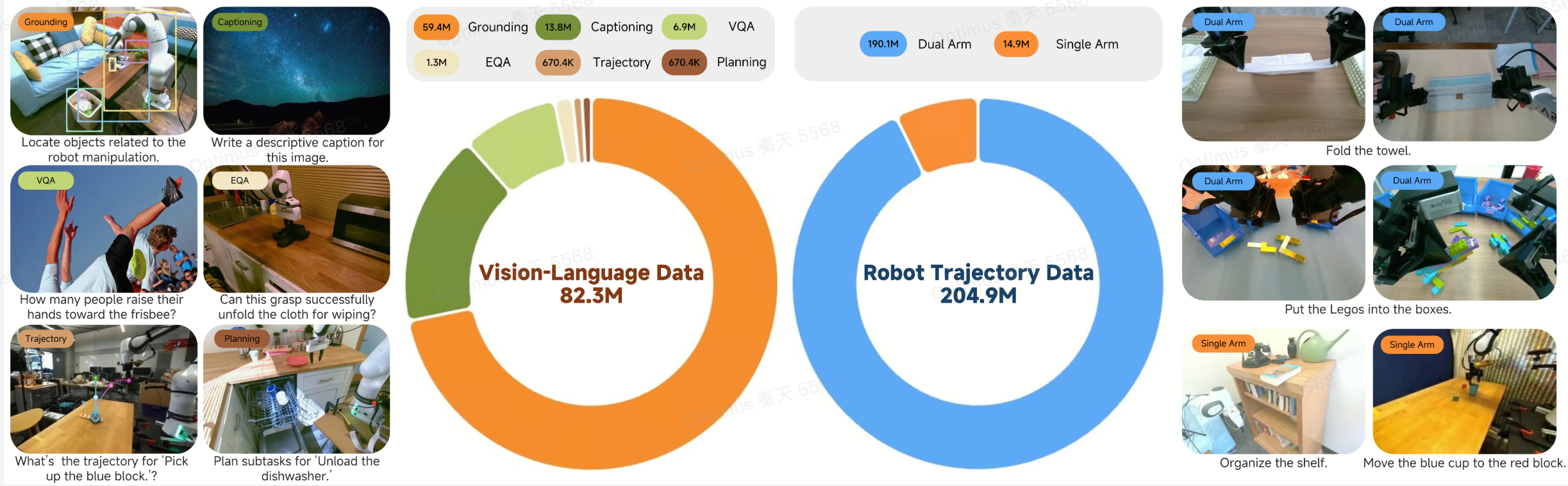
Data quality determines the upper limit of model capabilities. The training data scale of Xiaomi-Robotics-0 is impressive:
Data Composition Overview:
-
Robot trajectory data: Approximately 200 million timesteps -
General vision-language data: Over 80 million samples
Robot Data Source Breakdown:
| Data Type | Content Description | Scale/Duration |
|---|---|---|
| Open-source datasets | Public cross-embodiment robot manipulation data | Large-scale mixture |
| Lego Disassembly | Dual-arm collaboration tasks collected via teleoperation | 338 hours |
| Towel Folding | High-difficulty tasks involving deformable objects | 400 hours |
The selection of Lego disassembly and towel folding tasks is quite deliberate. Lego disassembly requires the robot to understand the mechanical properties of complex assembly structures and plan multi-step disassembly sequences. Towel folding involves highly deformable flexible objects, requiring fine force control and visual feedback. The inclusion of these tasks significantly enhances the model’s ability to handle complex scenarios.
The introduction of vision-language data is not just icing on the cake but a necessary measure to prevent the model from forgetting basic visual understanding capabilities. Maintaining strong visual understanding on robot-centric images is crucial for accurately perceiving the state of manipulation objects.
Post-Training and Deployment: Solving Real-Time Inference Challenges
Core Question of This Section: How does asynchronous execution architecture address the inference latency bottleneck of VLA models?
This is the most innovative engineering aspect of Xiaomi-Robotics-0. Traditional action generation models use a “generate first, execute later” serial mode: the model generates an action sequence, and after the robot finishes executing, the next inference begins. This mode causes obvious “stuttering” as model parameters increase—the robot remains stationary while waiting for new instructions.
Core Mechanism of Asynchronous Execution
Xiaomi-Robotics-0 uses action prefixing technology to achieve true parallel processing:
-
Parallel pipeline: While the robot executes the remaining portion of the current action chunk, the model has already started inferring the next action chunk. -
Temporal alignment: By conditioning the next inference on Δtc committed actions from the previous chunk, ensuring smooth transitions between consecutive action chunks. -
Latency guarantee: As long as Δtc is greater than the inference latency Δtinf, the robot always has executable actions and will not “idle.”
Key Constraint Condition:
Δtc > Δtinf
Where:
-
Δtc: Time corresponding to the number of actions retained from the previous chunk as prefix -
Δtinf: Inference time required for the model to generate a new action chunk
Addressing Temporal Correlation Traps
Action prefixing technology brings a potential risk: temporal correlation shortcuts. Since consecutive actions are often highly similar, the model may learn to simply “copy” prefix actions rather than truly re-reasoning based on visual and language signals. This leads to sluggish actions that lack adaptability to environmental changes.
To address this, the research team designed two key technologies:
Lambda-Shape Attention Mask
In the DiT, the traditional causal attention mask is replaced with a lambda-shaped structure:
-
Noisy action tokens immediately following the prefix can access prefix information, ensuring action continuity. -
Noisy action tokens at later timesteps are prohibited from accessing the prefix, forcing them to rely on visual and other signals, ensuring reactivity in generated actions.
This design achieves a delicate balance between “continuity” and “reactivity.”
Adaptive Loss Re-weighting
The system dynamically adjusts the flow matching loss weights based on the L1 error between online predicted actions and ground truth actions. When the model deviates from true trajectories, loss weights automatically increase, applying stronger correction signals.
Reflection: The proposal of asynchronous execution architecture marks a paradigm shift in robot learning from “algorithm-first” to “system-first.” In the past, we often assumed computation was instantaneous, but in real robot systems, inference latency is an inseparable part of interacting with the physical world. Explicitly incorporating latency into architectural design rather than trying to mask it through hardware upgrades demonstrates profound understanding of the problem’s essence. This approach of “dancing with latency” rather than “fighting against latency” has implications for other real-time AI systems as well.
Performance: From Simulation to Reality
Core Question of This Section: How does Xiaomi-Robotics-0 perform in standardized benchmark tests and real-world tasks?
Simulation Benchmark Tests
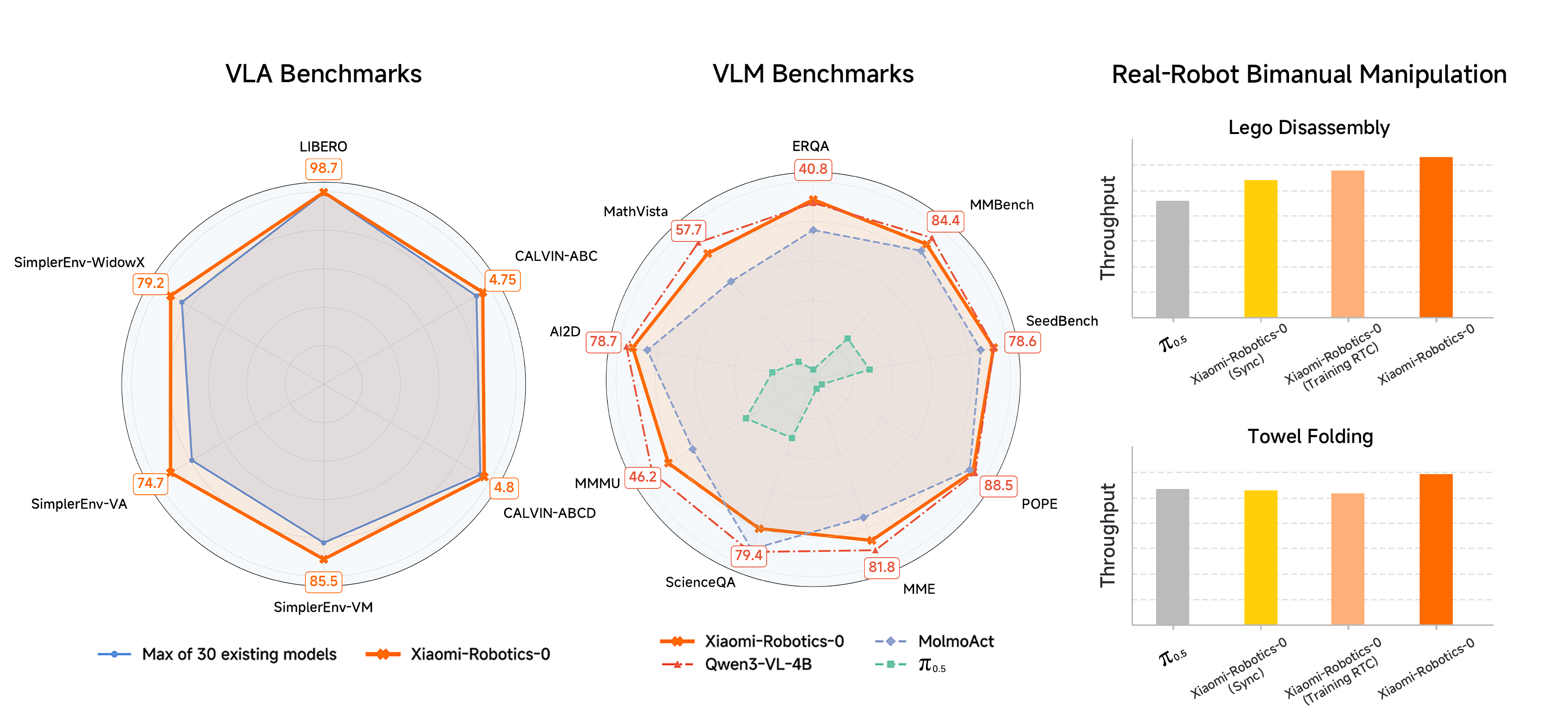
The model was comprehensively evaluated on three mainstream simulation platforms:
LIBERO Benchmark (Single-Arm Manipulation)
-
After fine-tuning on four LIBERO test suites, the average success rate reached 98.7%. -
This performance indicates the model approaches saturation performance on desktop manipulation tasks.
CALVIN Benchmark (Long-Horizon Tasks)
-
ABC→D split: Average task completion length 4.75 -
ABCD→D split: Average task completion length 4.80 -
This benchmark tests the model’s ability to execute multi-step tasks continuously; higher values indicate the model can complete more subtasks before failure.
SimplerEnv Benchmark (Visual Generalization)
-
Google Robot setting: Visual Matching (VM) 85.5%, Visual Aggregation (VA) 74.7% -
WidowX setting: 79.2% -
These tests evaluate the model’s generalization capabilities under different visual conditions.
Real Robot Validation
Testing on real hardware better demonstrates the model’s practical value:
Lego Disassembly Task
The model can handle complex assemblies composed of up to 20 bricks. This requires the system to understand:
-
Connection topology relationships between bricks -
Mechanical constraints of disassembly sequences -
Long-term planning for multi-step operations
Adaptive Grasping
When grasping fails, the model can adaptively switch grasping strategies rather than mechanically repeating the same action. This “trial-and-error learning” capability is crucial for unstructured environments.
Towel Folding Task
Facing highly deformable flexible objects, the model demonstrates fine manipulation strategies:
-
When a towel corner is occluded, it learns to fling the towel with one hand to expose the hidden part. -
When accidentally picking up two towels, it can recognize the error, return the extra towel, and restart the folding process.
These behaviors are not explicitly programmed but emergent capabilities learned from data.

Image source: Labellerr
Quick Start: Installation and Deployment Guide
Core Question of This Section: How can you quickly deploy Xiaomi-Robotics-0 in a local environment for inference?
Xiaomi-Robotics-0 is built on the HuggingFace Transformers ecosystem, making the deployment process relatively straightforward. Here are the complete, verified installation steps:
Environment Preparation
System Requirements:
-
Python 3.12 -
CUDA-compatible GPU (recommended: cards supporting bfloat16) -
Support for transformers >= 4.57.1
Installation Steps:
# Clone the repository
git clone https://github.com/XiaomiRobotics/Xiaomi-Robotics-0
cd Xiaomi-Robotics-0
# Create Conda environment
conda create -n mibot python=3.12 -y
conda activate mibot
# Install PyTorch 2.8.0 (verified version)
pip install torch==2.8.0 torchvision==0.23.0 torchaudio==2.8.0 --index-url https://download.pytorch.org/whl/cu128
# Install Transformers
pip install transformers==4.57.1
# Install Flash Attention 2 (key performance optimization)
pip uninstall -y ninja && pip install ninja
pip install flash-attn==2.8.3 --no-build-isolation
# If compilation issues occur, use precompiled wheel:
# pip install https://github.com/Dao-AILab/flash-attention/releases/download/v2.8.3/flash_attn-2.8.3+cu12torch2.8cxx11abiTRUE-cp312-cp312-linux_x86_64.whl
# Install system dependencies (Ubuntu/Debian)
sudo apt-get install -y libegl1 libgl1 libgles2
Model Loading and Inference Example
The following code demonstrates how to load the model and perform action generation:
import torch
from transformers import AutoModel, AutoProcessor
# 1. Load model and processor
model_path = "XiaomiRobotics/Xiaomi-Robotics-0-LIBERO"
model = AutoModel.from_pretrained(
model_path,
trust_remote_code=True,
attn_implementation="flash_attention_2",
dtype=torch.bfloat16
).cuda().eval()
processor = AutoProcessor.from_pretrained(
model_path,
trust_remote_code=True,
use_fast=False
)
# 2. Construct multi-view input prompt
language_instruction = "Pick up the red block."
instruction = (
f"<|im_start|>user\nThe following observations are captured from multiple views.\n"
f"# Base View\n<|vision_start|><|image_pad|><|vision_end|>\n"
f"# Left-Wrist View\n<|vision_start|><|image_pad|><|vision_end|>\n"
f"Generate robot actions for the task:\n{language_instruction} /no_cot<|im_end|>\n"
f"<|im_start|>assistant\n<cot></cot><|im_end|>\n"
)
# 3. Prepare input data
# Assuming image_base, image_wrist, and proprio_state are already loaded
inputs = processor(
text=[instruction],
images=[image_base, image_wrist], # [PIL.Image, PIL.Image]
videos=None,
padding=True,
return_tensors="pt",
).to(model.device)
# Add proprioceptive state and action mask
robot_type = "libero"
inputs["state"] = torch.from_numpy(proprio_state).to(model.device, model.dtype).view(1, 1, -1)
inputs["action_mask"] = processor.get_action_mask(robot_type).to(model.device, model.dtype)
# 4. Generate action sequence
with torch.no_grad():
outputs = model(**inputs)
# Decode into executable control commands
action_chunk = processor.decode_action(outputs.actions, robot_type=robot_type)
print(f"Generated Action Chunk Shape: {action_chunk.shape}")
Key Configuration Notes:
-
trust_remote_code=True: Allows loading custom model architectures -
attn_implementation="flash_attention_2": Enables Flash Attention acceleration -
dtype=torch.bfloat16: Uses bfloat16 precision to balance performance and memory usage -
/no_cottag: Disables chain-of-thought generation to reduce latency -
action_mask: Specific masks for different robot types (libero, calvin, etc.)
Available Model Checkpoints
| Model Name | Application Scenario | Performance Metrics | HuggingFace Link |
|---|---|---|---|
| Xiaomi-Robotics-0-LIBERO | Four LIBERO test suites | 98.7% average success rate | Link |
| Xiaomi-Robotics-0-Calvin-ABCD_D | CALVIN ABCD→D split | 4.80 average length | Link |
| Xiaomi-Robotics-0-Calvin-ABC_D | CALVIN ABC→D split | 4.75 average length | Link |
| Xiaomi-Robotics-0-SimplerEnv-Google-Robot | SimplerEnv Google Robot | VM 85.5%, VA 74.7% | Link |
| Xiaomi-Robotics-0-SimplerEnv-WidowX | SimplerEnv WidowX | 79.2% | Link |
| Xiaomi-Robotics-0 | Pre-trained base model | General VLA capabilities | Link |
Reflection: The decision to fully open-source the model and provide standardized HuggingFace interfaces significantly lowers the barrier to entry for the research community. In the past, many high-performance robot models were either not open-sourced or required complex custom training frameworks. By embracing the transformers ecosystem, Xiaomi-Robotics-0 allows researchers to invoke robot models as easily as calling BERT or GPT. This “demystification” initiative has long-term value for advancing the field.
Application Scenarios and Industry Value
Core Question of This Section: What actual business scenarios are suitable for Xiaomi-Robotics-0’s technical characteristics?
Based on the model’s capabilities, the following application scenarios will directly benefit:
Manufacturing Flexible Automation
Traditional industrial robots rely on precise programming and fixed fixtures, making it difficult to handle small-batch, multi-variety production needs. Xiaomi-Robotics-0’s strong generalization capabilities enable it to quickly adapt to new tasks through natural language instructions, such as:
-
Identifying and grasping specific components from mixed parts piles -
Adjusting assembly strategies based on real-time visual feedback -
Handling slightly deformed workpieces or non-standard materials
Logistics and Warehouse Sorting
In e-commerce logistics scenarios, packages vary greatly in shape, size, and material. The visual generalization capabilities demonstrated by the model on SimplerEnv can be transferred to warehouse environments for package sorting, palletizing, and depalletizing tasks, reducing reliance on 3D vision systems and complex trajectory planning.
Service Robot Manipulation
Home or commercial service robots need to handle diverse daily objects. The flexible object manipulation capabilities verified by the towel folding task can be extended to clothing organization, tableware placement, cleaning tool usage, and other scenarios. Adaptive grasping strategies are particularly important for handling fragile or irregular items.
Research and Rapid Prototyping
For robotics researchers, Xiaomi-Robotics-0 provides a powerful baseline model. Researchers can build upon it for:
-
Domain-specific fine-tuning -
Multimodal perception fusion research -
Human-robot interaction strategy development -
Rapid adaptation to novel robot embodiments
Practical Summary and Action Checklist
One-Page Summary
| Dimension | Key Information |
|---|---|
| Model Positioning | 4.7 billion parameter open-source VLA model supporting real-time inference |
| Core Innovations | Asynchronous execution architecture, lambda-shape attention mask, two-stage pre-training |
| Performance Highlights | LIBERO 98.7%, CALVIN 4.80, SimplerEnv 85.5% |
| Hardware Requirements | Consumer-grade GPU supporting bfloat16, CUDA environment required |
| Deployment Difficulty | Low, based on HuggingFace Transformers, ready-to-use checkpoints provided |
| Applicable Scenarios | Flexible manufacturing, logistics sorting, service robots, research prototyping |
Quick Start Checklist:
-
[ ] Confirm GPU supports CUDA and has sufficient memory (recommended 16GB+) -
[ ] Install Python 3.12 and create Conda environment -
[ ] Install PyTorch 2.8.0 and Transformers 4.57.1 according to version requirements -
[ ] Install Flash Attention 2 for optimal performance -
[ ] Download fine-tuned models for corresponding tasks from HuggingFace -
[ ] Prepare multi-view camera inputs and robot proprioceptive state data -
[ ] Build inference pipeline following example code -
[ ] Configure action_mask according to actual robot type
Frequently Asked Questions (FAQ)
Q1: What are the unique advantages of Xiaomi-Robotics-0 compared to OpenVLA, RT-2, and other models?
A: The core difference lies in real-time inference architecture. Through asynchronous execution and action prefixing technology, Xiaomi-Robotics-0 eliminates the inference waiting time of traditional models, making robot actions smoother and more continuous. Meanwhile, the 4.7 billion parameter scale achieves a good balance between performance and hardware requirements.
Q2: Is Flash Attention 2 mandatory?
A: Strongly recommended. Flash Attention 2 significantly reduces memory usage and accelerates inference, making it a key component for achieving real-time performance. If installation difficulties occur, try using the precompiled wheel files provided by the project.
Q3: Which robot types does the model support?
A: Currently, official fine-tuned checkpoints are provided for LIBERO, CALVIN, and SimplerEnv (Google Robot, WidowX). The base model (Xiaomi-Robotics-0) can be used for further fine-tuning on other robot types.
Q4: How should I understand the concept of “action chunk”?
A: An action chunk is a sequence of future actions generated by the model at once (usually containing control commands for multiple timesteps), rather than single-step actions. This design allows the model to perform short-term planning and works with asynchronous execution architecture to achieve smooth action transitions.
Q5: What is the function of the lambda-shape attention mask?
A: It addresses the “temporal correlation shortcut” problem that action prefixing may cause. By restricting subsequent timesteps’ access to the prefix, it forces the model to re-reason based on visual and language signals, ensuring action reactivity and adaptability.
Q6: Can it run directly on real robots, or is it limited to simulation?
A: The model has been validated on real robots (Lego disassembly, towel folding, and other tasks). As long as your robot interface is compatible with the model’s output action format, it can be deployed to real hardware.
Q7: What is the approximate inference latency?
A: Specific latency depends on hardware configuration, but through asynchronous execution architecture, as long as inference time is less than the action prefix length (Δtc), execution stuttering will not occur. Using Flash Attention 2 and bfloat16 enables millisecond-level response on consumer-grade GPUs.
Q8: How can I fine-tune for specific tasks?
A: The project uses standard HuggingFace interfaces, so you can use standard training workflows from the transformers library for fine-tuning. It is recommended to first load the pre-trained base model, then continue training on specific task data.
Conclusion
Xiaomi-Robotics-0 represents significant progress in the open-source robot learning field. It not only achieves leading performance on standardized benchmarks but also solves the “last mile” problem of VLA models moving from laboratories to real-world scenarios through innovative asynchronous execution architecture. For developers and researchers looking to integrate vision-language-action capabilities into robot systems, this is a foundational platform worth attention and experimentation.
As hardware computing capabilities continue to improve and training data accumulates, we have reason to expect that such models will significantly lower the deployment barriers for robot automation in the coming years, driving substantive progress in flexible manufacturing, intelligent logistics, service robots, and other fields.
Image source: RoboDK
Related Resources:
-
Technical Report: Project Website -
Model Weights: HuggingFace Collection -
Project Homepage: xiaomi-robotics-0.github.io -
Open Source License: Apache License 2.0
