评估深度代理(Deep Agents):LangChain的实践经验总结
摘要
LangChain在开发基于Deep Agents框架的应用时,总结出五大评估模式:为每个数据点定制测试逻辑、利用单步评估验证决策、通过全代理回合掌握完整执行、多回合模拟真实交互、搭建合适的评估环境,助力高效测试深度代理。
过去一个月,LangChain基于Deep Agents框架开发并上线了四个应用,它们分别是:一个编码代理、LangSmith Assist(一款用于LangSmith中的内置代理,可提供多种帮助)、个人邮件助手(一款能从与每位用户的互动中学习的邮件助手),以及一个由元深度代理驱动的无代码代理构建平台。
在开发和上线这些代理的过程中,我们为每个代理都添加了评估环节,也从中积累了不少经验。接下来,我们就深入探讨评估深度代理的以下几种模式:
-
深度代理需要为每个数据点配备定制化的测试逻辑——每个测试用例都有其独特的成功标准。 -
让深度代理运行单步,非常适合在特定场景下验证决策能力(还能节省令牌)! -
全代理回合则有助于测试关于代理“最终状态”的断言。 -
多代理回合能模拟真实的用户交互,但需要加以引导和控制。 -
环境设置至关重要——深度代理需要干净、可重复的测试环境。
术语解释
在深入探讨之前,我们先来定义一些文中会反复用到的术语。
运行代理的方式:
-
单步(Single step):将核心代理循环限制为只运行一个回合,以此确定代理接下来要执行的动作。 -
全回合(Full turn):让代理在单个输入上完整运行,这可能包含多个工具调用迭代。 -
多回合(Multiple turns):让代理完整运行多次。通常用于模拟代理与用户之间有多次来回的“多轮”对话。

可测试的内容:
-
轨迹(Trajectory):代理调用的工具序列,以及代理生成的特定工具参数。 -
最终响应(Final response):代理返回给用户的最终回应。 -
其他状态(Other state):代理在运行过程中生成的其他值(例如文件、其他工件)。

1. 深度代理需要为每个数据点编写更多定制化的测试逻辑(代码)
传统的LLM评估很直接:
-
构建示例数据集 -
编写评估器 -
在数据集上运行应用程序以生成输出,然后用评估器对这些输出进行评分
每个数据点都被一视同仁——通过相同的应用程序逻辑处理,由相同的评估器评分。

但深度代理打破了这一常规。你需要测试的不仅仅是最终消息。每个数据点的“成功标准”可能更具特异性,可能需要对代理的轨迹和状态进行特定的断言。
举个例子:

我们有一个日历调度深度代理,它能够记住用户的偏好。当用户要求代理“记住不要在早上9点前安排会议”时,我们希望确认这个日历调度代理会更新其文件系统中的记忆,以记住这一信息。
为了测试这一点,我们可能需要编写断言来验证:
-
代理调用了edit_file工具,并且操作的文件路径正确。 -
代理在其最终消息中向用户传达了记忆已更新的信息。 -
目标文件中确实包含了关于不安排早会的信息。你可以: -
使用正则表达式查找是否提到“9am” -
或者使用LLM作为评判者,结合特定的成功标准对文件更新进行更全面的分析
-
LangSmith的Pytest和Vitest集成支持这种定制化测试。你可以针对每个测试用例,对代理的轨迹、最终消息和状态做出不同的断言。
# 标记为LangSmith测试用例
@pytest.mark.langsmith
def test_remember_no_early_meetings() -> None:
user_input = "I don't want any meetings scheduled before 9 AM ET"
# 我们可以将代理的输入记录到LangSmith
t.log_inputs({"question": user_input})
response = run_agent(user_input)
# 我们可以将代理的输出记录到LangSmith
t.log_outputs({"outputs": response})
agent_tool_calls = get_agent_tool_calls(response)
# 我们断言代理调用了edit_file工具来更新其记忆
assert any([tc["name"] == "edit_file" and tc["args"]["path"] == "memories.md" for tc in agent_tool_calls])
# 我们记录来自LLM评判者的反馈,判断最终消息是否确认了记忆更新
communicated_to_user = llm_as_judge_A(response)
t.log_feedback(key="communicated_to_user", score=communicated_to_user)
# 我们记录来自LLM评判者的反馈,判断记忆文件现在是否包含正确信息
memory_updated = llm_as_judge_B(response)
t.log_feedback(key="memory_updated", score=memory_updated)
想了解如何使用Pytest的通用代码片段,可以查看相关资源。
这种LangSmith集成会自动将所有测试用例记录到一个实验中,因此你可以查看失败测试用例的轨迹(以调试问题所在),并跟踪随时间变化的结果。
2. 单步评估很有价值且高效

在为深度代理运行评估时,大约一半的测试用例都是单步评估,也就是说,在一系列特定的输入消息之后,LLM决定立即采取什么行动?
这对于验证代理在特定场景下是否调用了正确的工具以及使用了正确的参数特别有用。常见的测试用例包括:
-
它是否调用了正确的工具来搜索会议时间? -
它是否检查了正确的目录内容? -
它是否更新了自己的记忆?
回归问题通常出现在单个决策点,而不是整个执行序列中。如果使用LangGraph,其流式传输功能允许你在单个工具调用后中断代理,以检查输出——这样你可以在早期发现问题,而无需承担完整代理序列的开销。
在下面的代码片段中,我们手动在工具节点之前引入一个断点,以便轻松地让代理运行单步。然后,我们可以检查并断言该单步之后的状态。
@pytest.mark.langsmith
def test_single_step() -> None:
state_before_tool_execution = await agent.ainvoke(
inputs,
# interrupt_before指定要在之前停止的节点
# 在工具节点之前中断可以让我们检查工具调用参数
interrupt_before=["tools"]
)
# 我们可以查看代理的消息历史,包括最新的工具调用
print(state_before_tool_execution["messages"])
3. 全代理回合让你了解完整情况

可以把单步评估看作是“单元测试”,确保代理在特定场景下采取预期的行动。同时,全代理回合也很有价值——它们能让你看到代理所采取的端到端行动的完整图景。
全代理回合可以通过多种方式测试代理行为:
-
轨迹:评估完整轨迹的一种非常常见的方式是确保在行动过程中的某个时刻调用了特定的工具,但具体何时调用并不重要。在我们的日历调度器示例中,调度器可能需要多次调用工具才能找到适合所有参与方的时间段。
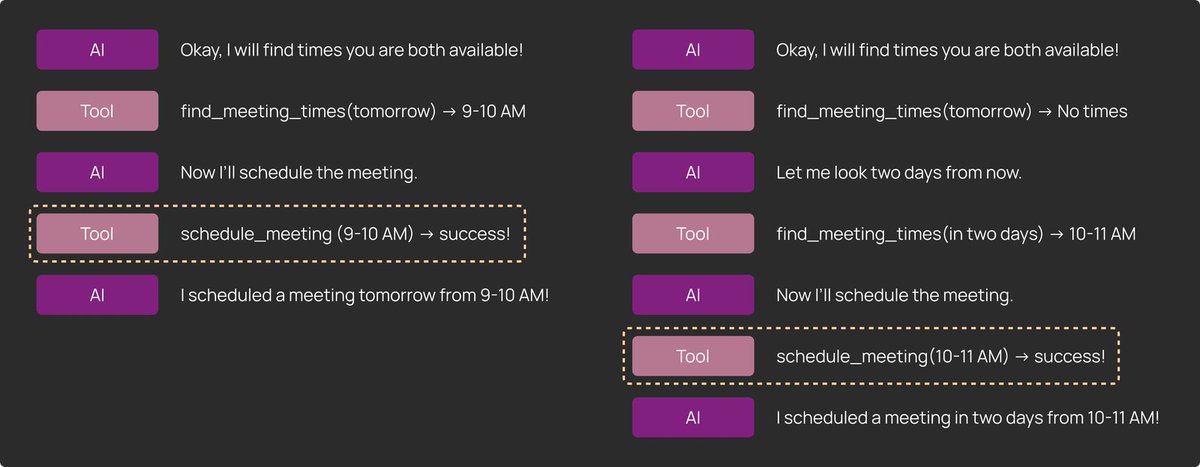
-
最终响应:在某些情况下,最终输出的质量比代理所采取的特定路径更重要。我们发现,对于编码和研究等更开放式的任务,情况确实如此。

-
其他状态:评估其他状态与评估代理的最终响应非常相似。有些代理会创建工件,而不是以聊天形式回应用户。通过在LangGraph中检查代理的状态,可以轻松检查和测试这些工件。 -
对于编码代理→读取并测试代理编写的文件。 -
对于研究代理→断言代理找到了正确的链接或来源。
-
全代理回合让你了解代理执行的完整情况。LangSmith能很容易地将你的全代理回合视为轨迹,你可以在其中查看高级指标(如延迟和令牌使用),同时还能分析具体步骤,直至每个模型调用或工具调用。
4. 跨多回合运行代理模拟完整用户交互

有些场景需要在多轮对话中测试代理,这些对话包含多个连续的用户输入。问题在于,如果你简单地硬编码一系列输入,而代理偏离了预期路径,那么后续的硬编码用户输入可能就没有意义了。
我们通过在Pytest和Vitest测试中添加条件逻辑来解决这个问题。例如,我们会:
-
运行第一个回合,然后检查代理输出。如果输出符合预期,运行下一个回合。 -
如果不符合预期,提前使测试失败。(这之所以可能,是因为我们可以在每个步骤后添加检查。)
这种方法让我们能够运行多回合评估,而不必为每个可能的代理分支建模。如果我们想单独测试第二或第三回合,我们只需从该点开始设置测试,并使用适当的初始状态。
5. 搭建合适的评估环境很重要
深度代理是有状态的,旨在处理复杂、长期运行的任务——通常需要更复杂的环境来进行评估。
与较简单的LLM评估(其环境通常仅限于少数无状态工具)不同,深度代理需要为每次评估运行提供一个全新、干净的环境,以确保结果可重复。
编码代理清楚地说明了这一点。有一个为TerminalBench提供的评估环境,它在专用的Docker容器或沙箱中运行。对于DeepAgents CLI,我们使用了一种更轻量的方法:为每个测试用例创建一个临时目录,并在其中运行代理。
更广泛地说:深度代理评估需要每个测试都重置环境——否则你的评估会变得不稳定且难以重现。
「小贴士:模拟API请求」
LangSmith Assist需要连接到真实的LangSmith API。针对实时服务运行评估可能既缓慢又昂贵。相反,我们可以将HTTP请求记录到文件系统,并在测试执行期间重放它们。对于Python,有合适的工具可以实现;对于JS,我们通过Hono应用程序代理fetch请求来实现。
模拟或重放API请求使深度代理评估更快,也更容易调试,特别是当代理严重依赖外部系统状态时。
用LangSmith评估深度代理
上述技术是我们在为基于深度代理的应用编写自己的测试套件时发现的常见模式。对于你的特定应用,你可能只需要上述模式的一个子集——因此,你的评估框架具有灵活性非常重要。如果你正在构建深度代理并开始进行评估,不妨了解一下LangSmith!
常见问题(FAQ)
什么是深度代理(Deep Agents)?
深度代理是一种能够处理复杂、长期运行任务的有状态代理,通常需要与各种工具交互,并能在运行过程中生成和处理多种状态信息,如文件、记忆等。
单步评估和全代理回合评估有什么区别?
单步评估是将代理循环限制在一个回合,用于验证特定场景下的即时决策,类似“单元测试”;全代理回合则是让代理在单个输入上完整运行,能展示端到端的行动全貌,帮助了解代理的整体执行情况。
为什么深度代理的评估需要定制化测试逻辑?
因为深度代理需要测试的内容不仅包括最终响应,还涉及轨迹和其他状态,且每个数据点的成功标准可能不同,传统统一的评估逻辑无法满足需求,所以需要为每个数据点定制测试逻辑。
多回合评估中如何处理代理偏离预期路径的情况?
可以在测试中添加条件逻辑,运行每个回合后检查代理输出,若符合预期则继续下一个回合,若不符合则提前让测试失败,无需为所有可能的分支建模。
为什么深度代理评估需要干净的环境?
深度代理是有状态的,若环境不重置,之前的测试残留可能影响后续评估结果,导致评估不稳定、不可重现,所以每次评估都需要干净的环境。
