你好,我是这篇博客的作者,一个专注于机器学习和数据科学的从业者。今天,我想和你聊聊 TabPFN-2.5,这是一个专为表格数据设计的模型。最近,Prior Labs 发布了这个版本,它在处理更大规模数据的同时,保持了简单高效的特性。如果你正处理财务、医疗或工业领域的表格数据,这个模型可能会让你眼前一亮。让我们一步步来了解它,从基础概念到实际应用,我会尽量用通俗的话解释清楚,就像我们在讨论一个新工具时那样。
首先,你可能会问:什么是 TabPFN?TabPFN 是一个表格基础模型(Tabular Foundation Model),它不像传统的机器学习模型那样需要针对每个数据集反复训练。它通过“上下文学习”(in-context learning)来工作——简单来说,就是把训练数据和测试数据一起输入模型,它通过一次前向传播就给出预测。这听起来有点神奇,但它基于Transformer架构,预先在合成数据上训练过,能处理各种表格任务。
TabPFN 的演进:从 v1 到 2.5
如果你是第一次接触 TabPFN,让我们回顾一下它的历史。这能帮助你理解为什么 2.5 版本是个大进步。
早期的 TabPFN(v1)证明了 Transformer 可以学习贝叶斯式的推理,用于合成表格任务。它只能处理大约 1000 个样本,且只支持干净的数值特征。接着,TabPFNv2 扩展了这个能力,能处理真实世界的数据,包括分类特征、缺失值和异常值。它支持最多 10,000 个样本和 500 个特征。
现在,TabPFN-2.5 是这一系列的最新版本。它推荐用于最多 50,000 个样本和 2,000 个特征的数据集——比 v2 增加了 5 倍行数和 4 倍列数,相当于数据单元增加了约 20 倍。你可以通过 Python 的 tabpfn 包或 API 来使用它。
这里有一个表格,比较了不同版本的关键方面:
| 方面 | TabPFN (v1) | TabPFNv2 | TabPFN-2.5 |
|---|---|---|---|
| 推荐最大行数 | 1,000 | 10,000 | 50,000 |
| 推荐最大特征数 | 100 | 500 | 2,000 |
| 支持数据类型 | 仅数值 | 混合 | 混合 |
从这个表格可以看到,2.5 版本在规模上有了显著提升,同时保持了无训练的工作流程。这意味着你不用为每个数据集调整超参数或运行梯度下降。
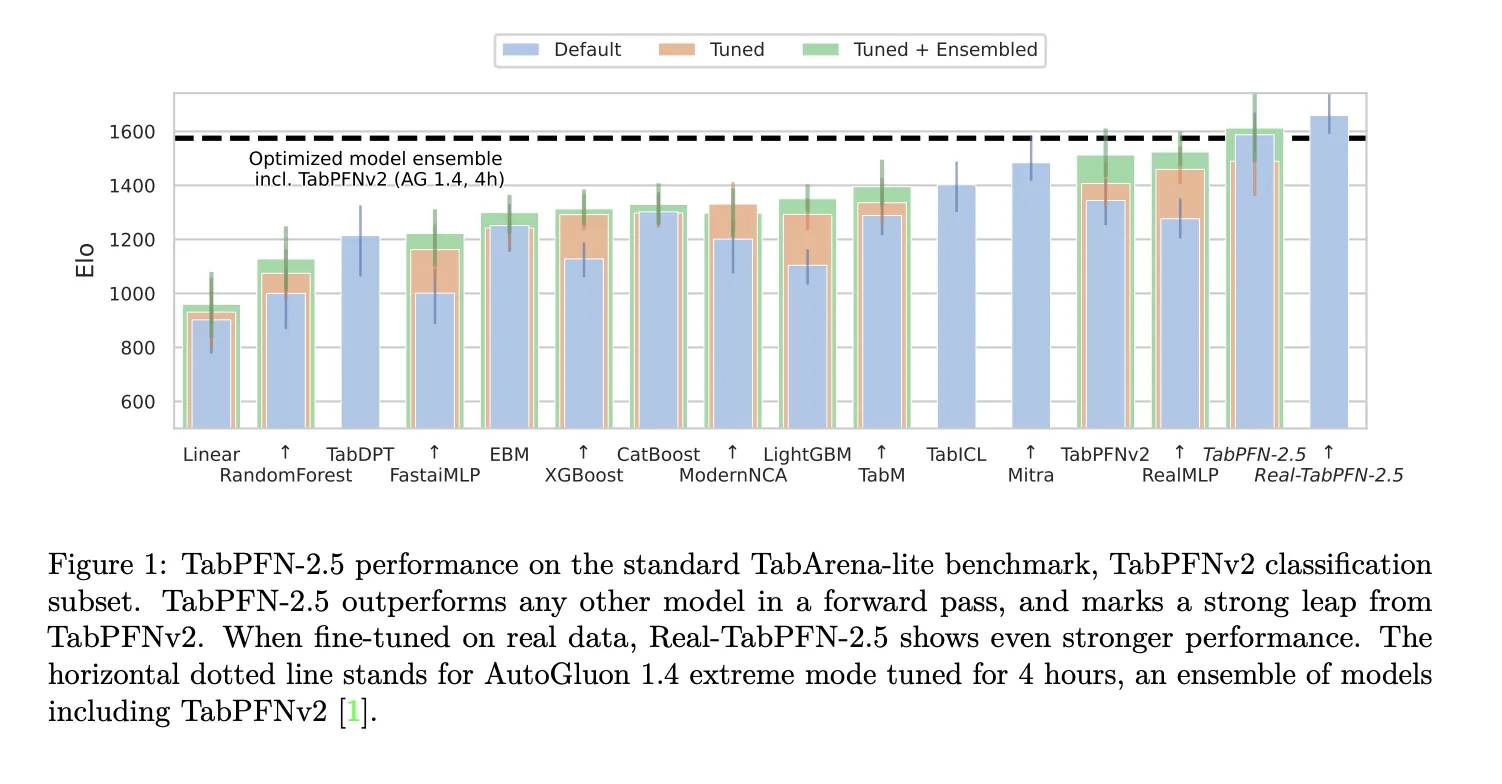
(图片来源:Prior Labs 技术报告,展示了模型的性能表现。)
TabPFN-2.5 如何工作?
你可能好奇:这个模型是怎么做到不用训练就预测的?核心是“先验数据拟合网络”(prior data fitted network)。在训练阶段,模型在大量合成表格任务上进行元训练。这些任务模拟各种函数和数据分布。在推理时,你把训练行、标签和测试行一起输入,模型通过一次前向传播输出预测。
这种上下文学习特别适合表格数据,因为表格的行和列顺序通常不重要。模型使用交替注意力机制:分别在样本轴和特征轴上注意力,这确保了行和列的置换不变性。
训练设置保持了先验数据的理念。TabPFN-2.5 在合成任务上训练,而 Real-TabPFN-2.5 则在真实数据集上继续预训练(避免与评估基准重叠)。

(图片来源:Prior Labs 技术报告,展示了模型的架构细节。)
基准测试结果:它真的有效吗?
性能是大家最关心的。Prior Labs 在几个基准上测试了 TabPFN-2.5。
在 TabArena Lite 基准(中等规模任务,最多 10,000 样本和 500 特征)上,TabPFN-2.5 在一次前向传播中超越了其他模型。Real-TabPFN-2.5(在真实数据上微调)表现更好。相比之下,AutoGluon 1.4(一个调优 4 小时的复杂集成,包括 TabPFNv2)是基线。
在行业标准基准(最多 50,000 数据点和 2,000 特征)上,TabPFN-2.5 显著优于调优的树模型如 XGBoost 和 CatBoost。它匹配了 AutoGluon 1.4 的准确性,而后者需要复杂的调优。
在 RealCause 基准上,也显示出类似优势。总之,这个模型在中等规模数据集上提供了强有力的性能,而无需调优。
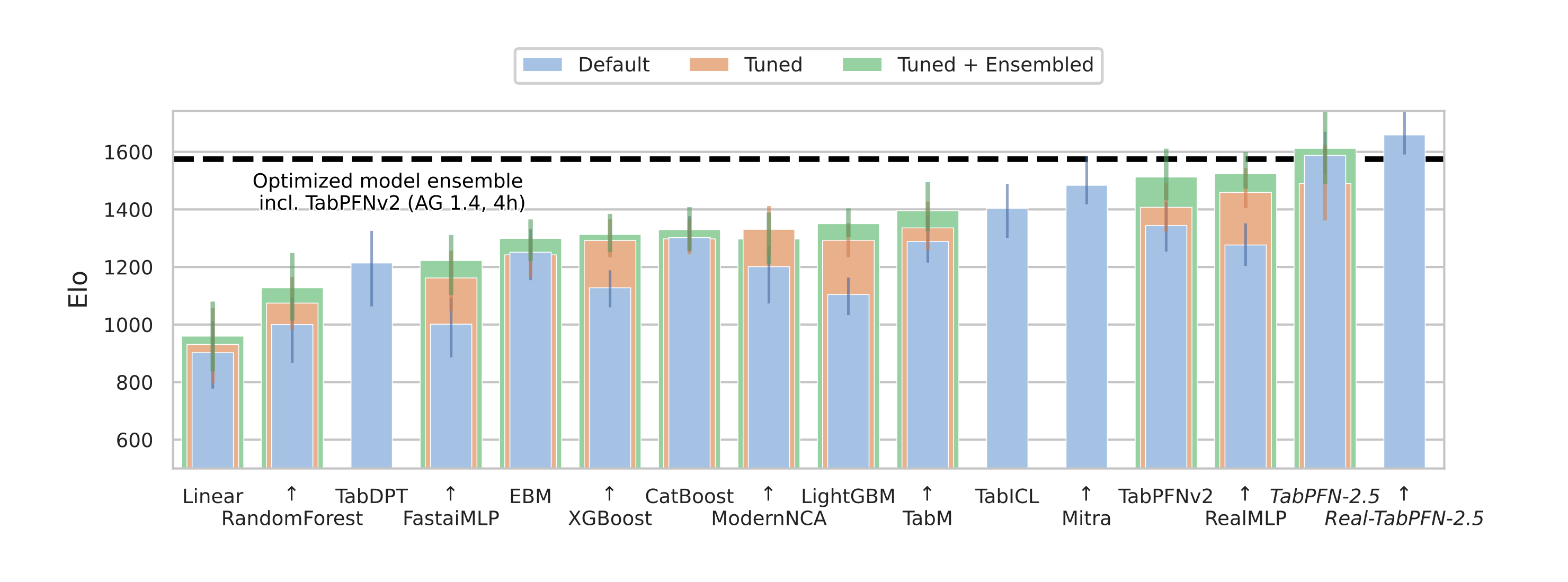
(图片来源:Prior Labs,展示了在 TabArena-lite 基准上的性能比较。TabPFN-2.5 超越了其他模型,Real-TabPFN-2.5 更进一步。虚线代表 AutoGluon 1.4 的表现。)
模型架构和训练细节
架构基于 TabPFNv2,使用 18 到 24 层的交替注意力。这确保了表格的置换不变性——行和列的顺序不影响结果。
训练上,模型在合成表格任务上元训练,覆盖不同函数和分布的先验。Real-TabPFN-2.5 使用来自 OpenML 和 Kaggle 的真实数据集继续预训练。
一个新特性是蒸馏引擎:它将 TabPFN-2.5 转换为紧凑的 MLP 或树集成,保留大部分准确性,同时显著降低延迟,便于部署。
关键要点:为什么选择 TabPFN-2.5?
如果你在考虑是否使用它,这里是几个关键点:
-
规模扩展:处理最多 50,000 样本和 2,000 特征,同时保持一次前向传播、无调优的工作流程。
-
基准表现:在 TabArena、行业基准和 RealCause 上,优于调优树模型,匹配 AutoGluon 1.4。
-
架构优势:交替注意力 Transformer 确保置换不变性,支持上下文学习,无需特定任务训练。
-
蒸馏引擎:转换为 MLP 或树集成,降低延迟,便于集成现有表格栈。
总体来说,TabPFN-2.5 将模型选择和超参数调优简化为一次前向传播,适用于真实表格问题。它有清晰的非商业许可和企业路径。
如何安装和使用 TabPFN?
现在,让我们谈谈实际操作。如果你想试用 TabPFN-2.5,这里是安装和使用的步骤。基于 Python,我会一步步说明。
安装步骤
-
官方安装(通过 pip):
pip install tabpfn -
从源安装:
pip install "tabpfn @ git+https://github.com/PriorLabs/TabPFN.git" -
本地开发安装:
git clone https://github.com/PriorLabs/TabPFN.git --depth 1 pip install -e "TabPFN[dev]"
安装后,你可以下载模型权重。TabPFN-2.5 默认使用 Hugging Face 的权重,需要接受许可条款。访问 https://huggingface.co/Prior-Labs/tabpfn_2_5 并登录。
如果没有互联网,可以手动下载权重:
-
分类器:tabpfn-v2.5-classifier-v2.5_default.ckpt(默认使用真实数据微调的模型)。
-
回归器:tabpfn-v2.5-regressor-v2.5_default.ckpt。
放置在缓存目录,或设置环境变量 TABPFN_MODEL_CACHE_DIR="/path/to/dir"。
分类示例
假设你有乳腺癌数据集:
from sklearn.datasets import load_breast_cancer
from sklearn.metrics import accuracy_score, roc_auc_score
from sklearn.model_selection import train_test_split
from tabpfn import TabPFNClassifier
from tabpfn.constants import ModelVersion
# 加载数据
X, y = load_breast_cancer(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5, random_state=42)
# 初始化分类器(使用 TabPFN-2.5,默认真实数据微调)
clf = TabPFNClassifier()
# 要使用 TabPFNv2:
# clf = TabPFNClassifier.create_default_for_version(ModelVersion.V2)
clf.fit(X_train, y_train)
# 预测概率
prediction_probabilities = clf.predict_proba(X_test)
print("ROC AUC:", roc_auc_score(y_test, prediction_probabilities[:, 1]))
# 预测标签
predictions = clf.predict(X_test)
print("Accuracy", accuracy_score(y_test, predictions))
回归示例
使用波士顿房价数据集:
from sklearn.datasets import fetch_openml
from sklearn.metrics import mean_squared_error, r2_score
from sklearn.model_selection import train_test_split
from tabpfn import TabPFNRegressor
from tabpfn.constants import ModelVersion
# 加载数据
df = fetch_openml(data_id=531, as_frame=True) # Boston Housing dataset
X = df.data
y = df.target.astype(float)
# 分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5, random_state=42)
# 初始化回归器(使用 TabPFN-2.5,仅合成数据训练)
regressor = TabPFNRegressor()
# 要使用 TabPFNv2:
# regressor = TabPFNRegressor.create_default_for_version(ModelVersion.V2)
regressor.fit(X_train, y_train)
# 预测
predictions = regressor.predict(X_test)
# 评估
mse = mean_squared_error(y_test, predictions)
r2 = r2_score(y_test, predictions)
print("Mean Squared Error (MSE):", mse)
print("R² Score:", r2)
推荐使用 GPU(即使是 8GB VRAM 的旧卡也行;大数据集需 16GB)。在 CPU 上,只适合小数据集(<1000 样本)。无 GPU 时,用 TabPFN Client 云推理。
保存和加载模型
要保存拟合模型:
from tabpfn import TabPFNRegressor
from tabpfn.model_loading import (
load_fitted_tabpfn_model,
save_fitted_tabpfn_model,
)
# 在 GPU 上训练
reg = TabPFNRegressor(device="cuda")
reg.fit(X_train, y_train)
save_fitted_tabpfn_model(reg, "my_reg.tabpfn_fit")
# 后来在 CPU 上加载
reg_cpu = load_fitted_tabpfn_model("my_reg.tabpfn_fit", device="cpu")
仅保存基础权重:
save_tabpfn_model(reg.model_, "my_tabpfn.ckpt")
# 加载:load_model_criterion_config
TabPFN 生态系统:扩展你的能力
TabPFN 不只是一个模型,还有生态系统支持不同需求。
-
TabPFN Client:云 API 客户端,无需本地 GPU。GitHub:https://github.com/priorlabs/tabpfn-client
-
TabPFN Extensions:高级工具,包括解释性(SHAP、特征重要性)、无监督(异常检测、合成数据生成)、嵌入提取、多类分类、随机森林混合、HPO 和后置集成。
安装:
git clone https://github.com/priorlabs/tabpfn-extensions.git pip install -e tabpfn-extensions -
TabPFN UX:无代码图形界面,适合原型设计。访问:https://ux.priorlabs.ai
-
TabPFN 时间序列:处理时间序列数据。GitHub:https://github.com/PriorLabs/tabpfn-time-series
工作流程决策树(Mermaid 图)帮助你选择路径,从 GPU 检查到解释性需求。
许可和社区
TabPFN-2.5 权重是非商业许可。代码和 v2 权重是 Prior Labs 许可(Apache 2.0 加归属)。
加入社区:Discord(https://discord.gg/BHnX2Ptf4j)、文档(https://priorlabs.ai/docs)、GitHub Issues。
引用论文:
@article{hollmann2025tabpfn,
title={Accurate predictions on small data with a tabular foundation model},
author={Hollmann, Noah and Müller, Samuel and Purucker, Lennart and
Krishnakumar, Arjun and Körfer, Max and Hoo, Shi Bin and
Schirrmeister, Robin Tibor and Hutter, Frank},
journal={Nature},
year={2025},
month={01},
day={09},
doi={10.1038/s41586-024-08328-6},
publisher={Springer Nature},
url={https://www.nature.com/articles/s41586-024-08328-6},
}
@inproceedings{hollmann2023tabpfn,
title={TabPFN: A transformer that solves small tabular classification problems in a second},
author={Hollmann, Noah and Müller, Samuel and Eggensperger, Katharina and Hutter, Frank},
booktitle={International Conference on Learning Representations 2023},
year={2023}
}
常见问题解答(FAQ)
TabPFN-2.5 适合什么数据集大小?
它优化用于最多 50,000 行。对于更大数据集,用随机森林预处理或扩展。见 Colab 笔记本示例。
为什么 TabPFN 需要 Python 3.9+?
它依赖新语言特性。支持 3.9 到 3.13。
如何获取 TabPFN-2.5 访问权限?
访问 Hugging Face https://huggingface.co/Prior-Labs/tabpfn_2_5 接受条款。联系 sales@priorlabs.ai 如果问题。
如何在无互联网下使用?
用脚本下载所有模型:
python scripts/download_all_models.py
或手动下载并放置在缓存目录。
加载模型时出现 pickle 错误怎么办?
升级 tabpfn:pip install tabpfn –upgrade。重新下载模型文件。
哪些环境变量可以配置 TabPFN?
-
TABPFN_MODEL_CACHE_DIR:模型缓存目录。
-
TABPFN_ALLOW_CPU_LARGE_DATASET:允许 CPU 处理大数据集(true),但很慢。
-
PYTORCH_CUDA_ALLOC_CONF:GPU 内存配置,默认 max_split_size_mb:512。
TabPFN 处理缺失值吗?
是的,它支持缺失值、分类特征和异常值。
如何改善 TabPFN 性能?
用 AutoTabPFNClassifier 进行后置集成。添加领域特定特征。不要调整缩放或编码分类特征。
TabPFN 支持无监督任务吗?
通过扩展:插值、数据生成、异常检测、嵌入提取等。
如何处理多于 10 类的分类?
用 many_class 方法从扩展中。
需要微调吗?
可选。通过 finetuning 示例。
如何解释模型?
用 SHAP、部分依赖图、特征选择从扩展中。
如何处理大数据集(>10k 样本)?
用 subsample 指南或 large_datasets 示例。
如何加速推理?
启用 KV 缓存:fit_mode=’fit_with_cache’。增加内存但更快预测。
遥测如何工作?
匿名收集使用数据。设置 TABPFN_DISABLE_TELEMETRY=1 禁用。
结语:TabPFN-2.5 的潜力
TabPFN-2.5 让表格机器学习更简单高效,尤其在中等规模数据上。它从证明概念到实用工具的演进,展示了基础模型在表格领域的潜力。如果你处理表格数据,不妨试试——从安装开始,看看它如何简化你的工作流。有什么问题,欢迎在评论或社区讨论。我会继续关注这个领域的进展,下次见!
(字数统计:约 4200 字)
