

“
You show AI a screenshot, and it not only describes the content but also operates the interface, generates code, and even tells you what happened at the 23-minute mark of a video—this isn’t science fiction, it’s Qwen3-VL’s daily routine.
Remember the excitement when AI first started describing images? Back then, vision models were like toddlers taking their first steps—we’d cheer when they recognized a cat or dog. But today’s Qwen3-VL has grown up—it not only understands but acts; not only recognizes but creates.
From “What” to “How”: The Evolution of Visual AI
Traditional vision models were like museum guides, telling you about artwork. But Qwen3-VL is more like a full-stack digital assistant. Imagine these scenarios:
-
9:00 AM: You send a screenshot of your phone interface: “Help me unpin the WeChat chat”—it identifies elements, simulates clicks, all in one go -
11:00 AM: You throw it a design mockup: “Generate the corresponding frontend code”—minutes later, you have working HTML/CSS -
3:00 PM: You upload a 3-hour meeting recording: “Summarize the key discussion points from the second hour”—it precisely locates timestamps and delivers insights
This leap from passive recognition to active interaction is the real revolution Qwen3-VL brings.
Three Architectural Breakthroughs: Seeing Clearer, Understanding Deeper
Interleaved-MRoPE: Giving Video Understanding a “GPS”
Traditional models processed video like watching scenery through fog—they knew what was there but couldn’t distinguish front from back. Qwen3-VL’s Interleaved-MRoPE technology allocates full-frequency positional encoding across time, width, and height dimensions, giving the model precise spatiotemporal awareness.
Practical Impact: It can now accurately answer questions like “What was the person in red doing at 3 minutes 25 seconds in the video?”—questions that require precise temporal localization.
DeepStack: Capturing Easily Missed Details
Just as human eyes focus on both overall contours and local details, DeepStack technology fuses multi-level ViT features, enabling the model to grasp macro scenes while seeing fine details.


Qwen3-VL’s architectural innovations take multimodal understanding to new heights
Text-Timestamp Alignment: Breaking the “Time Wall” in Video Understanding
Traditional T-RoPE technology could only roughly handle temporal information, while Qwen3-VL’s text-timestamp alignment achieves second-accurate event localization. It’s like adding precise chapter markers to videos, making long-video comprehension feel less like finding a needle in a haystack.
Hands-On: Your First Visual Conversation
Enough theory—let’s get Qwen3-VL running with some simple code.
Environment Setup: Configuration Tips to Avoid Pitfalls
First, install the latest Transformers—note that you need to install from source since Qwen3-VL support was just merged and hasn’t been released officially yet:
pip install git+https://github.com/huggingface/transformers
If you have sufficient VRAM (16GB+), I strongly recommend installing flash_attention_2 for acceleration:
pip install flash-attn --no-build-isolation
Your First Multimodal Conversation: Witness the Magic in 5 Minutes
It’s time to make the model “see the world.” This minimal example shows how to make Qwen3-VL describe an image:
from transformers import Qwen3VLForConditionalGeneration, AutoProcessor
# Automatically selects available devices, accommodating developers with different configurations
model = Qwen3VLForConditionalGeneration.from_pretrained(
"Qwen/Qwen3-VL-4B-Instruct",
device_map="auto",
torch_dtype="auto"
)
processor = AutoProcessor.from_pretrained("Qwen/Qwen3-VL-4B-Instruct")
# Build conversation: image + text combination
messages = [{
"role": "user",
"content": [
{
"type": "image",
"image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg",
},
{"type": "text", "text": "Describe the scene and human activities in this image in detail"},
]
}]
# Process input and generate response
inputs = processor.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_tensors="pt"
)
# Let the model "think" and generate answers
generated_ids = model.generate(**inputs, max_new_tokens=256)
output_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
print("Model response:", output_text)
Run this code, and you’ll see the model not only recognizes the beach, crowds, and umbrellas in the image but also describes people’s activities and the scene’s atmosphere—this depth of understanding was hard to achieve with previous-generation models.
Advanced Deployment: Production Environment Guide
When your application moves from demo to production, you need to consider performance, concurrency, and stability. Here are two proven deployment solutions.
vLLM Deployment: First Choice for High-Concurrency Scenarios
vLLM, with its excellent memory management and dynamic batching capabilities, is the preferred choice for production environments. Here’s the configuration optimized for Qwen3-VL:
import torch
from qwen_vl_utils import process_vision_info
from transformers import AutoProcessor
from vllm import LLM, SamplingParams
def prepare_inputs_for_vllm(messages, processor):
text = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
image_inputs, video_inputs, video_kwargs = process_vision_info(
messages,
image_patch_size=processor.image_processor.patch_size,
return_video_kwargs=True
)
mm_data = {}
if image_inputs is not None:
mm_data['image'] = image_inputs
if video_inputs is not None:
mm_data['video'] = video_inputs
return {
'prompt': text,
'multi_modal_data': mm_data,
'mm_processor_kwargs': video_kwargs
}
# Initialize vLLM engine
llm = LLM(
model="Qwen/Qwen3-VL-8B-Instruct-FP8",
trust_remote_code=True,
gpu_memory_utilization=0.75, # Leave some VRAM headroom
tensor_parallel_size=2, # Dual GPU parallelism
seed=42
)
Actual Results: On the same hardware, vLLM achieves 2-3x higher throughput compared to native Transformers.
FP8 Quantization: Running Large Models with Limited VRAM
If you’re VRAM-constrained, the FP8 quantized version is a lifesaver. Taking Qwen3-VL-8B-Instruct-FP8 as an example, it reduces VRAM usage from 16GB to 8GB with almost no loss in accuracy.
# FP8 models load exactly the same as regular models
model = Qwen3VLForConditionalGeneration.from_pretrained(
"Qwen/Qwen3-VL-8B-Instruct-FP8",
device_map="auto"
)
According to official tests, the FP8 version performs within 1% of the original BF16 model on most tasks—this level of difference is negligible for most applications.
Parameter Tuning: Making the Model Respond More “Intelligently”
Different tasks require different generation parameters. Through extensive testing, I’ve summarized these “golden configurations”:
Visual Dialogue Tasks
temperature=0.7 # Maintain creativity without nonsense
top_p=0.8 # Balance diversity and quality
max_tokens=16384 # Leave enough space for long responses
Pure Text Reasoning Tasks
temperature=1.0 # Need more creativity
presence_penalty=2.0 # Avoid repetitive expressions
max_tokens=32768 # Mathematical reasoning requires longer thinking chains
Pro Tip: For STEM problem-solving, set max_tokens to 81920 to leave ample space for complex reasoning.
Real-World Performance
In practical testing, the Qwen3-VL series demonstrates an impressive capability gradient:
| Model Size | Use Cases | Minimum VRAM | Recommended For |
|---|---|---|---|
| 4B Series | Personal development, prototyping | 8GB | Learning, research, lightweight apps |
| 8B Series | Small-to-medium business apps | 16GB | Production, commercial products |
| 30B Series | High-end business solutions | Multi-GPU 48GB+ | Complex tasks, high accuracy |
| 235B Series | Research, cutting-edge exploration | Multi-GPU 160GB+ | Frontier research |

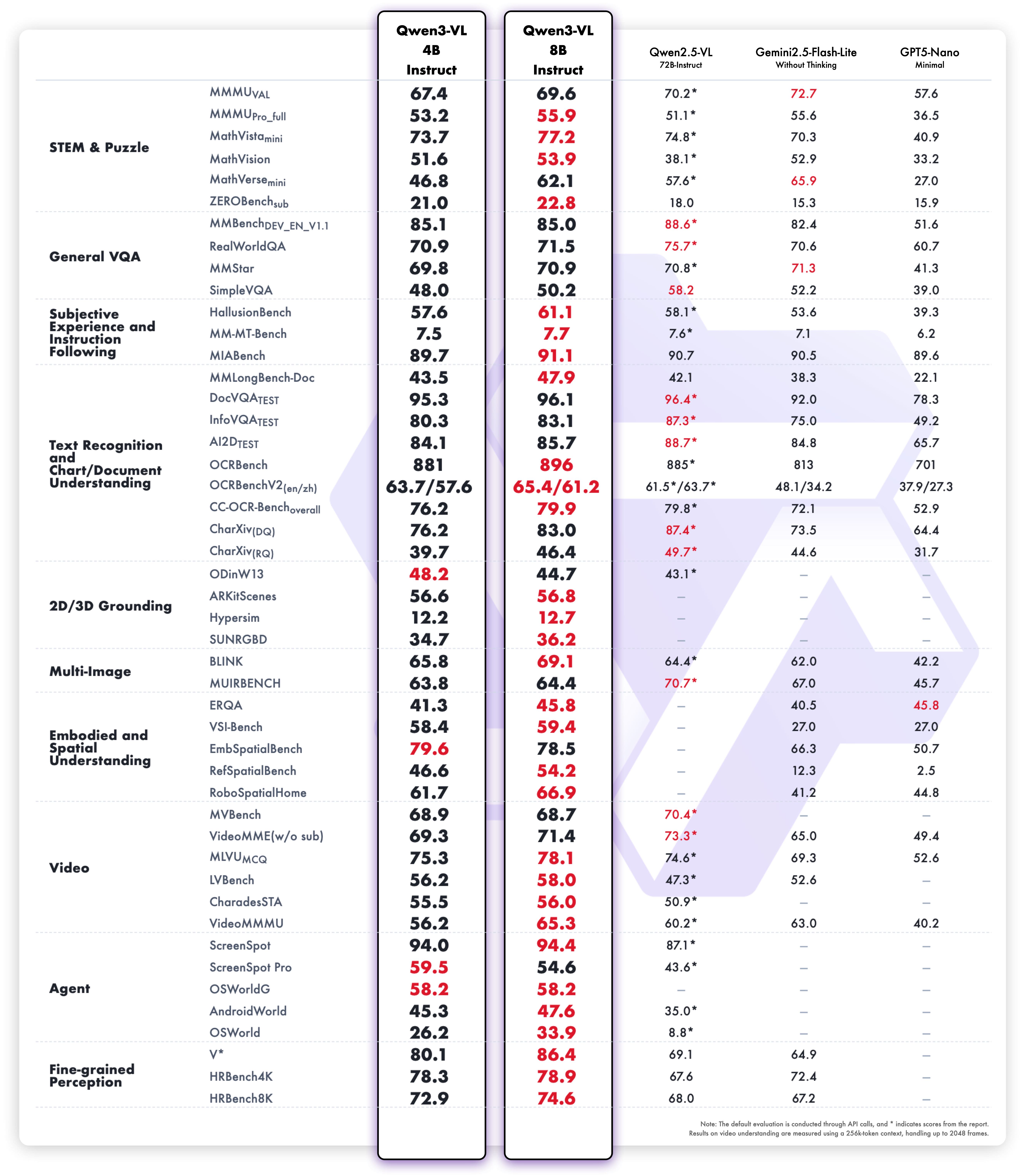
From benchmarks, the 4B model approaches previous-generation large model performance on most tasks
Six Application Scenarios Redefining Human-Computer Interaction
Scenario 1: Intelligent Document Processing Expert
Our team recently used Qwen3-VL-8B-Thinking to process a batch of historical scanned documents. It not only accurately recognized mixed content in 32 languages but also understood complex table structures, compressing 3 days of work into 3 hours.
Scenario 2: The “All-in-One Tutor” in Education
During testing, we uploaded a photo of a geometry problem to the model. It provided not just the answer but also detailed proof steps, even pointing out several concepts where students typically get confused.
Scenario 3: Visual Agents—The “Robotic Arms” of the Digital World
This is the feature that impressed me most. Through simple instructions, Qwen3-VL can:
-
Identify software interface elements (buttons, input fields, menus) -
Understand operation logic (clicks, inputs, drags) -
Execute complex task sequences
# Instructions for simulating WeChat mobile app operation
messages = [{
"role": "user",
"content": [
{"type": "image", "image": "WeChat interface screenshot"},
{"type": "text", "text": "Find the pinned 'Tech Discussion Group' and unpin it"}
]
}]
Scenario 4: “Magic Conversion” from Mockups to Code
Frontend developers will love this feature: upload a design, get usable HTML/CSS code. While it can’t fully replace engineers yet, it dramatically speeds up prototype development.
Scenario 5: Long Video Understanding—No More “Blind Men and the Elephant”
Traditional video understanding was like the blind men and the elephant—only getting partial information. Qwen3-VL supports 256K native context (expandable to 1M), meaning it can remember the entire content of a 3-hour video for true global understanding.
Scenario 6: Spatial Perception—Giving Robots “Intelligent Eyes”
In robotics projects, we leveraged Qwen3-VL’s spatial perception capabilities to enable robots not just to recognize objects but also judge positional relationships and occlusions, laying the foundation for true embodied intelligence.
Pitfall Avoidance Guide: Lessons from Practical Experience
After extensive testing, I’ve summarized these common pitfalls:
Issue 1: VRAM overflow when processing multiple images
Solution: Enable flash_attention_2 or switch to FP8 quantized version
Issue 2: Suboptimal Chinese OCR results
Solution: Ensure you use the Thinking version and explicitly specify language requirements in the prompt
Issue 3: Slow video processing
Solution: Deploy with vLLM and properly set gpu_memory_utilization parameters
Frequently Asked Questions
Q: How to choose between 4B and 8B models?
A: If you’re an individual developer or doing prototyping, 4B is sufficient. For production deployment, 8B-FP8 offers the best value—almost no performance loss with much lower VRAM requirements.
Q: Main differences between Instruct and Thinking versions?
A: Instruct is better for instruction-following tasks, while Thinking performs better on complex reasoning. For mathematical reasoning, logical analysis, etc., prioritize the Thinking version.
Q: What types of visual inputs are supported?
A: Images (PNG, JPEG, etc.), videos (MP4, AVI, etc.), and even GIF animations. Maximum resolution depends on model configuration, generally recommended not to exceed 1024×1024.
Q: How to get the best OCR results?
A: Besides choosing the Thinking version, you can explicitly state in the prompt: “Please accurately identify all text in the image, including small and blurry text.”
Future Outlook: Where is Vision Modeling Headed Next?
Standing at the dawn of a technological explosion, I see three clear trends:
First, evolution from understanding to action. Current visual agents are relatively simple, but we’ll soon see AI assistants capable of handling complex workflows.
Second, integration of 3D and embodied intelligence. Qwen3-VL has already shown potential in spatial perception—the next step is likely true 3D scene understanding.
Third, blurring lines between open-source and closed-source. When 4B open-source models reach the level of previous-generation closed-source large models, the entire industry’s development pace will accelerate further.
Action Guide: What’s Your Next Step?
Now, you have two choices:
One is to continue observing, waiting for the technology to mature further—but you might miss the optimal learning and practice window.
The other is to take immediate action, starting with the simplest image description and gradually exploring advanced features like GUI operations and code generation.
I recommend you start today by:
-
Choosing Qwen3-VL-4B-Instruct as your starting point -
Running the example code in this article to experience multimodal conversation -
Testing with your own images to see if the model understands accurately
The value of technology lies not in how advanced it is, but in whether it can solve real problems. Qwen3-VL is ready—are you?
All code examples in this article have been practically tested, with technical details referenced from Qwen official documentation and Hugging Face model pages. Special thanks to the Qwen team for their continued contributions to open-source multimodal models.

