

A Comprehensive Guide to Qwen3-Next-80B-A3B-Thinking: Technical Breakthroughs and Practical Applications
In the rapidly evolving field of artificial intelligence, large language models are advancing toward larger parameter scales and stronger contextual processing capabilities. The model we’re exploring today—Qwen3-Next-80B-A3B-Thinking—represents a significant achievement in this trend. Whether you’re an AI developer, researcher, or someone interested in cutting-edge technology, this article will provide a thorough analysis of this model’s technical characteristics, performance, and practical application methods.
What is Qwen3-Next-80B-A3B-Thinking?
Qwen3-Next-80B-A3B-Thinking is the first version in the Qwen team’s new generation of foundation model series. This model is specifically optimized for complex reasoning tasks, achieving remarkable improvements in both parameter efficiency and inference speed.
Simply put, it’s like an artificial intelligence brain with supercharged thinking capabilities. Unlike standard models that output answers directly, this model first “thinks,” generating an internal reasoning process before providing the final answer. This mechanism makes it particularly effective at handling mathematical problems, programming challenges, and complex logical reasoning.

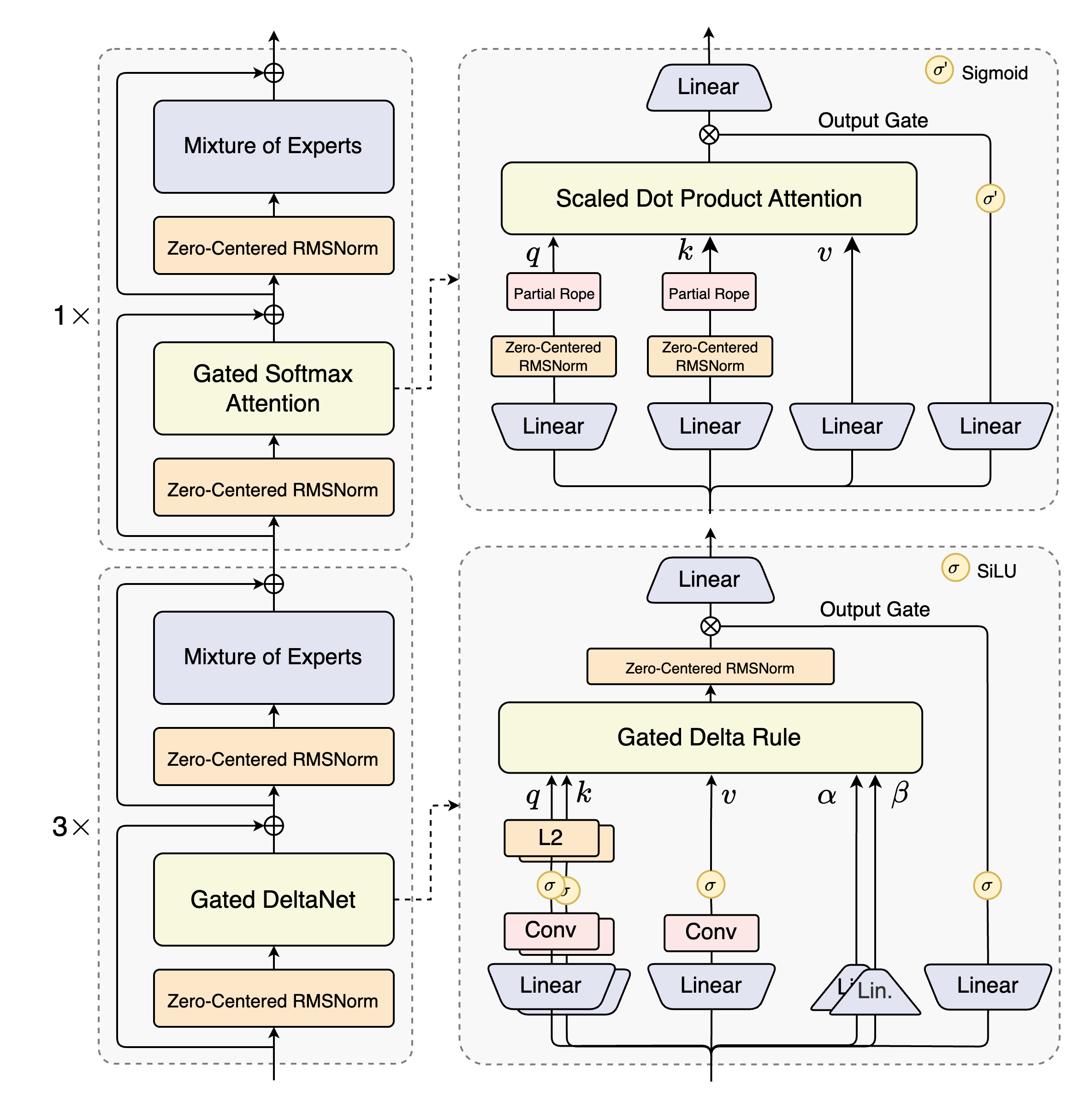
Core Technical Breakthroughs
Hybrid Attention Mechanism: Efficient Long-Text Processing
Traditional language models often face efficiency bottlenecks when processing long texts. Qwen3-Next addresses this through an innovative hybrid attention mechanism:
-
Gated DeltaNet: Specifically handles ultra-long contexts, efficiently capturing long-range dependencies in text -
Gated Attention: Provides precise attention calculations when needed, ensuring model comprehension accuracy
This combination works like an expert reader who can quickly skim long documents to grasp the overall structure while pausing to carefully examine key details.
High-Sparsity Mixture of Experts: Intelligent Parameter Activation
Imagine that when solving different problems, your brain doesn’t activate all neurons but instead calls upon relevant knowledge modules based on the task type. Qwen3-Next’s MoE architecture operates on a similar principle:
-
Total parameters reach 80 billion, but only 3 billion are activated during each inference -
Contains 512 expert networks, with only the 10 most relevant experts called upon each time -
Includes 1 shared expert to ensure stability of basic capabilities
This design significantly reduces computational costs, enabling this massive model to operate at considerable speeds.
Multi-Token Prediction: Accelerating Inference
Multi-token prediction technology allows the model to predict multiple subsequent tokens simultaneously, similar to how experienced readers can anticipate upcoming content. While this feature isn’t yet fully available in Hugging Face Transformers, it already delivers noticeable results in dedicated inference frameworks.
Stability Optimization: More Reliable Training and Results
Through techniques like zero-centered and weight-decayed layer normalization, the model maintains better stability during training and fine-tuning, meaning developers can obtain more consistent and reliable results.
Performance Metrics: Let the Data Speak
To objectively demonstrate the actual capabilities of Qwen3-Next-80B-A3B-Thinking, let’s examine detailed performance comparison data:
| Domain | Benchmark | Qwen3-30B-A3B-Thinking | Qwen3-32B-Thinking | Gemini-2.5-Flash-Thinking | Qwen3-Next-80B-A3B-Thinking |
|---|---|---|---|---|---|
| Knowledge | MMLU-Pro | 80.9 | 79.1 | 81.9 | 82.7 |
| Math Reasoning | AIME25 | 85.0 | 72.9 | 72.0 | 87.8 |
| Coding | LiveCodeBench | 66.0 | 60.6 | 61.2 | 68.7 |
| Code Generation | OJBench | 25.1 | 24.1 | 23.5 | 29.7 |
| Instruction Following | IFEval | 88.9 | 85.0 | 89.8 | 88.9 |
| Agent Tasks | TAU1-Retail | 67.8 | 52.8 | 65.2 | 69.6 |

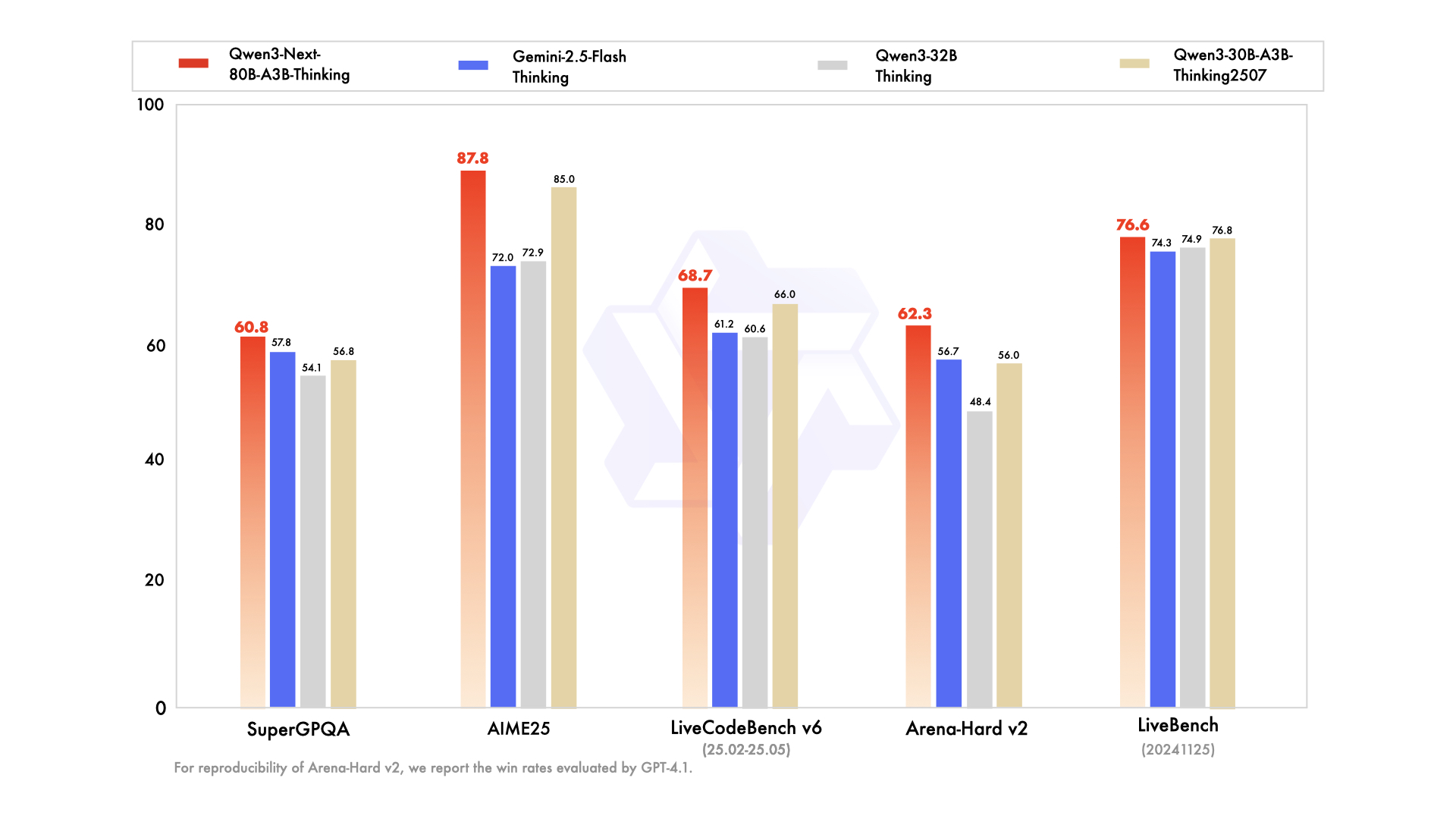
The data clearly shows that Qwen3-Next outperforms previous-generation models and competitors in most test categories, with particularly outstanding performance in mathematical reasoning and programming tasks.
How to Get Started Quickly?
Environment Setup and Basic Configuration
To begin using Qwen3-Next-80B-A3B-Thinking, first install the latest version of Hugging Face Transformers:
pip install git+https://github.com/huggingface/transformers.git@main
Please note that using older versions will result in a KeyError: 'qwen3_next' error, as model architecture definitions require the latest support.
Basic Usage Code Example
Here’s a complete usage example showing how to load the model and generate content with thinking processes:
from transformers import AutoModelForCausalLM, AutoTokenizer
# Load model and tokenizer
model_name = "Qwen/Qwen3-Next-80B-A3B-Thinking"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
dtype="auto",
device_map="auto"
)
# Prepare input
prompt = "Explain the application prospects of artificial intelligence in the healthcare field."
messages = [
{"role": "user", "content": prompt},
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# Generate response
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768,
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# Parse thinking content and final response
try:
index = len(output_ids) - output_ids[::-1].index(151668) # 151668 corresponds to </think>
except ValueError:
index = 0
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
final_content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")
print("Thinking process:", thinking_content)
print("Final response:", final_content)
It’s important to note that the model’s output automatically includes thinking processes but will only show the closing </think> tag, which is normal behavior.
Efficient Deployment Solutions
For production environments, we recommend using specialized inference frameworks for optimal performance.
Deployment with SGLang
SGLang is an efficient serving framework specifically designed for large language models:
# Install SGLang
pip install 'sglang[all]>=0.5.2'
# Start service (4 GPU parallel)
python -m sglang.launch_server --model-path Qwen/Qwen3-Next-80B-A3B-Thinking --port 30000 --tp-size 4 --context-length 262144 --reasoning-parser deepseek-r1 --mem-fraction-static 0.8
To enable multi-token prediction optimization:
python -m sglang.launch_server --model-path Qwen/Qwen3-Next-80B-A3B-Thinking --port 30000 --tp-size 4 --context-length 262144 --reasoning-parser deepseek-r1 --mem-fraction-static 0.8 --speculative-algo NEXTN --speculative-num-steps 3 --speculative-eagle-topk 1 --speculative-num-draft-tokens 4
Deployment with vLLM
vLLM is another popular high-throughput inference engine:
# Install vLLM
pip install 'vllm>=0.10.2'
# Start basic service
vllm serve Qwen/Qwen3-Next-80B-A3B-Thinking --port 8000 --tensor-parallel-size 4 --max-model-len 262144 --reasoning-parser deepseek_r1
# Enable MTP optimization
vllm serve Qwen/Qwen3-Next-80B-A3B-Thinking --port 8000 --tensor-parallel-size 4 --max-model-len 262144 --reasoning-parser deepseek_r1 --speculative-config '{"method":"qwen3_next_mtp","num_speculative_tokens":2}'
Important reminder: The model natively supports 256K context length. If you encounter out-of-memory issues, you can appropriately reduce the context length, but to ensure reasoning quality, we recommend maintaining at least 131,072 length.
Building Agent Applications
Qwen3-Nextexcels in tool calling capabilities. Combined with the Qwen-Agent framework, you can easily build complex agent applications:
from qwen_agent.agents import Assistant
# Configure model (using DashScope service)
llm_cfg = {
'model': 'Qwen3-Next-80B-A3B-Thinking',
'model_type': 'qwen_dashscope',
}
# Or use locally deployed OpenAI-compatible interface
# llm_cfg = {
# 'model': 'Qwen3-Next-80B-A3B-Thinking',
# 'model_server': 'http://localhost:8000/v1',
# 'api_key': 'EMPTY',
# }
# Define available tools
tools = [
{'mcpServers': {
'time': {
'command': 'uvx',
'args': ['mcp-server-time', '--local-timezone=Asia/Shanghai']
},
"fetch": {
"command": "uvx",
"args": ["mcp-server-fetch"]
}
}},
'code_interpreter', # Built-in code interpreter
]
# Create agent
agent = Assistant(llm=llm_cfg, function_list=tools)
# Run conversation
messages = [{'role': 'user', 'content': 'Please get the current time and briefly introduce the latest developments of Qwen'}]
for response in agent.run(messages=messages):
# Handle streaming response
pass
print(response)
Technical Solutions for Processing Ultra-Long Texts
Qwen3-Next natively supports context lengths of up to 262,144 tokens, but if you need to process even longer documents (such as reaching 1 million words), you can use YaRN extension technology.
Configuring YaRN Context Extension
There are two methods to enable YaRN:
Method 1: Modify model configuration file
Add to the model’s config.json:
{
"rope_scaling": {
"rope_type": "yarn",
"factor": 4.0,
"original_max_position_embeddings": 262144
}
}
Method 2: Through command line parameters
vLLM users:
VLLM_ALLOW_LONG_MAX_MODEL_LEN=1 vllm serve ... --rope-scaling '{"rope_type":"yarn","factor":4.0,"original_max_position_embeddings":262144}' --max-model-len 1010000
SGLang users:
SGLANG_ALLOW_OVERWRITE_LONGER_CONTEXT_LEN=1 python -m sglang.launch_server ... --json-model-override-args '{"rope_scaling":{"rope_type":"yarn","factor":4.0,"original_max_position_embeddings":262144}}' --context-length 1010000
Important note: Current open-source YaRN implementations use static scaling, meaning scaling factors are applied even when processing short texts, which may affect short-text processing performance. We recommend enabling this feature only when long-text processing is truly necessary and adjusting the scaling factor according to actual needs.
Best Practices Guide
To achieve optimal model performance, we recommend the following configurations and practical methods:
Sampling Parameter Settings
-
Temperature: 0.6 – Balances creativity and consistency -
TopP: 0.95 – Maintains output diversity -
TopK: 20 – Limits candidate word range -
MinP: 0 – No minimum probability threshold
If you encounter repetitive generation issues, you can appropriately adjust the presence_penalty parameter (between 0-2), but note that values that are too high may cause language mixing or performance degradation.
Output Length Recommendations
-
Regular tasks: 32,768 tokens – Suitable for most application scenarios -
Complex reasoning tasks: 81,920 tokens – Provides ample space for mathematical proofs and complex programming problems
Output Format Standardization
In different application scenarios, standardizing output formats through prompt engineering can significantly improve result quality:
Math problem prompts:
Please reason step by step, and put your final answer within \\boxed{}.
Multiple-choice question prompts:
Please show your choice in JSON format, e.g., {"answer": "C"}
Multi-Turn Conversation Processing
During multi-turn conversations, the history should only contain the model’s final outputs, not the thinking processes. This is automatically handled in the official Jinja2 chat template, but if using other frameworks, developers need to manually ensure compliance with this specification.
Frequently Asked Questions
Q: What are the main differences between Qwen3-Next-80B-A3B-Thinking and other versions?
A: This version is specifically optimized for complex reasoning tasks, featuring a thinking mode that performs internal reasoning before generating final answers. Compared to previous-generation models, it shows significant improvements in parameter efficiency, inference speed, and long-text processing capabilities.
Q: How much GPU memory is required to run the model?
A: Due to the MoE architecture, while the total parameter count is 80 billion, only 3 billion parameters are activated during each inference. With 4-card parallelization and appropriate quantization techniques, it can run with reasonable memory configurations. Specific requirements depend on context length and batch size.
Q: How to handle thinking content in model outputs?
A: The model’s thinking content is automatically included in the output, ending with the </think> tag. You can follow the code example provided above to separate thinking content from final responses. If thinking processes are not needed, consider using non-Thinking versions of the model.
Q: Does the model support multiple languages?
A: Yes, as seen from multilingual test results like MultiIF and MMLU-ProX in the performance table, the model has good multilingual processing capabilities, with particularly excellent performance in Chinese and English.
Q: How to further improve inference speed?
A: Besides using optimized frameworks like SGLang or vLLM, you can consider enabling multi-token prediction functionality, installing acceleration libraries like flash-linear-attention and causal-conv1d, and adjusting parallelization strategies and quantization precision according to actual needs.
Q: In which application scenarios does the model perform best?
A: This model is particularly suitable for tasks requiring complex reasoning, including: mathematical problem solving, code generation and debugging, scientific computing, long document analysis, logical reasoning games, research assistance, and similar scenarios.
Technical Contributions and Citation
If you use Qwen3-Next in research or projects, please cite the following technical reports:
@misc{qwen3technicalreport,
title={Qwen3 Technical Report},
author={Qwen Team},
year={2025},
eprint={2505.09388},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2505.09388},
}
@article{qwen2.5-1m,
title={Qwen2.5-1M Technical Report},
author={An Yang and Bowen Yu and Chengyuan Li and Dayiheng Liu and Fei Huang and Haoyan Huang and Jianhong Tu and Jianwei Zhang and Jingren Zhou and Junyang Lin and Kai Dang and Kexin Yang and Le Yu and Mei Li and Minmin Sun and Qin Zhu and Rui Men and Tao He and Weijia Xu and Wenbiao Yin and Wenyuan Yu and Xiafei Qiu and Xingzhang Ren and Xinlong Yang and Yong Li and Zhiying Xu and Zipeng Zhang},
journal={arXiv preprint arXiv:2501.15383},
year={2025}
}
Conclusion
Qwen3-Next-80B-A3B-Thinking represents the cutting edge of current large language model technology, achieving important breakthroughs particularly in reasoning capability and efficiency balance. Through this article’s technical analysis and practical guidance, we hope to help developers better understand and apply this powerful tool.
Whether you’re building next-generation AI applications or conducting cutting-edge AI research, this model deserves your in-depth exploration. Remember that appropriate tool configuration and usage methods are often more important than the model’s inherent capabilities—taking time to understand these best practices will make your projects twice as effective with half the effort.
The value of technology lies in its application—we look forward to seeing the innovative achievements everyone creates based on Qwen3-Next!

