Introduction
Core question this article addresses: How can we build a single model capable of simultaneously handling speech understanding, generation, and editing tasks? Ming-UniAudio achieves this breakthrough through its innovative unified continuous speech tokenizer and end-to-end speech language model, pioneering timestamp-free free-form speech editing that transforms the speech processing landscape.
In artificial intelligence, speech processing has long faced fragmentation between understanding, generation, and editing tasks. Traditional approaches either separated speech representations for different tasks or used discrete representations that lost speech details. Ming-UniAudio emerges as the first framework unifying speech understanding, generation, and editing through its core unified continuous speech tokenizer, effectively integrating semantic and acoustic features within an end-to-end model and opening new possibilities in speech processing.

Core Innovations and Key Technologies
Unified Continuous Speech Tokenizer
Core question this section addresses: How does Ming-UniAudio’s tokenizer simultaneously support both speech understanding and generation tasks?
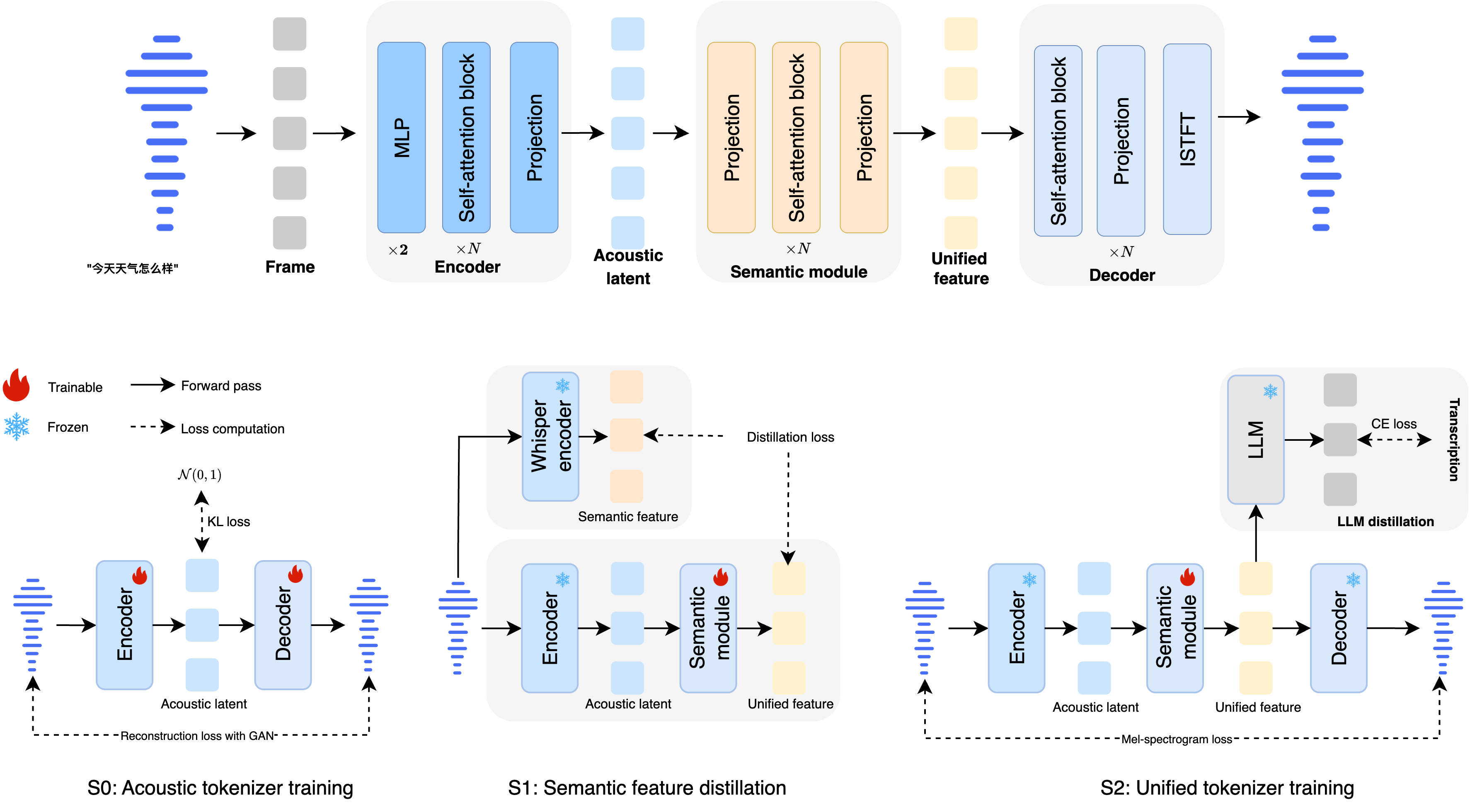
The breakthrough of Ming-UniAudio lies in its unified continuous speech tokenizer, MingTok-Audio, which builds on a VAE framework with causal Transformer architecture to effectively integrate semantic and acoustic features for the first time. Unlike traditional discrete representations, this continuous approach avoids quantization loss of speech details while enabling closed-loop systems with large language models through hierarchical feature representations.
Technical Implementation Details:
-
Causal Transformer architecture based on VAE framework -
50 frames/second processing speed balancing efficiency and quality -
Support for both Chinese and English processing -
Seamless integration with LLMs through hierarchical feature representations
In practical applications, this tokenizer enables the model to handle both speech transcription and generation tasks simultaneously. For instance, in speech understanding scenarios, it accurately captures semantic content from speech, while in generation scenarios, it retains sufficient acoustic details to produce high-quality speech output.
Author’s Reflection: Traditional speech models often required trade-offs between understanding and generation tasks. Ming-UniAudio’s unified tokenizer made me realize that through carefully designed continuous representations, we can actually achieve both. This design approach may become the standard architecture for future multimodal models.
Unified Speech Language Model
Core question this section addresses: How can a single model competently handle both speech understanding and generation tasks?
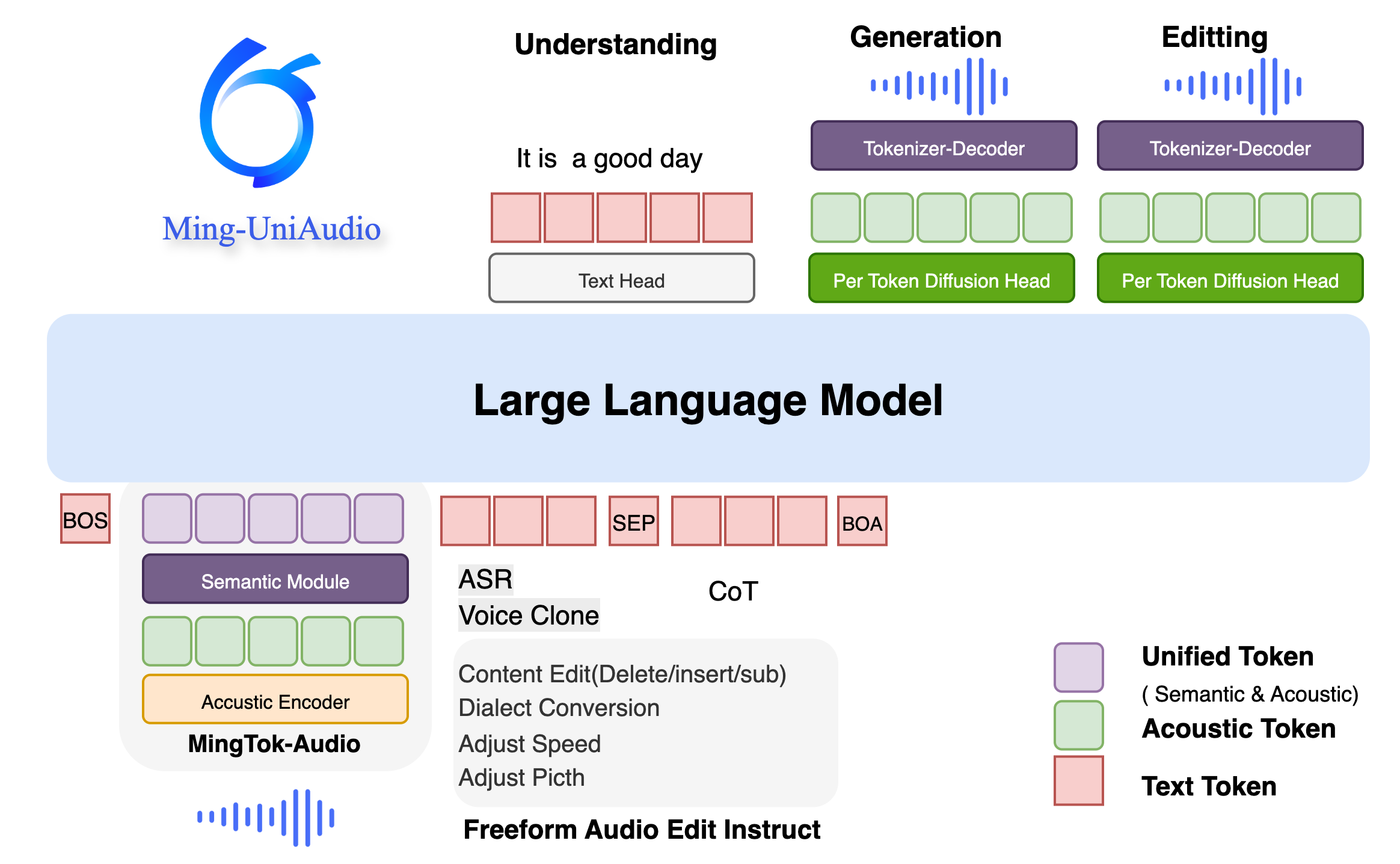
Ming-UniAudio employs a unified speech language model architecture using a single LLM backbone to simultaneously process understanding and generation tasks. The model ensures high-quality speech synthesis through a Diffusion Head while maintaining excellent comprehension capabilities.
Model Characteristics:
-
Single LLM backbone handling multiple tasks -
Diffusion Head enhancing speech synthesis quality -
16-billion parameter scale optimizing performance balance -
Support for multi-turn conversations and contextual understanding
In practical testing, the model demonstrates excellent performance in speech understanding tasks like automatic speech recognition (ASR), while achieving industry-leading levels in speech generation tasks like text-to-speech (TTS). This unified architecture reduces model complexity and deployment costs, providing convenience for practical applications.
Instruction-Guided Free-Form Speech Editing
Core question this section addresses: How can we achieve intelligent speech editing without manually specifying edit regions?
Ming-UniAudio’s most revolutionary capability is its instruction-guided free-form speech editing. Users can complete complex semantic and acoustic modifications through natural language instructions alone, without needing to manually specify edit regions or timestamps.
Editing Capabilities Coverage:
Semantic Editing
-
Insertion Operations: Insert words or phrases at specified positions -
Replacement Operations: Replace specific words or passages -
Deletion Operations: Remove unwanted speech segments
Practical Example: When given the instruction “insert ‘简直’ after the character or word at index 8,” the model accurately inserts “简直” after the 8th character in the sentence “真是个浪漫的邂逅可以说是英雄救美了,” transforming it into “真是个浪漫的邂逅简直可以说是英雄救美了” while maintaining natural speech fluency.
Acoustic Editing
-
Dialect Conversion: Convert Mandarin to Northeastern, Chengdu, and other dialects -
Speed Adjustment: Adjust speaking rate (0.5x to 2x) -
Pitch Modification: Raise or lower pitch (-5 to +5 semitones) -
Volume Control: Adjust audio loudness (0.3x to 1.6x) -
Noise Reduction: Remove background noise -
Background Music: Add rain sounds, vehicle sounds, or various music styles -
Emotion Conversion: Change speech emotional tone, such as converting to happy mood
Application Scenario Example: In video post-production, an editor discovers an incorrect statement in a narration segment. Traditional methods would require re-recording the entire passage, but now with the instruction “substitute ‘妈妈’ with ‘爸爸’,” the model precisely modifies the specified word while maintaining consistent voice tone, pitch, and background sounds.
Author’s Reflection: The instruction-guided speech editing capability reminds me of the evolution of image editing software—from manual operations requiring precise selections to intelligent content-aware tools. Ming-UniAudio brings this concept to the speech domain, dramatically lowering the technical barrier for speech editing and potentially revolutionizing audio content creation workflows.
Performance Evaluation and Benchmarking
Speech Tokenizer Performance
Core question this section addresses: How does Ming-UniAudio’s tokenizer perform in reconstruction quality?
In speech tokenizer reconstruction performance testing, MingTok-Audio significantly outperforms comparable products across multiple key metrics:
| System | Frame Rate | Chinese PESQ↑ | Chinese SIM↑ | Chinese STOI↑ | English PESQ↑ | English SIM↑ | English STOI↑ |
|---|---|---|---|---|---|---|---|
| MiMo-Audio-Tokenizer | 25 | 2.71 | 0.89 | 0.93 | 2.43 | 0.85 | 0.92 |
| GLM4-Voice-Tokenizer | 12.5 | 1.06 | 0.33 | 0.61 | 1.05 | 0.12 | 0.60 |
| Baichuan-Audio-Tokenizer | 12.5 | 1.84 | 0.78 | 0.86 | 1.62 | 0.69 | 0.85 |
| MingTok-Audio(ours) | 50 | 4.21 | 0.96 | 0.98 | 4.04 | 0.96 | 0.98 |
The data clearly shows that MingTok-Audio achieves optimal performance across key metrics including PESQ (Perceptual Evaluation of Speech Quality), SIM (Similarity), and STOI (Short-Time Objective Intelligibility), demonstrating its exceptional speech reconstruction capabilities.
Speech Understanding Performance
Core question this section addresses: How accurate is Ming-UniAudio in speech understanding tasks?
In automatic speech recognition (ASR) tasks, Ming-UniAudio demonstrates powerful performance across multiple datasets:
| Model | aishell2-ios | LS-clean | Hunan | Minnan | Guangyue | Chuanyu | Shanghai |
|---|---|---|---|---|---|---|---|
| Kimi-Audio | 2.56 | 1.28 | 31.93 | 80.28 | 41.49 | 6.69 | 60.64 |
| Qwen2.5 Omni | 2.75 | 1.80 | 29.31 | 53.43 | 10.39 | 7.61 | 32.05 |
| Ming-UniAudio-16B-A3B | 2.84 | 1.62 | 9.80 | 16.50 | 5.51 | 5.46 | 14.65 |
Particularly in dialect recognition tasks (Hunanese, Minnan, Cantonese, Sichuanese, Shanghainese), Ming-UniAudio significantly outperforms other models, demonstrating its powerful multi-dialect adaptation capabilities.
In contextual ASR tasks, Ming-UniAudio shows particularly outstanding performance in named entity recognition accuracy (NE-WER and NE-FNR), indicating it can not only transcribe speech but also better understand and retain important information in text.
Speech Generation Performance
Core question this section addresses: How does Ming-UniAudio perform in speech generation tasks?
In speech generation task evaluation, Ming-UniAudio demonstrates competitive performance:
| Model | Chinese WER(%) | Chinese SIM | English WER(%) | English SIM |
|---|---|---|---|---|
| Seed-TTS | 1.12 | 0.80 | 2.25 | 0.76 |
| MiMo-Audio | 1.96 | – | 5.37 | – |
| Qwen3-Omni-30B-A3B-Instruct | 1.07 | – | 1.39 | – |
| Ming-UniAudio-16B-A3B | 0.95 | 0.70 | 1.85 | 0.58 |
While slightly lower than specialized TTS models in speech similarity (SIM) metrics, it achieves the best performance in word error rate (WER), indicating its generated speech has excellent clarity and intelligibility.
Speech Editing Performance
Core question this section addresses: How accurate and natural is Ming-UniAudio in speech editing tasks?
Ming-UniAudio performs excellently across various speech editing tasks:
-
Basic Deletion Operations: Chinese WER 11.89%, Accuracy 100%, Similarity 0.78 -
Basic Insertion Operations: Chinese WER 3.42%, Accuracy 80%, Similarity 0.83 -
Basic Replacement Operations: Chinese WER 4.52%, Accuracy 78.62%, Similarity 0.82 -
Dialect Conversion: WER 8.93%, Similarity 0.66 -
Speed Adjustment: Chinese WER 5.88%, Similarity 0.66, Duration Error Rate 6.36% -
Volume Adjustment: Chinese WER 1.71%, Similarity 0.86, Amplitude Error Rate 14.9%
In noise reduction tasks, Ming-UniAudio also demonstrates competitive performance compared to specialized denoising models:
| Model | Type | DNSMOS OVRL | DNSMOS SIG | DNSMOS BAK |
|---|---|---|---|---|
| FullSubNet | Specialized | 2.93 | 3.05 | 3.51 |
| GenSE | Specialized | 3.43 | 3.65 | 4.18 |
| MiMo-Audio | General | 3.30 | 3.56 | 4.10 |
| Ming-UniAudio-16B-A3B-Edit | General | 3.26 | 3.59 | 3.97 |
Author’s Reflection: What impressed me most in the evaluation results was Ming-UniAudio’s outstanding performance in dialect recognition and editing. This demonstrates its acoustic model’s powerful ability to capture diverse speech characteristics, which has tremendous practical value for markets like China with numerous dialects.
Model Access and Environment Setup
Model Downloads
Core question this section addresses: How can we obtain and deploy Ming-UniAudio models?
Ming-UniAudio provides multiple model download channels:
| Type | Model Name | Input Modality | Output Modality | Download Links |
|---|---|---|---|---|
| Tokenizer | MingTok-Audio | Audio | Audio | HuggingFace / ModelScope |
| Speech LLM | Ming-UniAudio-16B-A3B | Audio | Audio | HuggingFace / ModelScope |
| Speech Editing | Ming-UniAudio-16B-A3B-Edit | Text, Audio | Text, Audio | HuggingFace / ModelScope |
| Benchmark | Ming-Freeform-Audio-Edit | – | – | HuggingFace / ModelScope |
For users in Mainland China, we recommend using ModelScope for downloads:
pip install modelscope
modelscope download --model inclusionAI/Ming-UniAudio-16B-A3B --local_dir inclusionAI/Ming-UniAudio-16B-A3B --revision master
Download time may range from several minutes to several hours depending on network conditions.
Environment Configuration
Core question this section addresses: How can we quickly set up the Ming-UniAudio runtime environment?
Method 1: pip Installation
git clone https://github.com/inclusionAI/Ming-UniAudio
cd Ming-UniAudio
pip install -r requirements.txt
Method 2: Docker Installation (Recommended)
# Pull pre-built image from Docker Hub (Recommended)
docker pull yongjielv/ming_uniaudio:v1.1
docker run -it --gpus all yongjielv/ming_uniaudio:v1.1 /bin/bash
# Or build from source
docker build -t ming-uniaudio:v1.1 -f ./docker/ming_uniaudio.dockerfile .
docker run -it --gpus all ming-uniaudio:v1.1 /bin/bash
Hardware Requirements:
-
GPU: NVIDIA H800-80GB or H20-96G -
CUDA: 12.4 -
Memory: 32GB or higher recommended
Author’s Reflection: Providing Docker images significantly simplifies the deployment process. In complex AI model deployments, environment configuration is often the most time-consuming step. The Ming-UniAudio team’s approach of using pre-built Docker images addresses this issue effectively, and this focus on user experience is worth emulating by other projects.
Practical Applications and Code Examples
Basic Usage Pipeline
Core question this section addresses: How can we quickly start using Ming-UniAudio for speech processing?
Here’s a complete application example demonstrating Ming-UniAudio’s core functionalities:
import warnings
import torch
from transformers import AutoProcessor
from modeling_bailingmm import BailingMMNativeForConditionalGeneration
import random
import numpy as np
from loguru import logger
def seed_everything(seed=1895):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
seed_everything()
warnings.filterwarnings("ignore")
class MingAudio:
def __init__(self, model_path, device="cuda:0"):
self.device = device
self.model = BailingMMNativeForConditionalGeneration.from_pretrained(
model_path,
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
).eval().to(torch.bfloat16).to(self.device)
self.processor = AutoProcessor.from_pretrained(".", trust_remote_code=True)
self.tokenizer = self.processor.tokenizer
self.sample_rate = self.processor.audio_processor.sample_rate
self.patch_size = self.processor.audio_processor.patch_size
def speech_understanding(self, messages):
"""Speech Understanding: Convert speech to text"""
text = self.processor.apply_chat_template(messages, add_generation_prompt=True)
image_inputs, video_inputs, audio_inputs = self.processor.process_vision_info(messages)
inputs = self.processor(
text=[text],
images=image_inputs,
videos=video_inputs,
audios=audio_inputs,
return_tensors="pt",
).to(self.device)
for k in inputs.keys():
if k == "pixel_values" or k == "pixel_values_videos" or k == "audio_feats":
inputs[k] = inputs[k].to(dtype=torch.bfloat16)
logger.info(f"input: {self.tokenizer.decode(inputs['input_ids'].cpu().numpy().tolist()[0])}")
generated_ids = self.model.generate(
**inputs,
max_new_tokens=512,
eos_token_id=self.processor.gen_terminator,
)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = self.processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)[0]
return output_text
def speech_generation(self, text, prompt_wav_path, prompt_text, lang='zh', output_wav_path='out.wav'):
"""Speech Generation: Text-to-speech conversion"""
waveform = self.model.generate_tts(
text=text,
prompt_wav_path=prompt_wav_path,
prompt_text=prompt_text,
patch_size=self.patch_size,
tokenizer=self.tokenizer,
lang=lang,
output_wav_path=output_wav_path,
sample_rate=self.sample_rate,
device=self.device
)
return waveform
def speech_edit(self, messages, output_wav_path='out.wav'):
"""Speech Editing: Modify speech based on instructions"""
text = self.processor.apply_chat_template(messages, add_generation_prompt=True)
image_inputs, video_inputs, audio_inputs = self.processor.process_vision_info(messages)
inputs = self.processor(
text=[text],
images=image_inputs,
videos=video_inputs,
audios=audio_inputs,
return_tensors="pt",
).to(self.device)
ans = torch.tensor([self.tokenizer.encode('<answer>')]).to(inputs['input_ids'].device)
inputs['input_ids'] = torch.cat([inputs['input_ids'], ans], dim=1)
attention_mask = inputs['attention_mask']
inputs['attention_mask'] = torch.cat((attention_mask, attention_mask[:, :1]), dim=-1)
for k in inputs.keys():
if k == "pixel_values" or k == "pixel_values_videos" or k == "audio_feats":
inputs[k] = inputs[k].to(dtype=torch.bfloat16)
logger.info(f"input: {self.tokenizer.decode(inputs['input_ids'].cpu().numpy().tolist()[0])}")
edited_speech, edited_text = self.model.generate_edit(
**inputs,
tokenizer=self.tokenizer,
output_wav_path=output_wav_path
)
return edited_speech, edited_text
if __name__ == "__main__":
# Initialize model
model = MingAudio("inclusionAI/Ming-UniAudio-16B-A3B")
# Example 1: Speech Recognition
messages = [
{
"role": "HUMAN",
"content": [
{
"type": "text",
"text": "Please recognize the language of this speech and transcribe it. Format: oral.",
},
{"type": "audio", "audio": "data/wavs/BAC009S0915W0292.wav"},
],
},
]
response = model.speech_understanding(messages=messages)
logger.info(f"Generated Response: {response}")
# Example 2: Speech Generation
model.speech_generation(
text='我们的愿景是构建未来服务业的数字化基础设施,为世界带来更多微小而美好的改变。',
prompt_wav_path='data/wavs/10002287-00000094.wav',
prompt_text='在此奉劝大家别乱打美白针。',
output_wav_path='data/output/tts.wav'
)
# Example 3: Speech Editing
del model
model = MingAudio("inclusionAI/Ming-UniAudio-16B-A3B-Edit")
messages = [
{
"role": "HUMAN",
"content": [
{"type": "audio", "audio": "data/wavs/00004768-00000024.wav", "target_sample_rate": 16000},
{
"type": "text",
"text": "<prompt>Please recognize the language of this speech and transcribe it. And insert '实现' before the character or word at index 3.\n</prompt>",
},
],
},
]
response = model.speech_edit(messages=messages, output_wav_path='data/output/ins.wav')
logger.info(f"Generated Response: {response}")
Real-World Application Scenarios
Scenario 1: Video Content Post-Production
During video editing, narration often requires modifications. Traditional methods needed complete re-recording of passages, but with Ming-UniAudio, editors simply provide instructions like “replace ‘优点’ with ‘优势’ in the third sentence,” and the system automatically makes the change while maintaining consistent voice tone and pitch, dramatically improving workflow efficiency.
Scenario 2: Multilingual Content Creation
Content creators can generate Chinese speech first, then quickly produce English versions through instructions like “translate to English and adjust speed to 1.2x,” while adapting speaking rates to different regional audience preferences.
Scenario 3: Audio Restoration and Enhancement
Historical recordings often suffer from noise and inconsistent volume levels. With the instruction “denoise the audio and normalize volume,” Ming-UniAudio can intelligently restore audio quality, bringing clarity back to historical recordings.
Author’s Reflection: While testing these application scenarios, I noticed that instruction precision significantly impacts editing results. Clear instructions like “insert ‘特别’ after the fifth word” yield more accurate results than vague instructions like “insert here.” This suggests that when designing speech interaction systems, we need to carefully consider how to guide users toward providing clear instructions.
Supervised Fine-Tuning and Model Optimization
Ming-UniAudio has open-sourced its supervised fine-tuning (SFT) module for speech generation, supporting both full-parameter and LoRA training approaches. This enables researchers and developers to further optimize model performance for specific domain requirements.
Key Training Configurations:
-
Support for Chinese and English speech generation -
Adjustable text normalization parameters -
Flexible prompt template design -
Grouped GEMM optimization for improved inference speed
Through fine-tuning, users can enhance speech generation quality in specific domains (such as medical narration, legal reading, etc.) while maintaining the model’s general capabilities.
Conclusion and Future Outlook
Ming-UniAudio represents a significant breakthrough in speech processing, addressing the fragmentation between understanding, generation, and editing tasks through a unified architecture. Its core contributions include:
-
Technical Innovation: First implementation of a unified continuous speech tokenizer effectively integrating semantic and acoustic features -
Application Revolution: Pioneering instruction-guided free-form speech editing without manual region specification -
Exceptional Performance: Achieving industry-leading levels in multiple benchmark tests, particularly in dialect processing -
Strong Practicality: Providing complete toolchains and optimized deployment solutions to lower usage barriers
From a technology development perspective, Ming-UniAudio’s success demonstrates the tremendous potential of unified architectures in multimodal tasks. Looking forward, we can anticipate more models based on similar concepts emerging, further breaking down barriers between different speech tasks.
Final Reflection: My deepest realization while using Ming-UniAudio was the power of technological democratization. Tasks that once required professional audio engineers for complex editing can now be accomplished by any user through natural language instructions. This technological accessibility not only improves efficiency but, more importantly, unlocks creative possibilities. Just as revolutionary image editing tools spawned a golden age of digital content creation, Ming-UniAudio may well be opening a new era in speech content creation.
Practical Summary and Operation Checklist
Quick Start Checklist
-
Environment Preparation
-
Install CUDA 12.4 or higher -
Prepare NVIDIA GPU (H800/H20 recommended) -
Choose Docker or pip installation method
-
-
Model Acquisition
-
Download models from HuggingFace or ModelScope -
Mainland China users should prioritize ModelScope -
Estimated download time: Several minutes to hours
-
-
Basic Usage
-
Speech Recognition: Prepare audio files, call speech_understanding method -
Speech Generation: Provide text and prompt audio, call speech_generation method -
Speech Editing: Combine audio and editing instructions, call speech_edit method
-
-
Performance Optimization
-
Use grouped GEMM to accelerate inference -
Adjust generation parameters to balance quality and speed -
Select appropriate model variants based on task requirements
-
One-Page Overview
Core Capabilities:
-
Speech-to-Text: High-accuracy multi-dialect recognition -
Text-to-Speech: High-quality speech synthesis with voice cloning support -
Intelligent Speech Editing: Comprehensive semantic and acoustic modifications
Special Features:
-
Timestamp-free free-form editing -
Natural language instruction guidance -
Multi-round editing dialogue support -
Real-time processing capability
Applicable Scenarios:
-
Audio content creation and post-production -
Multilingual media production -
Speech material restoration and enhancement -
Interactive speech application development
Frequently Asked Questions (FAQ)
What unique advantages does Ming-UniAudio have compared to other speech models?
Ming-UniAudio is the first framework unifying speech understanding, generation, and editing, using a unified continuous tokenizer to avoid representation inconsistencies between traditional understanding and generation tasks, while pioneering timestamp-free free-form speech editing capabilities.
How do I install Ming-UniAudio?
We recommend using Docker installation via docker pull yongjielv/ming_uniaudio:v1.1 to get pre-built images, or building from source. pip installation is also available but requires manual dependency configuration.
What speech editing tasks does Ming-UniAudio support?
It supports comprehensive semantic editing (insertion, replacement, deletion) and acoustic editing (dialect conversion, speed adjustment, pitch changes, volume control, noise reduction, background music addition, emotion conversion, etc.), all accomplished through natural language instructions.
What are the hardware requirements for the model?
Requires NVIDIA GPU (H800-80GB or H20-96G recommended), CUDA 12.4, and sufficient memory support. Resource allocation can be adjusted during inference based on task complexity.
Does it support custom training?
Yes, the project has open-sourced the supervised fine-tuning module, supporting both full-parameter and LoRA training approaches, allowing users to further optimize model performance with domain-specific data.
How does performance differ between Chinese and English processing?
Performance is generally comparable across most tasks, but Chinese support is more comprehensive in dialect processing, with particularly outstanding performance in conversions between Mandarin and various regional dialects.
How can I achieve the best editing results?
Provide clear editing instructions, explicitly specify edit positions and content, use high-quality input audio, and avoid attempting overly complex multi-round edits in a single pass.
Does it support real-time speech processing?
The current version is primarily optimized for offline processing, but near-real-time processing can be achieved through appropriate engineering optimizations, with specific performance depending on hardware configuration and task complexity.
