Explore how Huawei’s MindVL achieves state-of-the-art performance while using 90% less training data than comparable models.
Introduction to Multimodal AI Challenges
Multimodal Large Language Models (MLLMs) like Qwen2.5-VL and GPT-4V have transformed how machines understand visual and textual information. However, two persistent challenges remain:
-
Hardware Limitations: Most MLLMs rely on NVIDIA GPUs, creating barriers for environments using alternative accelerators like Huawei’s Ascend NPUs. -
Data Efficiency: Training these models typically requires massive datasets (often exceeding 4 trillion tokens), raising costs and carbon footprint concerns.
MindVL emerges as a breakthrough solution, demonstrating that high performance can be achieved with:
-
10x less training data than Qwen2.5-VL -
Optimized training on Ascend NPUs -
Superior OCR capabilities while matching general multimodal understanding benchmarks
Core Innovation: Native-Resolution Processing
Traditional MLLMs resize images to fixed dimensions, losing critical details in the process. MindVL adopts a vision transformer architecture that:
-
Accepts Variable Resolutions: Maintains original image dimensions (resized only to multiples of 28) -
Uses 2D Rotational Position Encoding (RoPE): Preserves spatial relationships in images -
Dynamic Feature Grouping: Reduces computational load while retaining fine details
Real-World Impact: This architecture excels at interpreting dense visual content like technical diagrams, financial charts, and medical imaging where precision matters.
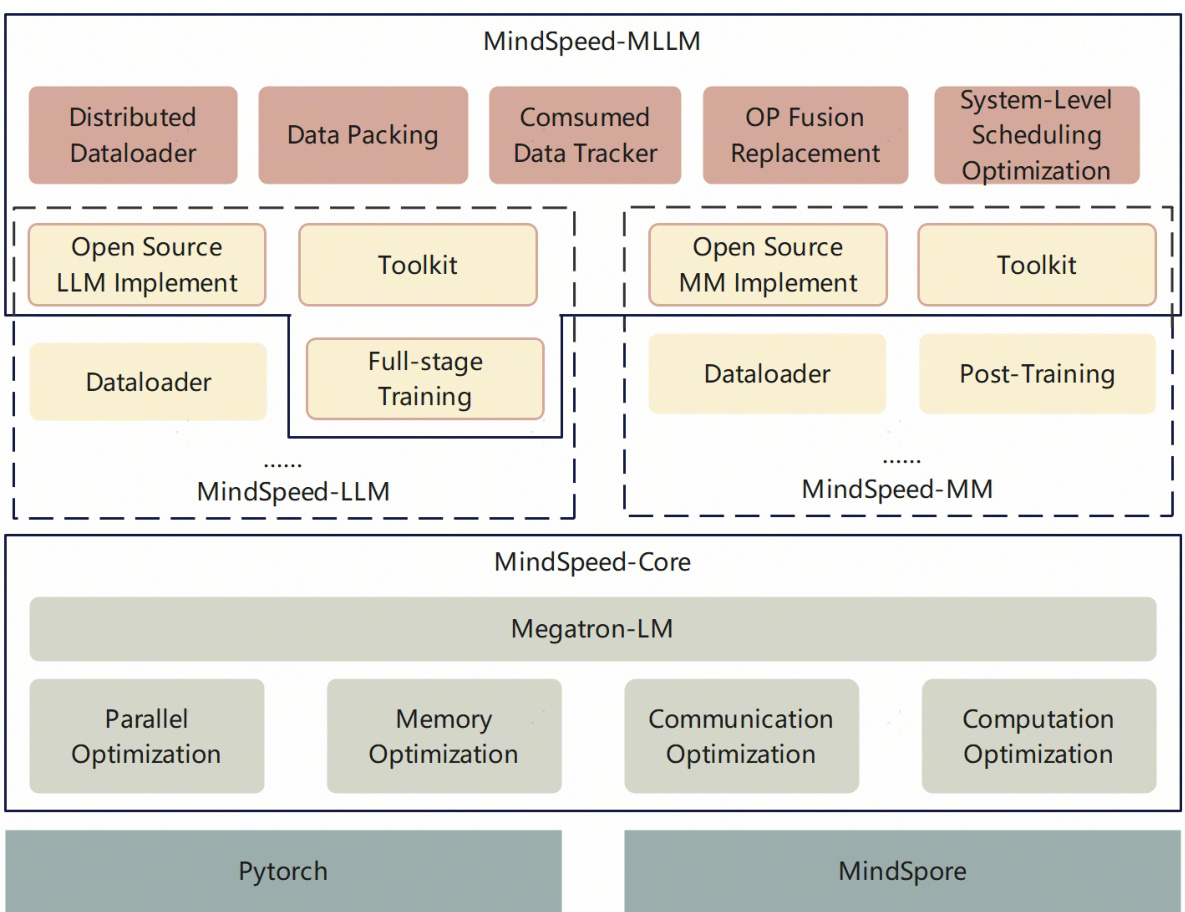
Hardware-Specific Optimization: MindSpeed-MLLM
Training large models on non-NVIDIA hardware requires overcoming ecosystem limitations. The team developed:
Key Framework Features:
-
Distributed Data Loading: Avoids bottlenecks when scaling across multiple NPUs -
Operator Fusion: Replaces computationally expensive operations with hardware-optimized equivalents -
Core Binding: Reduces latency by pinning tasks to specific CPU cores -
Pipeline Parallelism: Overlaps computation and communication tasks
Performance Note: Achieved 40% Model FLOPS Utilization (MFU) on 910B NPU clusters – comparable to NVIDIA A100 performance.
Three-Phase Training Strategy
MindVL’s training follows a progressive approach:
| ### Phase | Data Volume | Key Focus | Technical Details |
|---|---|---|---|
| Warm-Up | 256B tokens | Visual-Language Alignment | Trains only MLP adapter connecting vision encoder to LLM |
| Multitask | 179B tokens | Complex Reasoning | Full parameter tuning with interleaved image-text data |
| SFT | 12B tokens | Instruction Following | Mixed sequence lengths (2K/4K/8K tokens) |
Data Composition:
-
300B tokens: Image-text pairs (filtered via CLIP scoring + clustering) -
140B tokens: Multitask data (OCR, tables, STEM content, GUI interactions) -
Language Preservation: 20% of SFT data uses DeepSeek R1-generated text to maintain linguistic capabilities
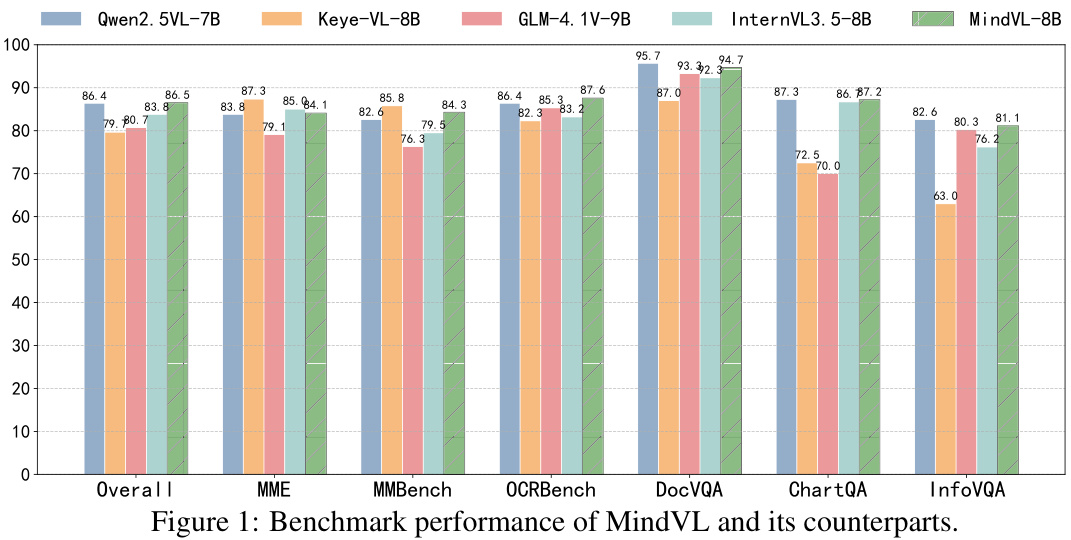
Performance Benchmarks
MindVL (8B parameters) was evaluated against leading models using 447B tokens total:
| Model | Training Data | MME | MMBench | OCRBench | Overall |
|---|---|---|---|---|---|
| Qwen2.5-VL7B | 4.1T+ | 83.8 | 82.6 | 86.4 | 86.4 |
| MindVL8B | 447B | 84.1 | 84.3 | 87.6 | 86.5 |
Key Advantages:
-
OCR Superiority: Outperforms Qwen2.5-VL by 1.2% in OCR tasks -
Data Efficiency: Achieves parity with 90% less training data
Model Optimization Techniques
1. Weight Averaging
-
Combines models trained with different sequence lengths (2K/4K/8K) -
Improves MMBench score by 1.9% compared to individual models
2. Test-Time Resolution Search
Developed a grid search strategy for optimal inference resolution:
| Dataset | Recommended Settings |
|---|---|
| OCRBench | min_pixels=162828 |
| Document QA | max_pixels=30722828 |
Limitations and Future Work
Current constraints include:
-
Model Size: Only 8B parameter version released -
Data Scale: Training limited to 447B tokens vs. trillion+ token models -
Evaluation Scope: Focused on mainstream benchmarks, not specialized tasks
Promising Development:
A 67B parameter version using DeepSeek-V3 as backbone achieved:
-
26B tokens (1/100 of Qwen2.5-VL’s data) -
Superior performance on certain tasks vs Qwen2.5-VL 72B
Technical Implementation Guide
Hardware Requirements
-
Minimum: Huawei Ascend 910B NPU -
Recommended: 8+ NPU cluster for training
Inference Code Snippet
# Resolution optimization example
def dynamic_resize(image):
min_pixels = 16*28*28 # OCR task setting
max_pixels = 3072*28*28 # Document QA setting
# Implementation logic...
FAQ
Q: How does MindVL handle different image sizes?
A: Uses 2D RoPE encoding to process variable resolutions while maintaining spatial relationships.
Q: What languages does it support?
A: Primarily optimized for Chinese but performs equally well in English benchmarks.
Q: Where can I access the model?
A: Currently available through Huawei Cloud’s ModelArts platform.
Q: Why does OCR performance excel?
A: Combination of native resolution processing + specialized document OCR data + resolution search optimization.
Conclusion
MindVL demonstrates that high-performance MLLMs can be trained efficiently on alternative hardware. By focusing on architecture optimization and data quality over quantity, it achieves state-of-the-art results while using significantly fewer resources. The success on Ascend NPUs opens possibilities for more diverse AI hardware ecosystems.
This article synthesizes technical details from “MindVL: Towards Efficient and Effective Training of Multimodal Large Language Models on Ascend NPUs” (2025), retaining all core specifications while optimizing for readability.
