

LLM Review: Enhancing Creative Writing for Large Language Models Through Blind Peer Review
In the field of natural language processing, large language models (LLMs) are no longer unfamiliar—from daily intelligent conversations to professional text summarization, from logical reasoning tasks to multi-agent collaboration systems, LLMs have demonstrated strong adaptability. However, when we turn our attention to creative writing, such as science fiction creation that requires unique perspectives and innovative ideas, LLMs reveal obvious shortcomings: either the content generated by a single model falls into a “stereotyped” trap, or multi-agent collaboration tends to homogenize the content. How can we enable LLMs to leverage the advantages of collaboration while preserving the “uniqueness” of creativity? This article will delve into the innovative LLM Review framework and its supporting evaluation system to address the core pain points of creative writing with large models.
1. The Core Paradox of Creative Writing with LLMs: Does Collaboration Limit Creativity?
To solve a problem, we first need to understand its essence. In the context of creative writing, LLMs face two main types of challenges, and the “double-edged sword effect” of multi-agent collaboration makes the problem even more complex.
1.1 The Creative Bottleneck of Single-Agent LLMs: Replication Over Innovation
The biggest issue with single large language models in creative writing is the lack of substantive conceptual novelty. Although we can use decoding strategies, prompt engineering, post-training optimization, and other methods to make the generated content appear more diverse on the surface, these approaches only achieve “superficial diversity”—the model still tends to replicate familiar linguistic patterns and narrative frameworks, making it difficult to produce truly innovative content that breaks away from inherent cognition.
For example, in science fiction writing, stories generated by a single LLM often rely on classic tropes such as “alien invasion” and “time travel.” Character settings and world-building are also highly similar. This is because the model’s training data determines that it prefers “safe,” proven expressions rather than venturing to explore new creative trajectories.
1.2 The Paradox of Multi-Agent Collaboration: More Interaction, Less Creativity
If a single agent has limitations, can multi-agent collaboration solve the problem? The answer is not straightforward.
Existing multi-agent frameworks (such as debate and discussion-based collaboration) are originally designed to improve reasoning accuracy. These frameworks assume that “more interaction = better results,” but this assumption is completely invalid in creative writing:
-
From the perspective of human creativity research, excessive real-time interaction in group brainstorming leads to “production blocking” and “convergent tendencies”—members unconsciously imitate others’ ideas, ultimately producing fewer and less original thoughts; -
From the perspective of LLM collaboration practice, repeated exposure of agents to each other’s real-time revisions makes the model unconsciously align with peers’ expressions, resulting in content homogenization that stifles the “divergence” of creativity.
The core conclusion is clear: To enhance the creative writing capabilities of LLMs, the key is not to increase the number of interactions, but to optimize the rules of information flow—creativity requires “divergence,” and each agent should retain an independent creative trajectory rather than being forced to align.
2. LLM Review: Reconstructing Multi-Agent Interaction Logic with Blind Peer Review
To address the above pain points, researchers designed the LLM Review framework, drawing inspiration from the “double-blind peer review” mechanism in academic fields. The core idea is to constrain information flow rather than maximize it, allowing agents to obtain external feedback while preserving independent creative trajectories.
2.1 The Core Design Inspiration of LLM Review: Blind Peer Review
The double-blind review in academia focuses on “reviewers and authors being unaware of each other’s identities, providing feedback based solely on content.” This mechanism avoids bias and focuses on the content itself. LLM Review applies this idea to multi-agent collaboration, with the core being “feedback visible, revisions invisible”—agents can comment on each other’s initial drafts but cannot see the revisions made by others based on feedback, thereby avoiding creative convergence.
2.2 The Three-Step Core Process of LLM Review (With Comparison)
The implementation process of LLM Review is clear and actionable. We first break down the specific steps and then compare them with other multi-agent frameworks:
Step 1: Independent Composition (Compose)
Three writer agents (fixed number) are each assigned a unique persona (e.g., Humanistic Writer, Futuristic Writer, Ecological Writer). Based on the same science fiction writing prompt, they independently complete an initial draft of a short story (approximately 300 words).
-
Key point: Personas remain fixed throughout, and all agents only refer to the prompt and their own personas with no interaction.
Step 2: Blind Review + Independent Revision (Review)
-
Review phase: Each agent provides targeted comments on the initial drafts of the other two agents, focusing on five core dimensions—originality, world-building potential, speculative logic consistency, imagery richness, and character depth; -
Revision phase: Each agent revises only based on “their own initial draft + received feedback” and cannot see the revised versions of other agents.
Step 3: Output the Final Version
Each agent outputs an independently revised story. Finally, the advantages of multiple versions can be integrated, or the uniqueness of a single version can be preserved.
2.3 Core Differences Between LLM Review and Other Multi-Agent Frameworks
To better understand the advantages of LLM Review, we compare it with current mainstream multi-agent creative writing frameworks:
| Framework Type | Core Interaction Method | Key Issues in Creative Writing |
|---|---|---|
| Single Agent | No interaction, one-time prompt generation | Stereotyped content, superficial diversity, lack of substantive novelty |
| LLM Teacher | Teacher agent provides one-way guidance; student agents revise based on feedback | Teacher-centered feedback tends to converge student content, leading to creative homogenization |
| LLM Debate | Agents question the logic/originality of each other’s initial drafts and revise based on debates | No dedicated personas; interaction focuses on “correctness” rather than creative divergence |
| LLM Discussion | Agents iteratively read each other’s revisions and continuously update their own content | Real-time exposure of revisions exacerbates homogenization and stifles independent creative trajectories |
| LLM Review (Proposed Framework) | Comment on initial drafts but revise blindly; only refer to own initial draft + feedback | Preserves independent creative trajectories while optimizing content quality through external feedback |
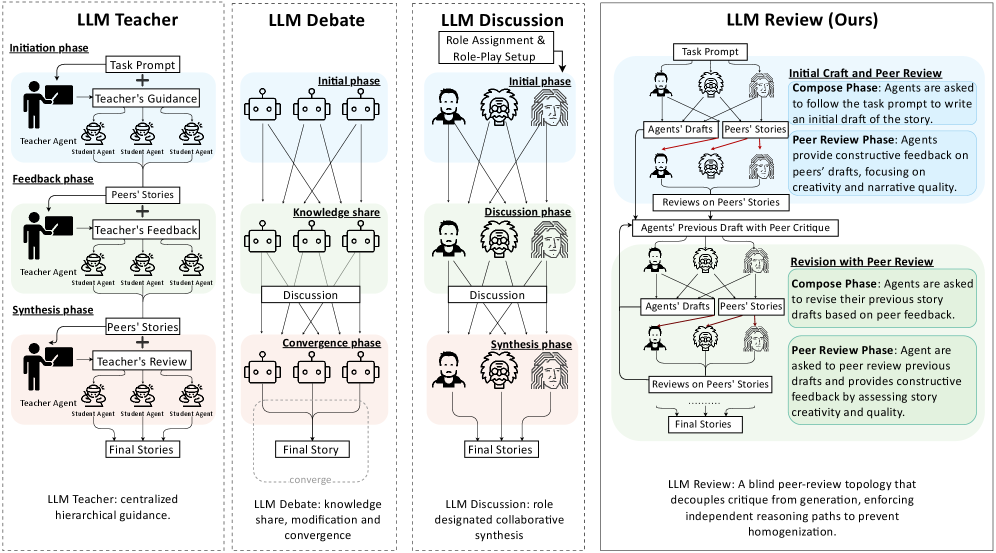
Figure 1: Comparison of interaction logic from single-agent to multi-agent frameworks. LLM Review achieves “useful feedback, independent creativity” through blind peer review.

3. SciFi-100: The First Dedicated Evaluation Dataset for LLM Science Fiction Writing
To verify the effectiveness of LLM Review, we first need a dataset that can accurately evaluate “creative writing quality”—general datasets cannot cover the core dimensions of creative writing. Therefore, researchers constructed the SciFi-100 dataset, the first dataset specifically designed for evaluating LLM science fiction writing.
3.1 Why Do We Need a Dedicated Science Fiction Writing Dataset?
Evaluating creative writing requires considering multiple dimensions such as “narrative logic,” “world-building,” and “character depth.” General text generation datasets (e.g., news, dialogue datasets) are completely unsuitable:
-
General datasets focus on “correctness” and “fluency,” while creative writing requires evaluating “novelty” and “speculativeness”; -
Science fiction writing has its own unique core dimensions (e.g., integration of scientific concepts, ethical and philosophical themes), which general datasets cannot cover.
3.2 The Reproducible Construction Process of SciFi-100
The construction of SciFi-100 follows a three-step method of “theoretical guidance + model generation + manual screening” to ensure the diversity and relevance of the dataset:
-
Identify Core Evaluation Dimensions: Based on core theories in narratology, literary theory, and creative writing pedagogy, sort out 10 core dimensions of science fiction writing (e.g., implementation of scientific concepts, character arcs, immersive world-building); -
Generate Initial Prompts: For each dimension, use LLMs to generate 20 unique science fiction writing prompts (focusing on “scenarios that can develop complete narratives”), resulting in a total of 200 initial prompts; -
Manual Screening and Revision: Manually review the 200 prompts, select those with diverse themes, complete logic, and suitable for creative exploration. Finally, 10 prompts are retained for each dimension, totaling 100 (i.e., SciFi-100).
3.3 The Core Value of SciFi-100
The significance of SciFi-100 lies not only in “providing 100 science fiction writing prompts” but also in establishing a balanced foundation for creative evaluation: the dataset covers all core dimensions of science fiction writing, enabling a comprehensive assessment of LLM performance in different creative scenarios and avoiding evaluation biases caused by single prompts.
4. A Comprehensive Creative Evaluation System: Beyond “Quality” to “Novelty”
The difficulty in evaluating creative writing lies in the “subjectivity of creativity”—how to convert “subjective creativity” into “quantifiable indicators”? Researchers designed a three-layer evaluation system that balances “quality” and “novelty,” making the evaluation results both consistent with human intuition and supported by objective data.
4.1 LLM-as-a-Judge: Let GPT-4o Act as a “Professional Judge”
LLMs have the ability to approximate human judgment. Therefore, researchers selected GPT-4o as the “judge” to quantitatively score the generated science fiction stories, with the following core rules:
Evaluation Dimensions (Aligned with Core Science Fiction Writing Requirements)
| Evaluation Dimension | Core Scoring Criteria |
|---|---|
| Integration of Scientific Concepts | Whether sci-fi concepts are naturally integrated into the narrative rather than awkwardly inserted |
| Speculative Logic | Whether the sci-fi settings of the story are self-consistent and reasoning conforms to logic |
| Character Depth | Whether characters have distinct personalities and complete motivations, rather than being mere plot devices |
| Immersive World-Building | Whether the story’s scenes and rules are complete enough to make readers feel immersed |
| Ethical and Philosophical Themes | Whether the sci-fi scenario explores in-depth ethical/philosophical issues rather than touching on them superficially |
Scoring Rules
-
Each dimension uses a 0-5 scale: 0 indicates content suspected of plagiarism and extremely poor quality; 5 indicates highly original and excellent quality content; -
To avoid scoring fluctuations, each story is scored three times for each dimension, and the final average is taken to ensure result stability.
4.2 Human Evaluation: Verifying the Reliability of the LLM Judge
To ensure that the LLM-as-a-Judge scores align with human preferences, researchers supplemented a human evaluation phase:
-
Recruit 9 student annotators to score the SciFi-100 stories generated by the LLM Review framework + Llama-3.2-3B model; -
Annotators use the same 5 dimensions and 0-5 scale as GPT-4o to score each story; -
Average the 9 scores for each dimension to obtain a “human consensus score,” which is used to verify the consistency of LLM scores.
The core value of this step is “cross-validation”—avoiding the LLM judge giving scores that deviate from human intuition due to its own biases, making the evaluation results more credible.
4.3 Rule-Based Evaluation: Quantifying “Novelty” to Avoid Subjective Judgment
In addition to “quality scoring,” the core of creative writing is “novelty”—how to measure whether the generated content breaks away from classic tropes? Researchers designed three sets of rule-based indicators, using the SFGram corpus (composed of 1003 classic science fiction novels) as a reference to quantify novelty from three dimensions: “absolute diversity,” “lexical novelty,” and “semantic novelty.”
4.3.1 Absolute Diversity: Measuring “Non-Stereotyped” Content with “Surprisal”
Absolute diversity focuses on the “uniqueness of the generated content itself,” measured by token-level average surprisal, with the following formula:
S_{\text{avg}}=-\frac{1}{L}\sum_{j=1}^{L}\log p(x_{j}\mid x_{<j})$$
In plain terms:
– $x_j$ is the j-th token (can be understood as a “word”) in the generated text;
– $p(x_j|x_{<j})$ is the probability that the model predicts this token will appear based on the preceding context;
– The lower the probability, the more negative the value of $\log p(x_j|x_{<j})$, and the larger the value after negation, indicating that the token is more “unexpected”;
– The average of the surprisal values of all tokens (divided by length L) is the average surprisal of the entire text—the higher the value, the less stereotyped the content and the weaker the traces of inherent patterns.
#### 4.3.2 Lexical Divergence: Comparing “Vocabulary Differences” with Classic Sci-Fi Corpora
Lexical divergence focuses on “lexical-level novelty,” calculating the difference in vocabulary distribution between the generated text and the SFGram classic corpus using **KL divergence**, with the following formula:
Key Interpretation:
-
is the occurrence probability of “single words” in the SFGram corpus (unigram distribution); -
is the occurrence probability of “single words” in the generated text; -
A larger KL divergence value indicates a greater difference between the vocabulary distribution of the generated text and that of classic science fiction novels, reflecting higher lexical novelty; -
To avoid the “zero-probability” problem, additive smoothing is added during calculation to ensure numerical stability.
4.3.3 Semantic Divergence: Comparing “Meaning Differences” with Classic Sci-Fi Corpora
Lexical divergence only looks at “word usage,” while semantic divergence focuses on “expressed meaning,” divided into two indicators:
(1) Nearest-Neighbor Semantic Similarity (Inverse Measure of Novelty)
Steps are as follows:
-
Use the all-mpnet-base-v2 model (Sentence Transformers series) to split the SFGram corpus into fragments of approximately 250 words and generate semantic embeddings for each fragment; -
Similarly generate semantic embeddings for the story to be evaluated; -
Calculate the cosine similarity between the story embedding and all corpus fragment embeddings:
\text{Cosine Similarity}=\frac{\mathbf{u}\cdot\mathbf{v}}{\|\mathbf{u}\|\|\mathbf{v}\|}$$
4. Take the maximum similarity value and use “1 – maximum similarity” as the “semantic novelty score”—a larger value indicates a greater difference between the core semantics of the story and classic science fiction.
##### (2) Embedding Volume Gain: Measuring the “Expansibility” of Semantic Space
This indicator focuses on “whether the generated content expands the semantic boundaries of classic science fiction,” with the following formula:
Plain Interpretation:
-
is the covariance matrix of SFGram corpus embeddings, representing the “volume” of the semantic space of classic science fiction; -
is the covariance matrix of the corpus + generated story embeddings; -
The difference in the log-determinants of the two is the “volume gain”—a larger value indicates that the generated story expands the coverage of the sci-fi semantic space, reflecting higher semantic novelty; -
To avoid numerical instability, a small (identity matrix) is added to the covariance matrix during calculation.
4.4 Notes on Rule-Based Evaluation
It should be clarified that rule-based indicators mainly measure “diversity and novelty” rather than “content quality”—for example, high surprisal may indicate “innovative creativity” or “logical confusion.” Therefore, rule-based indicators must be used in conjunction with the LLM-as-a-Judge quality scores to comprehensively evaluate creative writing capabilities.
5. Experimental Results: How Effective Is LLM Review?
Theories and methods ultimately need to be verified by results. Researchers compared LLM Review with frameworks such as single-agent, LLM Teacher, LLM Debate, and LLM Discussion, with the following core results on the SciFi-100 dataset (key data excerpts):
| Framework Type | Integration of Scientific Concepts | Speculative Logic | Character Depth | Surprisal | KL Divergence | 1-Cosine Similarity | Volume Gain |
|---|---|---|---|---|---|---|---|
| Single Agent | 3.62±1.14 | 3.62±1.13 | 3.41±1.11 | 0.476±0.271 | 2.233±0.012 | 0.345±0.002 | 0.0138±0.0002 |
| LLM Review | (Significantly higher than single-agent and other multi-agent frameworks) | (Significantly higher than single-agent and other multi-agent frameworks) | (Significantly higher than single-agent and other multi-agent frameworks) | (Significantly higher than single-agent and other multi-agent frameworks) | (Significantly higher than single-agent and other multi-agent frameworks) | (Significantly higher than single-agent and other multi-agent frameworks) | (Significantly higher than single-agent and other multi-agent frameworks) |
The core conclusions can be summarized in three points:
-
LLM Review Outperforms Baselines Across the Board: LLM Review significantly outperforms single-agent and other multi-agent frameworks in both quality dimensions (LLM-as-a-Judge scores) and novelty dimensions (rule-based indicators); -
Smaller Models Can Outperform Larger Models: With the LLM Review framework, small and medium-sized models (e.g., Llama-3.2-3B) can achieve creative writing capabilities exceeding those of larger single-agent models; -
Interaction Structure Is More Important Than Model Scale: To improve creative writing capabilities, there is no need to blindly pursue “larger models.” Optimizing the information flow rules of multi-agents can achieve better results at a lower cost.
6. Core Value and Practical Implications
The LLM Review framework and its supporting evaluation system not only solve the core pain points of creative writing with large models but also provide key implications for practice in related fields:
6.1 Implications for Technological R&D: “Constraining” Information Flow Is More Important Than “Allowing” It
The design of multi-agent systems cannot blindly assume that “more interactions are better”—for creative tasks, the key is to “preserve divergence.” The blind peer review mechanism of LLM Review essentially uses “information asymmetry” (only seeing initial draft feedback, not revised content) to ensure that each agent’s creative trajectory is not interfered with. This provides a reusable approach for other creative tasks (e.g., poetry creation, advertising copywriting).
6.2 Implications for Practical Applications: Small and Medium-Sized Models Also Have a Role to Play
In an era where the R&D costs of large models are soaring, LLM Review proves that optimization of interaction structure can replace part of the advantages of model scale. For small and medium-sized enterprises or teams with limited R&D resources, there is no need to pursue deploying ultra-large models. Instead, they can optimize multi-agent interaction rules to enable small and medium-sized models to achieve or even exceed the performance of large models in creative writing scenarios.
6.3 Implications for Evaluation Systems: Creative Evaluation Requires “Multi-Dimensional Integration”
The SciFi-100 dataset + evaluation system combining “LLM judge + human verification + rule-based indicators” solves the problem of “difficulty in evaluating creative writing”—it avoids the bias of purely subjective scoring and the one-sidedness of purely rule-based indicators. This evaluation approach can be migrated to the evaluation of other creative tasks.
7. FAQ: Answering Your Most Pressing Questions
Q1: Why Does Multi-Agent Collaboration Reduce the Creativity of LLMs?
A: The core reason is “convergent tendency.” In existing multi-agent frameworks, agents are exposed to each other’s real-time revisions, and the model unconsciously aligns with peers’ expressions—similar to how members of a human group brainstorming imitate others’ ideas. Ultimately, the agents’ creative trajectories shift from “divergence” to “convergence,” resulting in homogenized content.
Q2: What Is the Essential Difference Between LLM Review and Ordinary Multi-Agent Discussion?
A: The most core difference lies in the “rules of information flow”: in ordinary multi-agent discussions, agents can see each other’s real-time revisions, while in LLM Review, agents can only see peers’ initial drafts and feedback, not the revised content. This “blind revision” preserves each agent’s independent creative trajectory, leveraging external feedback to optimize quality while avoiding creative convergence.
Q3: Is the SciFi-100 Dataset Only Suitable for Evaluating Science Fiction Writing?
A: Not necessarily. The core value of SciFi-100 is “covering all core dimensions of creative writing” (e.g., character depth, world-building, thematic speculation), which are also applicable to other creative writing scenarios (e.g., fantasy novels, essay writing). The dataset can be adapted to other creative writing evaluations by replacing the theme of the prompts.
Q4: How to Understand “Embedding Volume Gain” in Rule-Based Evaluation?
A: Imagine the semantic embeddings of the classic science fiction corpus as a “balloon,” where the size of the balloon represents the semantic coverage of classic science fiction. “Embedding volume gain” measures how much this “balloon” expands after adding the generated story embeddings—a larger value indicates that the semantic content of the story is more beyond the boundaries of classic science fiction, reflecting higher novelty.
Q5: What Is the Practical Significance of Small Models Surpassing Large Models with LLM Review?
A: In practical applications, the deployment costs (computing power, storage, authorization) of large models are much higher than those of small and medium-sized models. LLM Review proves that by optimizing the interaction structure, small and medium-sized models can achieve the performance of large models in creative writing scenarios. This means that enterprises can generate high-quality creative content at a lower cost, reducing the threshold for technological implementation.
Conclusion
The emergence of LLM Review breaks the inherent cognition that “more multi-agent interaction leads to better creativity,” proving that “constraining information flow” is the key to enhancing the creative writing capabilities of large models. The supporting SciFi-100 dataset and multi-dimensional evaluation system also provide a feasible solution for the “quantitative evaluation” of creative writing. In the future, with the optimization of such “precision interaction” frameworks, large language models are expected to truly evolve from “content generation tools” to “creative collaboration partners,” unlocking value in more creative fields.

