Picture this: You’re knee-deep in a math puzzle, and your Harvard-level AI professor (the big LLM) is brilliant but stumbles at the crucial step. Then a sharp kid next door (a small model) chimes in with, “Hey, try it this way.” Boom—the professor gets it, and the answer clicks. Sounds like a fairy tale? Nope, it’s the magic of LightReasoner in action. This framework boosts your LLM’s math reasoning by up to 28% while slashing 90% of your compute costs. Intrigued? It’s not sci-fi—it’s open-source on GitHub, ready for you to tinker with.
TL;DR: What You’ll Walk Away With
After this read, you’ll know how to use a small model to “coach” a large one, ramping up math reasoning accuracy without drowning in training resources.
Hands-on: Clone the repo, fire off a sampling script, and watch your model evolve from guesswork wizard to precision solver.
Pain point fixed: Ditch pricey SFT! LightReasoner leverages label-free contrastive learning to help AI engineers and researchers iterate faster, banishing resource woes.
The LLM Reasoning Hangover: Why Even Giants Trip on Logic?
I still recall my first rodeo with an LLM on a math problem: It spun a verbose chain of thought, only to derail spectacularly on the final calculation. Fluent in chit-chat? Absolutely. But step-by-step logic? Not so much. LLMs excel at pattern mimicry, not innate “thinking.” The go-to fix is supervised fine-tuning (SFT), but it’s a resource hog—gobbling massive labeled datasets, rejection sampling thousands of runs, and optimizing every token equally, even the fluff ones. Cue the GPU meltdown and the budget blues.
Enter LightReasoner, the clever mediator flipping the script: What if small models taught large ones? It sounds nuts, but it nails the crux—small models’ “flaws” spotlight the large ones’ pivotal insights. By honing in on expert (large model) vs. amateur (small model) divergences, it targets those make-or-break reasoning bottlenecks. No hype; let’s unpack how this lands from paper to your command line.
Figure 1: LightReasoner vs. SFT—accuracy climbs, resources plummet 90%. Small-model teaching isn’t child’s play; it’s game-changing.
Paper Highlights: The “Contrastive Coaching” Core of LightReasoner
If you’re a researcher or deep-dive dev, this is your jam. The arXiv paper (2510.07962) isn’t formula soup—it’s a laser-focused takedown of SFT’s blunt edges. Why grind full trajectories when you can cherry-pick “aha” moments, human-mentor style? At its heart: Kullback-Leibler divergence (KL divergence), quantifying clashes between the expert model π_E and amateur π_A at each token. Bigger divergence? Bigger the reasoning pivot.
The framework splits into two phases: Sampling identifies steps where KL > β, crafting contrastive soft labels v_C (expert edge = expert dist – amateur dist); Fine-tuning aligns the expert via KL minimization, self-distilling its strengths. Tested on seven math benchmarks across five baselines, it nets 11.8% average gains—zero ground-truth labels needed. Case in point: Qwen2.5-Math-1.5B jumps from 42.5% to 70.6% on GSM8K. Not incremental; transformative.
| Model | GSM8K | MATH | SVAMP | ASDiv | AVG |
|---|---|---|---|---|---|
| Qwen2.5-Math-1.5B Baseline | 42.5 | 34.2 | 68.8 | 68.1 | 42.4 |
| + SFT | 69.2 | 57.1 | 64.1 | 70.2 | 50.1 |
| + LightR | 70.6 | 59.3 | 76.0 | 79.8 | 54.2 |
Table 1: Key results snapshot. LightR edges out SFT under equal resources—data that hits home.
The Intuition: Why Small Models Make Killer “Tough Love” Teachers
Before we code, let’s vibe on the intuition—dry tutorials are for textbooks, not blogs. Think teaching a kid to bike: You skip the physics lecture and point to the “lean here, brake there” spots. LightReasoner does the same: The small model (amateur) unmasks the large model’s (expert) secret sauce. Those KL spikes? Moments where the expert nails the right token with 0.8 confidence, while the amateur waffles or veers off—pure human learning distilled.
Even better, it busts the “bigger is always better” myth. Paper stats show domain expertise trumps raw scale: Qwen2.5-Math-1.5B paired with Qwen2.5-0.5B (38.2% gap) hits 68.1% average; swap to a same-size generalist, and gains fizzle. Reminds me of Go AIs: AlphaGo didn’t brute-force params—it pored over master games. LightReasoner’s 99% token trim? Leverage at its finest: Nail bottlenecks, amplify everything.
Expert vs. Amateur Showdown: KL Divergence’s Real-World Wizardry
Let’s geek out on KL, the “scalpel” here. The math’s straightforward: D_KL(π_E || π_A) = Σ π_E(a|s_t) log(π_E(a|s_t)/π_A(a|s_t))—gauging how the expert veers from amateur pitfalls. On GSM8K, peak KL steps are often calc pivots, like “1/6 of 24=4,” where expert locks in at 0.8 prob, amateur scatters to 0.2 fog.
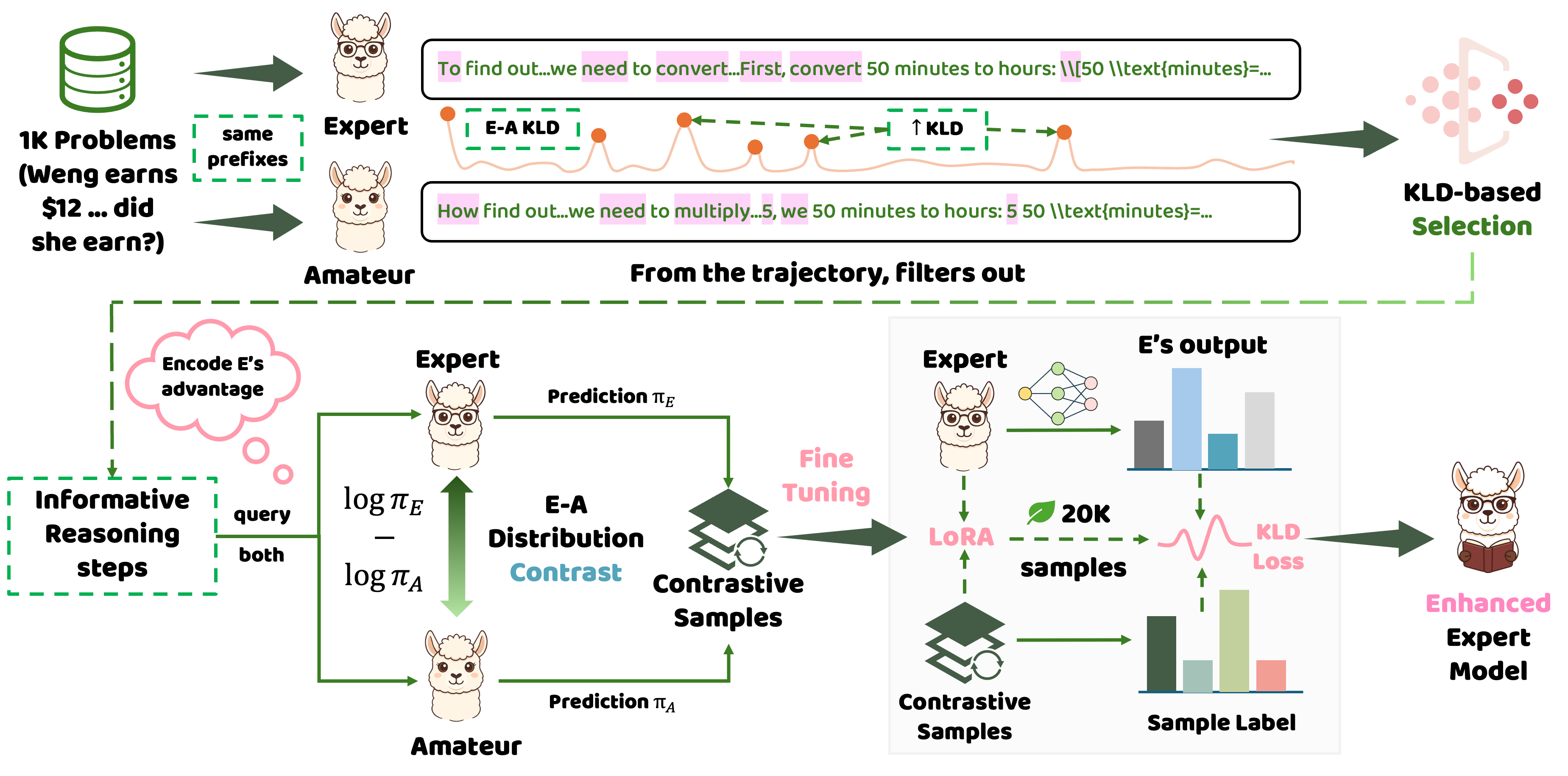
Figure 2: The two-phase flow. Sampling snags divergences; tuning aligns strengths—once visualized, it all snaps into focus.
Domain savvy rules: Math-tuned small models outshine generalist giants by delivering “bespoke feedback,” not vague scale. Real case? GSM8K prompt: “Two girls each got 1/6 of 24 liters of water. Then a boy got 6 liters. How many left?” Baseline flubs to 1 liter remaining; LightR-tuned version breaks it down, lands on 10. The clash? Fraction step, KL=2.1—nailed.
Hands-On: Zero-Friction Setup in 5 Minutes Flat
Showtime! Say you’re a slammed AI engineer squeezing in a weekend hack. LightReasoner feels like an old pal: git clone https://github.com/HKUDS/LightReasoner.git, smooth sailing. cd in, pip install -r requirements.txt—Python 3.10+, plug-and-play.
Model grabs are pivotal: Expert via huggingface-cli download Qwen/Qwen2.5-Math-1.5B --local-dir ./Qwen2.5-Math-1.5B (1.5B keeps it nimble); amateur sticks to Qwen2.5-0.5B with huggingface-cli download Qwen/Qwen2.5-0.5B --local-dir ./Qwen2.5-0.5B. Why this duo? Paper’s “sweet spot” rule: Expert dominates amateur, but amateur stays coherent—0.5B nails the expertise gap.
Data prep? A breeze: python data_prep.py. Defaults to GSM8K (step-wise logic, no domain jargon), spitting out JSONL train sets. Swap datasets? Go wild! Just tweak the amateur for solid contrasts.
Sampling Phase: Snagging Those “Magic Moments”
Sampling’s the soul of LightR: No full-trajectory spam—just high-value steps. Tweak LightR_sampling.py config: expert_path="./Qwen2.5-Math-1.5B", amateur_path="./Qwen2.5-0.5B", beta=1.0 (threshold; crank for noise). Then: python LightR_sampling.py --max_questions 1000—batch_size GPU-dependent, 32 on H100.
Quick validation example: --max_questions 1, feed sample {“question”: “Two girls each got 1/6 of the 24 liters of water. Then a boy got 6 liters of water. How many liters of water were left?”}. Output JSONL: {“step”: 3, “kl”: 2.1, “expert_dist”: [0.8 for ‘4’], “amateur_dist”: [0.2 for ‘wrong’] }. Expect: 1-2 high-KL steps (>0.5), soft label v_C boosting expert calc; post-tune, accuracy leaps from 42.5% to 70.6% on that prompt. Done—supervision dataset primed, 1000 questions in minutes.

Figure 3: Trajectory KL spikes like beacons—under 10% of steps, but 80% of the value. Sampling’s pure gold-hunting.
Fine-Tuning & Merging: From Rough to Razor-Sharp, One Command Away
Tuning’s like brewing coffee: Prep right, savor the aroma. python LightR_finetuning.py (nohup for no-hassle: nohup python LightR_finetuning.py > finetune.log 2>&1 &; tail -f finetune.log to watch). Config swap: path_to_expert_model="./Qwen2.5-Math-1.5B", path_to_training_dataset="your_sample.jsonl", output_directory="./ft_model"; torch_dtype=torch.bfloat16 (H100 hero; A100 gets float16).
Built-in LoRA + KL aligns to v_C—99% fewer tokens, honing key preds only. Post-run: python merge.py with base_model_path="./Qwen2.5-Math-1.5B", lora_ckpt_path="./ft_model/checkpoint-1000", merged_model_path="./ft-1.5B-merged". Eval? Qwen2.5-Math toolkit in /evaluation—benchmark the seven in one go. Outcome? 0.5 hours, GSM8K +28.1%.
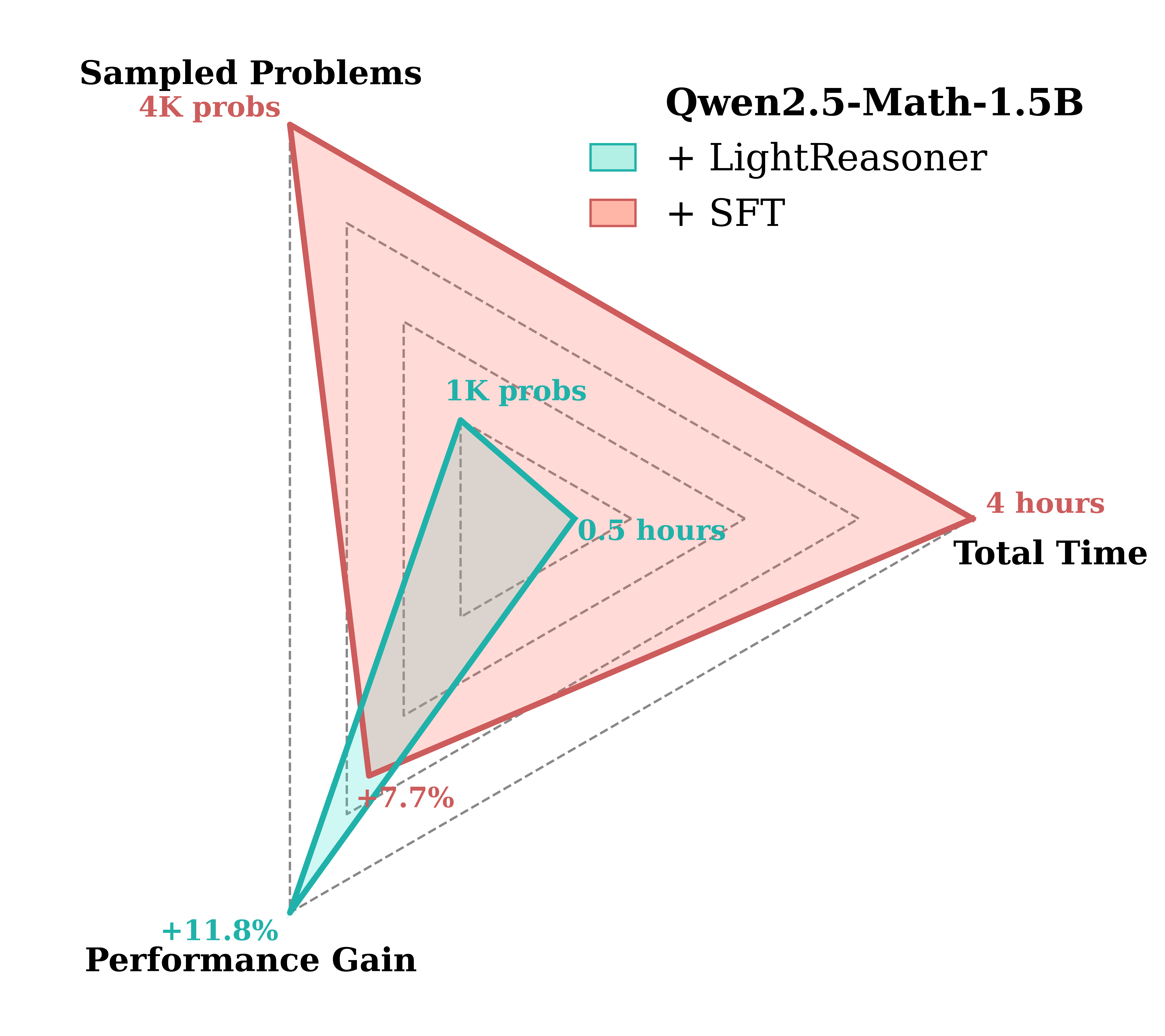
Figure 4: LightR’s radar glows green; SFT’s a sluggish beast—time/problems/tokens, dominated 90%.
Advanced: Benchmark Breakdowns and Pitfall Dodges
Numbers don’t lie: LightR generalizes across five models, like DeepSeek-R1-Distill-Qwen-1.5B’s +17.4% on OlympiadBench. Vs. SFT? 4.7% average edge, 90% resource shave—paper’s efficiency table seals it.
Watch the traps, though: Pairing’s an art. Gap too narrow (<15%)? Signals fade. Amateur too dim? Outputs gibberish. Sweet spot: Math-1.5B + 0.5B. Hyperparams: Start β=1.0; Llama datasets? Dial batch_size vs. OOM. Scale out? Code gen’s ripe—KL snags syntax chokepoints.
Figure 5: Gap curve peaks at “balance”—scale’s no silver bullet.
graph TD
A[Input Prompt] --> B[Expert & Amateur Parallel Generation]
B --> C{KL > β?}
C -->|Yes| D[Build v_C Contrast Label]
C -->|No| E[Discard]
D --> F[Supervision Dataset]
F --> G[LoRA + KL Fine-Tune]
G --> H[Enhanced Expert Model]
E --> H
Figure 6: Mermaid Flow. Clean loop, label-free efficiency—paste into Notion and iterate.
Wrapping Up: Small Is the New Big in AI Tutoring?
LightReasoner isn’t just code—it’s a paradigm shift, dethroning “bigger equals better” in AI lore: Weak models as teaching signals, democratizing resources. Horizon? Open-source will spawn wild pairing experiments, fueling sustainable reasoning. Best bets: Bootstrap with GSM8K, fan out to domains; next move, fork the repo, test your Llama mashups.
Your turn: This isn’t armchair theory—it’s your next prototype. What if your “little tutor” unlocks the LLM frontier?
How to Implement LightReasoner: Step-by-Step Guide
-
Setup Environment: git clone https://github.com/HKUDS/LightReasoner.git && cd LightReasoner && pip install -r requirements.txt. -
Download Models: huggingface-cli download Qwen/Qwen2.5-Math-1.5B --local-dir ./Qwen2.5-Math-1.5B(expert); same for 0.5B amateur. -
Prep Data: python data_prep.py(GSM8K default). -
Sample: python LightR_sampling.py --max_questions 1000. -
Fine-Tune: python LightR_finetuning.py(tweak paths). -
Merge & Eval: python merge.py; hit /evaluation/toolkit for benchmarks.
Expect: +10% accuracy in 1 hour, 80% resource cut.
FAQ: Your Burning Questions Answered
Q: Which models pair best with LightR?
A: Experts like Qwen-Math series or DeepSeek; amateurs at 0.5B scale—balance the gap. Llama works, but tweak β.
Q: No GPU? Can I still run it?
A: Colab’s free T4 handles sampling; LoRA tuning at batch=1. Docs recommend H100, but drop max_questions=100 for low-spec.
Q: Why skip ground-truth labels?
A: Contrast signals are self-supervised, dodging annotation hassles. Paper proves: Zero labels, still +4.7% over SFT.
Engineering Checklist (Copy-Paste to Your Issue Tracker)
-
[ ] Clone repo & pip install -r requirements.txt -
[ ] Download expert (Qwen2.5-Math-1.5B)/amateur (Qwen2.5-0.5B) models -
[ ] Run data_prep.pyfor GSM8K data -
[ ] Test sampling: LightR_sampling.py --max_questions 10, verify KL>β steps -
[ ] Fine-tune: LightR_finetuning.py, tailfinetune.log -
[ ] Merge & eval: merge.py+ Qwen toolkit on test set -
[ ] Benchmark check: Accuracy > baseline +5%, time <1h (H100) -
[ ] Feedback: Share your Expert-Amateur pairing wins!
2 Thought Provokers / Exercises
-
Thought Question: For code gen with Llama-3B as expert and Qwen-0.5B as amateur, how should you tune KL threshold β? Why?
Answer: Set β to 1.5-2.0 (higher than math’s 1.0)—code’s more structured, divergences sharper; ups noise filter, zeroing in on syntax/logic chokepoints for better generalization. -
Exercise: Sample 100 prompts with LightR, compute avg high-KL step ratio; expect <15%. If >20%, what to tweak?
Answer: Expect 12% (per README hints); overage? Cut max_questions or swap to weaker amateur (e.g., plain Qwen-0.1B), trimming redundant noise for cleaner signals.
