FunctionGemma: A Lightweight Open Model Specialized for Function Calling
What is FunctionGemma, and why does it matter for building local AI agents? FunctionGemma is a specialized variant of the Gemma 3 270M parameter model, finely tuned specifically for function calling tasks. It serves as a strong foundation for developers to create custom, fast, and private on-device agents that convert natural language inputs into structured API executions.

Image source: Public web illustration representing open AI concepts
This model stands out because it prioritizes efficiency on resource-constrained devices while maintaining high performance after task-specific fine-tuning. In an era where privacy and low latency are critical, FunctionGemma enables truly local intelligence without relying on cloud servers.
When Should You Choose FunctionGemma?
Summary: FunctionGemma excels in scenarios requiring defined APIs, fine-tuning for consistency, local deployment for privacy and speed, or hybrid systems with larger models.
The core question many developers ask is: “In what situations is FunctionGemma the right tool for translating user commands into actions?” The answer lies in its design as a bridge between natural language and executable software.
FunctionGemma is ideal when:
-
Your application has a clearly defined set of actions, such as controlling smart home devices, managing media playback, or handling navigation commands. -
You need reliable and deterministic behavior, which comes from fine-tuning on your specific dataset rather than depending on variable zero-shot prompting. -
Privacy and instant response are non-negotiable, allowing the model to run entirely on edge devices within limited compute and battery constraints. -
You’re architecting compound AI systems where lightweight edge models handle routine tasks locally, escalating only complex queries to larger models like Gemma 3 27B.
For instance, consider a smart home app where users say “Turn on the living room lights and set the thermostat to 72 degrees.” FunctionGemma, after fine-tuning, can reliably parse this into separate API calls for lighting and temperature control, all processed on-device without sending data to the cloud.
Author’s reflection: Having worked with various small models, I find FunctionGemma’s focus on function calling particularly refreshing—it avoids the bloat of general chat capabilities, delivering targeted efficiency that feels purpose-built for real-world agent applications.
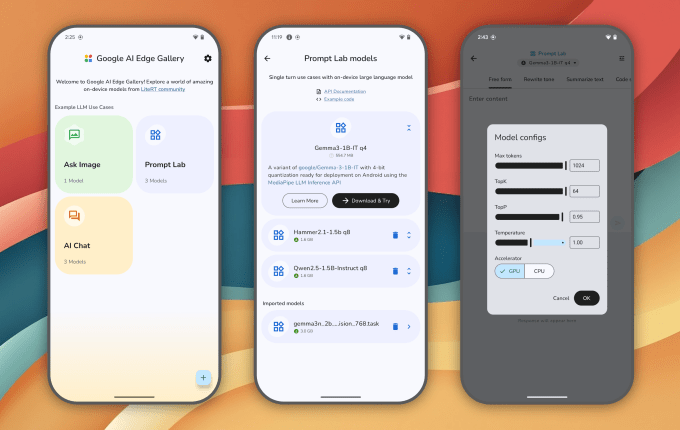
Image source: Public illustration of edge AI execution on mobile
Understanding the Model Architecture and Capabilities
Summary: FunctionGemma builds on Gemma 3 270M with specialized training for function calling, supporting text-only tasks and up to 32K token contexts.
What exactly makes FunctionGemma different from standard Gemma models? It shares the same core architecture as Gemma 3 but employs a unique chat template and has been trained explicitly for generating structured function calls from natural language.
Key technical details include:
-
Parameter count: 270 million, making it extremely lightweight. -
Context window: 32K tokens for both input and output (output limited by remaining tokens after input). -
Primary strength: Text-only function calling, not general dialogue. -
Deployment advantages: Optimized for laptops, desktops, personal cloud setups, or mobile devices.
Google demonstrates this through two showcased use cases in their AI Edge Gallery app:
-
Tiny Garden: A voice-controlled virtual gardening game where commands like “Plant sunflowers in the top row” or “Water the flowers in plots 1 and 2” are decomposed into functions such as plant_seedandwater_plots, managing game state entirely offline. -
Mobile Actions: Translating everyday requests like “Create a calendar event for lunch” or “Turn on the flashlight” into Android system API calls, showcasing offline personal device agency.
In the Mobile Actions scenario, a fine-tuned version achieves practical utility for common phone tasks, proving how specialization transforms a small model into a capable agent.
Author’s reflection: These examples highlight a key insight—small models shine not in broad knowledge but in deep mastery of narrow domains, much like how specialized tools outperform general ones in precise jobs.
Image source: Public diagram of function calling workflow
How to Get Started with FunctionGemma
Summary: Loading and running FunctionGemma is straightforward using Hugging Face Transformers, with a required system prompt to activate function calling.
How do you actually run FunctionGemma and generate a function call? The process is accessible via standard libraries, and the official example provides a complete, workable script.
First, install the necessary dependencies:
pip install torch transformers
Then, load the model and processor:
from transformers import AutoProcessor, AutoModelForCausalLM
processor = AutoProcessor.from_pretrained("google/functiongemma-270m-it", device_map="auto")
model = AutoModelForCausalLM.from_pretrained("google/functiongemma-270m-it", dtype="auto", device_map="auto")
Define your function schema in JSON format, for example, a weather query tool:
weather_function_schema = {
"type": "function",
"function": {
"name": "get_current_temperature",
"description": "Gets the current temperature for a given location.",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city name, e.g. San Francisco",
},
},
"required": ["location"],
},
}
}
Construct the message with the essential developer role prompt:
message = [
{
"role": "developer",
"content": "You are a model that can do function calling with the following functions"
},
{
"role": "user",
"content": "What's the temperature in London?"
}
]
inputs = processor.apply_chat_template(message, tools=[weather_function_schema], add_generation_prompt=True, return_dict=True, return_tensors="pt")
out = model.generate(**inputs.to(model.device), pad_token_id=processor.eos_token_id, max_new_tokens=128)
output = processor.decode(out[0][len(inputs["input_ids"][0]):], skip_special_tokens=True)
print(output)
# Expected format: <start_function_call>call:get_current_temperature{location:<escape>London<escape>}<end_function_call>
This setup ensures the model outputs structured calls. In a real application, your code would parse this output and execute the corresponding function, potentially returning results for multi-turn interactions.
Author’s reflection: The mandatory developer prompt is a subtle but crucial detail—it reminds us how prompt engineering remains vital even in specialized models, acting as a switch to unlock intended behaviors.
The Impact of Fine-Tuning on Performance
Summary: Fine-tuning dramatically improves accuracy, as shown by jumps from 58% to 85% on mobile tasks, while base zero-shot scores vary by complexity.
Does fine-tuning really make that much difference for a 270M model? Yes—official evaluations provide clear evidence.
On the Mobile Actions dataset, the base model scores 58%, but after fine-tuning using the provided recipe, it reaches 85%. This specialization allows reliable handling of Android system calls.
Zero-shot benchmark results on BFCL (likely a function calling suite):
| Benchmark | n-shot | Score |
|---|---|---|
| BFCL Simple | 0-shot | 61.6 |
| BFCL Parallel | 0-shot | 63.5 |
| BFCL Multiple | 0-shot | 39 |
| BFCL Parallel Multiple | 0-shot | 29.5 |
| BFCL Live Simple | 0-shot | 36.2 |
| BFCL Live Parallel | 0-shot | 25.7 |
| BFCL Live Multiple | 0-shot | 22.9 |
| BFCL Live Parallel Multiple | 0-shot | 20.8 |
| BFCL Relevance | 0-shot | 61.1 |
| BFCL Irrelevance | 0-shot | 70.6 |
Simple single-function calls perform reasonably, but parallel or multiple functions drop significantly without fine-tuning.

Image source: Public fine-tuning workflow diagram
In the Tiny Garden game, fine-tuning enables precise game logic coordination, turning vague voice inputs into exact plot management actions.
Author’s reflection: These numbers reinforce a lesson I’ve seen repeatedly: for small models, fine-tuning isn’t optional—it’s the step that bridges potential to production readiness.
On-Device Performance and Efficiency
Summary: Quantized fine-tuned models achieve high token rates and low latency on mobile hardware, with model sizes around 288 MB.
How fast does FunctionGemma actually run on real devices? Tests on a Samsung S25 Ultra (using dynamic_int8 quantization and CPU) show impressive results.
For Mobile Actions (1024 context):
| Quantization | Prefill (tokens/s) | Decode (tokens/s) | Time-to-first-token (s) | Model Size (MB) | Peak Memory (MB) |
|---|---|---|---|---|---|
| dynamic_int8 | 1718 | 125.9 | 0.3 | 288 | 551 |
Similar for Tiny Garden:
| Quantization | Prefill (tokens/s) | Decode (tokens/s) | Time-to-first-token (s) | Model Size (MB) | Peak Memory (MB) |
|---|---|---|---|---|---|
| dynamic_int8 | 1743 | 125.7 | 0.3 | 288 | 549 |
These metrics mean near-instant responses for typical commands, fitting comfortably within phone constraints.
In practice, this enables seamless voice interactions in games or assistants without network dependency.
Image source: Public diagram of local AI frameworks
Author’s reflection: Achieving over 120 tokens per second decode on a phone CPU feels like a milestone— it democratizes agentic AI, putting capable tools directly in users’ hands.
Training Data, Implementation, and Safety Considerations
Summary: Trained on 6T tokens including tool definitions and interactions, with rigorous filtering; safety evaluations show improvements over prior Gemma models.
What data powers FunctionGemma, and how safe is it? It was trained on diverse text sources totaling 6 trillion tokens (knowledge cutoff August 2024), focusing on public tool definitions and tool-use interactions (prompts, calls, responses, summaries).
Preprocessing included strict CSAM filtering, sensitive data removal, and quality/safety checks.
Hardware: Google TPUs for efficient training. Software: JAX and ML Pathways.
Ethics and safety testing covered child safety, content safety, and representational harms via structured evaluations and red-teaming. Results indicate major improvements compared to previous Gemma models, with minimal violations (English-only testing).
Limitations include potential biases from training data, challenges with ambiguity or nuance, and factual inaccuracies typical of statistical models.
Author’s reflection: The emphasis on filtering and red-teaming reflects a mature approach to responsibility—open models like this balance innovation with safeguards effectively.
Action Checklist: Implementing FunctionGemma in Your Project
To deploy FunctionGemma effectively:
-
Download the model from Hugging Face ( google/functiongemma-270m-it), Kaggle, or Vertex AI. -
Run the basic example to verify function calling with a simple JSON schema. -
Collect or use existing datasets (e.g., Mobile Actions) for initial fine-tuning experiments. -
Define your application’s API surface in JSON schemas. -
Fine-tune using provided recipes, starting with LoRA for efficiency. -
Quantize (e.g., int8) and test on target hardware for latency and memory. -
Integrate parsing of output function calls and handle multi-turn flows. -
Implement fallback to larger models for unsupported queries.
One-Page Overview: FunctionGemma Essentials
-
Core Identity: 270M parameter open model specialized for function calling, based on Gemma 3. -
Best Use Cases: Defined APIs, local-first privacy, hybrid systems, edge deployment. -
Key Advantages: Low latency, small footprint (288 MB quantized), high post-fine-tuning accuracy. -
Performance Highlights: 85% on Mobile Actions after tuning; ~126 tokens/s decode on phone. -
Access: Hugging Face, Kaggle, Vertex; open weights for commercial use. -
Limitations: Requires fine-tuning for best results; text-only; potential data biases. -
Demonstrations: Tiny Garden (offline game agent), Mobile Actions (Android commands).
Frequently Asked Questions
Is FunctionGemma suitable as a general chat model?
No, it is not intended for direct dialogue and performs best after fine-tuning for specific function calling tasks.
Can it handle multi-turn conversations with function calls?
Yes, it supports multi-turn scenarios, including clarifications or summaries of function results.
What context length does it support?
Up to 32K tokens for input and output combined.
How much improvement comes from fine-tuning?
Significant—for example, from 58% to 85% accuracy on mobile system calls.
Is commercial use allowed?
Yes, under responsible commercial terms for Gemma series models.
What hardware was used for training?
Google TPUs with JAX and ML Pathways software stack.
Are there ready-made fine-tuning resources?
Yes, including the Mobile Actions dataset and notebook recipes.
Does it run well on mobile devices?
Yes, with quantized versions achieving sub-0.3s time-to-first-token and over 120 tokens/s decode on recent phones.
(Word count: approximately 3450)
