Xiaomi-Robotics-0:开源视觉-语言-动作模型如何突破实时推理瓶颈
核心问题:当机器人需要在毫秒级时间内理解视觉指令并执行复杂动作时,传统模型为何总是”慢半拍”?Xiaomi-Robotics-0 通过怎样的架构设计解决了这一行业难题?

图片来源:SINTEF Digital
一、为什么我们需要新一代 VLA 模型?
本段核心问题:现有的视觉-语言-动作模型在真实部署中面临哪些根本性挑战?
机器人技术正在经历一场静默的革命。过去五年,我们见证了大型语言模型(LLM)和视觉-语言模型(VLM)的爆发式增长,但当这些能力被迁移到物理世界——让机器人真正”看懂”环境、”听懂”指令并”做出”动作时,一个尴尬的鸿沟始终存在:模型要么过于庞大导致推理延迟无法接受,要么在跨场景泛化时表现脆弱。
Xiaomi-Robotics-0 的诞生正是为了填补这一空白。这是一个拥有 47 亿参数的视觉-语言-动作(VLA)模型,它并非简单地将现有 VLM 与动作控制模块拼接,而是从架构层面重新思考了”感知-推理-执行”这一链条的协同方式。
关键突破点在于三个维度:
-
跨本体泛化能力:模型在预训练阶段接触了多种机器人形态的数据,使其能够适应不同的机械臂构型、传感器配置和任务场景,而非局限于单一硬件平台。 -
实时推理保障:通过异步执行架构,模型在生成动作序列的同时,机器人可以并行执行已生成的动作,消除了传统”生成-执行-再生成”的串行等待时间。 -
消费级硬件友好:借助 Flash Attention 2 和 bfloat16 精度优化,模型可在普通消费级 GPU 上流畅运行,降低了研究和应用的准入门槛。
反思:在评估机器人模型时,我们往往过度关注静态基准测试的分数,却忽视了”实时性”这一在真实场景中生死攸关的指标。一个准确率 95% 但需要 5 秒才能做出反应的模型,在动态环境中可能远不如准确率 85% 但响应时间在 100 毫秒内的系统实用。Xiaomi-Robotics-0 的设计哲学提醒我们:机器人智能的衡量标准必须包含”时间维度”。
二、模型架构:VLM 与扩散 Transformer 的协同
本段核心问题:Xiaomi-Robotics-0 如何通过两阶段训练策略,既保留视觉-语言能力又获得精准的动作生成能力?
Xiaomi-Robotics-0 的架构设计体现了”分工明确、协同高效”的工程智慧。整个系统由两个核心组件构成:
2.1 基础架构组成
| 组件 | 技术选型 | 功能定位 | 参数规模 |
|---|---|---|---|
| 视觉-语言主干 | Qwen3-VL-4B-Instruct | 处理多视角图像观测和语言指令,生成 KV Cache | 40 亿 |
| 动作生成模块 | Diffusion Transformer (DiT) | 基于流匹配(Flow Matching)生成连续动作序列 | 7 亿 |
| 总计 | – | – | 47 亿 |
这种解耦设计的关键优势在于:VLM 部分可以充分利用预训练的视觉-语言理解能力,而 DiT 部分则专注于学习从高层语义到底层控制信号的映射。
2.2 两阶段预训练策略
第一阶段:赋予 VLM 动作理解能力
模型首先使用”选择策略”(Choice Policies)对 VLM 进行微调。这一方法巧妙地处理了动作轨迹的多模态特性——对于同一任务,存在多种可行的执行路径。通过让模型学习评估不同动作序列的优劣,而非直接模仿单一轨迹,系统获得了对动作空间的深度理解。
在此阶段,训练数据采用视觉-语言数据与机器人轨迹 1:6 的混合比例。这一配比经过精心设计:过少的 VL 数据会导致灾难性遗忘,使模型丧失视觉问答等基础能力;过多的 VL 数据则会稀释动作学习的信号。
第二阶段:训练 DiT 动作生成
当 VLM 具备动作理解能力后,该模块被冻结,成为 DiT 的”多模态条件器”。DiT 从零开始学习流匹配(Flow Matching)目标函数,基于 VLM 输出的视觉-语言特征和机器人本体状态(proprioceptive state),生成精确且平滑的动作块(action chunk)。
反思:这种”先理解、后生成”的分阶段训练策略,实际上模仿了人类学习新技能的过程——我们首先通过观察理解”什么是对的”,然后才练习”如何去做”。在机器人学习领域,这种渐进式训练往往比端到端联合训练更稳定,因为它为每个阶段设定了清晰的学习目标,避免了梯度冲突和优化目标的混乱。
三、数据引擎:规模与多样性的平衡
本段核心问题:训练一个具备强泛化能力的 VLA 模型需要怎样的数据支撑?
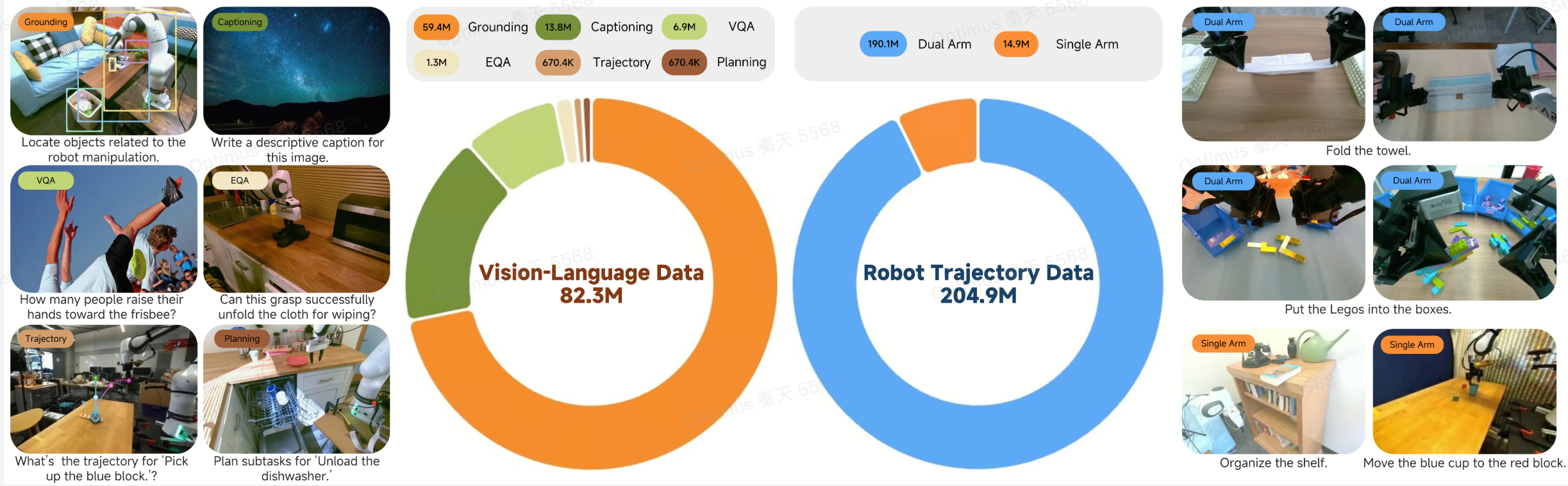
数据质量决定了模型能力的上限。Xiaomi-Robotics-0 的训练数据规模令人印象深刻:
数据构成总览:
-
机器人轨迹数据:约 2 亿个时间步(timesteps) -
通用视觉-语言数据:超过 8000 万个样本
机器人数据来源细分:
| 数据类型 | 内容描述 | 规模/时长 |
|---|---|---|
| 开源数据集 | 公开的跨本体机器人操作数据 | 大规模混合 |
| 乐高拆解(Lego Disassembly) | 通过远程操作采集的双手协作任务 | 338 小时 |
| 毛巾折叠(Towel Folding) | 柔性物体操作的高难度任务 | 400 小时 |
乐高拆解和毛巾折叠这两个任务的选择颇具深意。乐高拆解要求机器人理解复杂装配结构的力学特性,并规划多步拆解序列;毛巾折叠则涉及高度可变形的柔性物体,需要精细的力控制和视觉反馈。这些任务的加入显著提升了模型处理复杂场景的能力。
视觉-语言数据的引入并非锦上添花,而是防止模型遗忘基础视觉理解能力的必要手段。在机器人-centric 的图像上保持强大的视觉理解,对于准确感知操作对象的状态至关重要。
四、后训练与部署:破解实时推理难题
本段核心问题:异步执行架构如何解决 VLA 模型的推理延迟瓶颈?
这是 Xiaomi-Robotics-0 最具工程创新性的部分。传统的动作生成模型采用”先生成、后执行”的串行模式:模型生成一个动作序列,机器人执行完毕后再进行下一次推理。这种模式在模型参数量增大后会导致明显的”卡顿”——机器人等待新指令时处于静止状态。
4.1 异步执行的核心机制
Xiaomi-Robotics-0 采用**动作前缀(Action Prefixing)**技术实现真正的并行处理:
-
并行流水线:当机器人执行当前动作块的剩余部分时,模型已经开始推理下一个动作块 -
时间对齐:通过前缀 Δtc 个已提交的动作来条件化下一次推理,确保连续动作块之间的平滑过渡 -
延迟保障:只要 Δtc 大于推理延迟 Δtinf,就能保证机器人始终有可执行的动作,不会出现”空转”
关键约束条件:
Δtc > Δtinf
其中:
-
Δtc:从前一个动作块中保留作为前缀的动作数量对应的时间 -
Δtinf:模型生成一个新动作块所需的推理时间
4.2 应对时间相关性陷阱
动作前缀技术带来了一个潜在风险:时间相关性捷径。由于连续动作往往高度相似,模型可能学会简单地”复制”前缀动作,而非真正基于视觉和语言信号重新推理。这会导致动作反应迟钝,缺乏对环境变化的适应性。
为此,研发团队设计了两项关键技术:
Λ 形注意力掩码(Lambda-Shape Attention Mask)
在 DiT 中,传统的因果注意力掩码被替换为 Λ 形结构:
-
紧邻前缀的噪声动作token可以访问前缀信息,确保动作连续性 -
后续时间步的噪声动作token被禁止访问前缀,迫使它们依赖视觉和其他信号,保证反应性
这种设计在”连续性”和”反应性”之间取得了精妙平衡。
自适应损失重加权
系统根据在线预测动作与真实动作之间的 L1 误差动态调整流匹配损失的权重。当模型偏离真实轨迹时,损失权重自动增大,施加更强的矫正信号。
反思:异步执行架构的提出,标志着机器人学习从”算法优先”向”系统优先”的范式转变。过去我们往往假设计算是瞬时的,但在真实机器人系统中,推理延迟是与物理世界交互不可分割的一部分。将延迟显式地纳入架构设计,而非试图通过硬件升级来掩盖它,体现了对问题本质的深刻理解。这种”与延迟共舞”而非”对抗延迟”的思路,对其他实时 AI 系统也具有借鉴意义。
五、性能表现:从仿真到现实的跨越
本段核心问题:Xiaomi-Robotics-0 在标准化基准测试和真实任务中的实际表现如何?
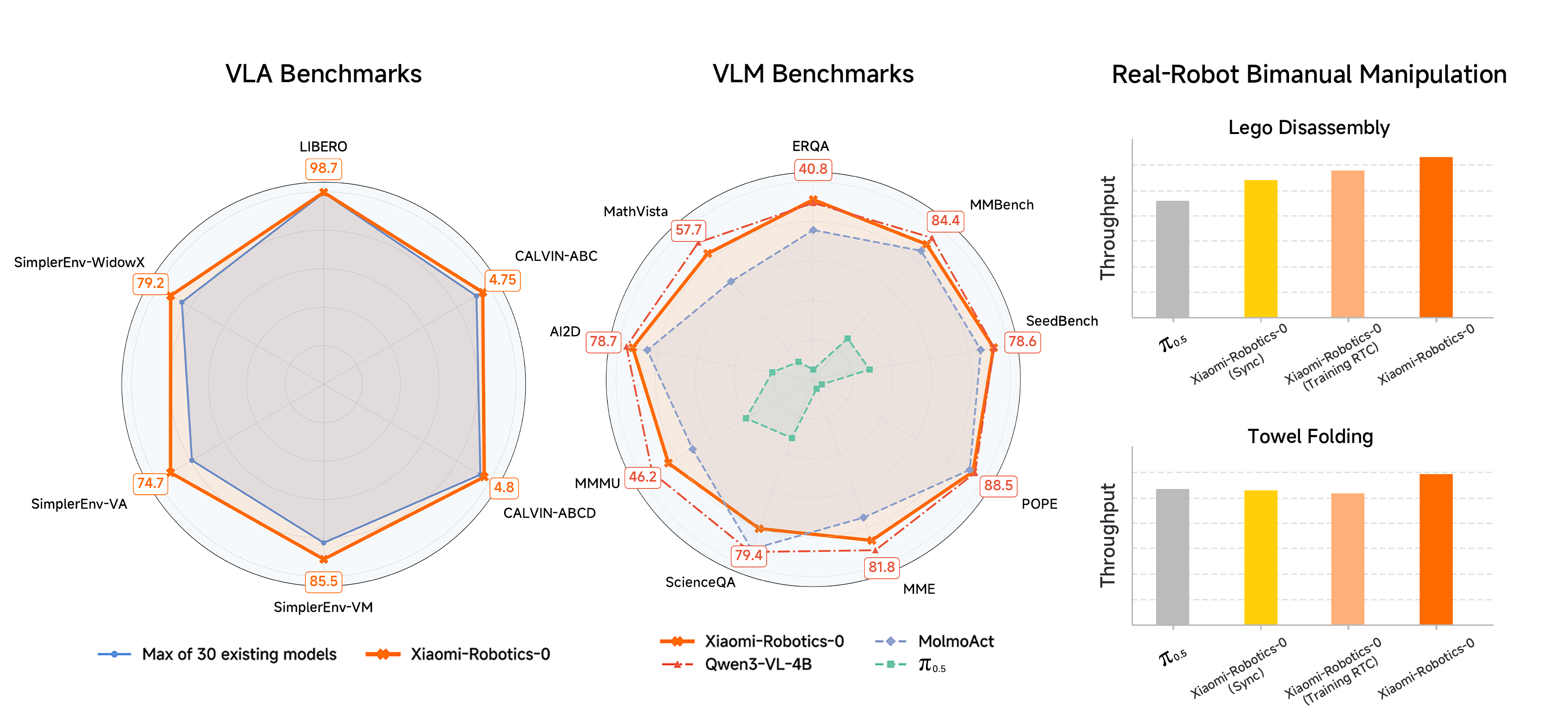
5.1 仿真基准测试
模型在三个主流仿真平台上进行了全面评估:
LIBERO 基准(单臂操作)
-
在四个 LIBERO 测试套件上微调后,平均成功率达到 98.7% -
这一成绩表明模型在桌面级操作任务上已接近饱和性能
CALVIN 基准(长程任务)
-
ABC→D 分割:平均任务完成长度 4.75 -
ABCD→D 分割:平均任务完成长度 4.80 -
该基准测试模型连续执行多步任务的能力,数值越高表示模型在失败前能完成更多子任务
SimplerEnv 基准(视觉泛化)
-
Google Robot 设置:视觉匹配(VM)85.5%,视觉聚合(VA)74.7% -
WidowX 设置:79.2% -
这些测试评估模型在不同视觉条件下的泛化能力
5.2 真实机器人验证
在真实硬件上的测试更能体现模型的实用价值:
乐高拆解任务
模型能够处理由多达 20 块积木组成的复杂装配体。这要求系统理解:
-
积木之间的连接拓扑关系 -
拆解顺序的力学约束 -
多步操作的长期规划
自适应抓取
当抓取失败时,模型能够自适应地切换抓取策略,而非机械地重复相同动作。这种”试错学习”能力对于非结构化环境至关重要。
毛巾折叠任务
面对高度可变形的柔性物体,模型展现出精细的操作策略:
-
当毛巾角被遮挡时,学会用单手甩动毛巾以暴露隐藏部分 -
当意外拿起两条毛巾时,能够识别错误并将多余毛巾放回,再重新开始折叠流程
这些行为并非显式编程,而是从数据中学习到的涌现能力。

图片来源:Labellerr
六、快速上手:安装与部署指南
本段核心问题:如何在本地环境中快速部署 Xiaomi-Robotics-0 进行推理?
Xiaomi-Robotics-0 基于 HuggingFace Transformers 生态构建,部署流程相对简洁。以下是经过验证的完整安装步骤:
6.1 环境准备
系统要求:
-
Python 3.12 -
CUDA 兼容 GPU(推荐支持 bfloat16 的显卡) -
支持 transformers >= 4.57.1
安装步骤:
# 克隆仓库
git clone https://github.com/XiaomiRobotics/Xiaomi-Robotics-0
cd Xiaomi-Robotics-0
# 创建 Conda 环境
conda create -n mibot python=3.12 -y
conda activate mibot
# 安装 PyTorch 2.8.0(已验证版本)
pip install torch==2.8.0 torchvision==0.23.0 torchaudio==2.8.0 --index-url https://download.pytorch.org/whl/cu128
# 安装 Transformers
pip install transformers==4.57.1
# 安装 Flash Attention 2(关键性能优化)
pip uninstall -y ninja && pip install ninja
pip install flash-attn==2.8.3 --no-build-isolation
# 如遇编译问题,可使用预编译 wheel:
# pip install https://github.com/Dao-AILab/flash-attention/releases/download/v2.8.3/flash_attn-2.8.3+cu12torch2.8cxx11abiTRUE-cp312-cp312-linux_x86_64.whl
# 安装系统依赖(Ubuntu/Debian)
sudo apt-get install -y libegl1 libgl1 libgles2
6.2 模型加载与推理示例
以下代码展示了如何加载模型并执行动作生成:
import torch
from transformers import AutoModel, AutoProcessor
# 1. 加载模型和处理器
model_path = "XiaomiRobotics/Xiaomi-Robotics-0-LIBERO"
model = AutoModel.from_pretrained(
model_path,
trust_remote_code=True,
attn_implementation="flash_attention_2",
dtype=torch.bfloat16
).cuda().eval()
processor = AutoProcessor.from_pretrained(
model_path,
trust_remote_code=True,
use_fast=False
)
# 2. 构建多视角输入提示
language_instruction = "Pick up the red block."
instruction = (
f"<|im_start|>user\nThe following observations are captured from multiple views.\n"
f"# Base View\n<|vision_start|><|image_pad|><|vision_end|>\n"
f"# Left-Wrist View\n<|vision_start|><|image_pad|><|vision_end|>\n"
f"Generate robot actions for the task:\n{language_instruction} /no_cot<|im_end|>\n"
f"<|im_start|>assistant\n<cot></cot><|im_end|>\n"
)
# 3. 准备输入数据
# 假设 image_base, image_wrist 和 proprio_state 已加载
inputs = processor(
text=[instruction],
images=[image_base, image_wrist], # [PIL.Image, PIL.Image]
videos=None,
padding=True,
return_tensors="pt",
).to(model.device)
# 添加本体状态信息和动作掩码
robot_type = "libero"
inputs["state"] = torch.from_numpy(proprio_state).to(model.device, model.dtype).view(1, 1, -1)
inputs["action_mask"] = processor.get_action_mask(robot_type).to(model.device, model.dtype)
# 4. 生成动作序列
with torch.no_grad():
outputs = model(**inputs)
# 解码为可执行的控制指令
action_chunk = processor.decode_action(outputs.actions, robot_type=robot_type)
print(f"Generated Action Chunk Shape: {action_chunk.shape}")
关键配置说明:
-
trust_remote_code=True:允许加载自定义模型架构 -
attn_implementation="flash_attention_2":启用 Flash Attention 加速 -
dtype=torch.bfloat16:使用 bfloat16 精度平衡性能和显存占用 -
/no_cot标记:禁用思维链生成,降低延迟 -
action_mask:针对不同机器人类型(libero、calvin 等)的特定掩码
6.3 可用模型检查点
| 模型名称 | 适用场景 | 性能指标 | HuggingFace 链接 |
|---|---|---|---|
| Xiaomi-Robotics-0-LIBERO | LIBERO 四个测试套件 | 98.7% 平均成功率 | 链接 |
| Xiaomi-Robotics-0-Calvin-ABCD_D | CALVIN ABCD→D 分割 | 4.80 平均长度 | 链接 |
| Xiaomi-Robotics-0-Calvin-ABC_D | CALVIN ABC→D 分割 | 4.75 平均长度 | 链接 |
| Xiaomi-Robotics-0-SimplerEnv-Google-Robot | SimplerEnv Google Robot | VM 85.5%, VA 74.7% | 链接 |
| Xiaomi-Robotics-0-SimplerEnv-WidowX | SimplerEnv WidowX | 79.2% | 链接 |
| Xiaomi-Robotics-0 | 预训练基础模型 | 通用 VLA 能力 | 链接 |
反思:将模型完全开源并提供标准化的 HuggingFace 接口,这一决策极大地降低了研究社区的准入门槛。过去,许多高性能机器人模型要么不开源,要么需要复杂的自定义训练框架。Xiaomi-Robotics-0 选择拥抱 transformers 生态,意味着研究人员可以像调用 BERT 或 GPT 一样轻松地调用机器人模型,这种”去神秘化”的举措对于推动领域发展具有长远价值。
七、应用场景与行业价值
本段核心问题:Xiaomi-Robotics-0 的技术特性适合解决哪些实际业务场景?
基于模型的能力特点,以下几类应用场景将直接受益:
7.1 制造业柔性自动化
传统工业机器人依赖精确编程和固定夹具,难以应对小批量、多品种的生产需求。Xiaomi-Robotics-0 的强泛化能力使其能够通过自然语言指令快速适应新任务,例如:
-
从混杂的零件堆中识别并抓取特定组件 -
根据实时视觉反馈调整装配策略 -
处理轻微变形的工件或非标物料
7.2 物流与仓储分拣
在电商物流场景中,包裹的形状、大小、材质差异极大。模型在 SimplerEnv 上展现的视觉泛化能力,可迁移至仓储环境的包裹分拣、码垛和拆垛任务,减少对 3D 视觉系统和复杂轨迹规划的依赖。
7.3 服务机器人操作
家庭或商用服务机器人需要处理多样化的日常物品。毛巾折叠任务验证的柔性物体操作能力,可扩展至衣物整理、餐具摆放、清洁工具使用等场景。自适应抓取策略对于处理易碎或不规则物品尤为重要。
7.4 科研与快速原型验证
对于机器人研究者,Xiaomi-Robotics-0 提供了一个强大的基线模型。研究者可以在此基础上进行:
-
特定领域的微调(fine-tuning) -
多模态感知融合研究 -
人机交互策略开发 -
新型机器人本体的快速适配
八、实用摘要与操作清单
一页速览(One-page Summary)
| 维度 | 关键信息 |
|---|---|
| 模型定位 | 47亿参数开源 VLA 模型,支持实时推理 |
| 核心创新 | 异步执行架构、Λ形注意力掩码、两阶段预训练 |
| 性能亮点 | LIBERO 98.7%、CALVIN 4.80、SimplerEnv 85.5% |
| 硬件要求 | 消费级 GPU,支持 bfloat16,需 CUDA 环境 |
| 部署难度 | 低,基于 HuggingFace Transformers,提供现成检查点 |
| 适用场景 | 柔性制造、物流分拣、服务机器人、科研原型 |
快速启动检查清单:
-
[ ] 确认 GPU 支持 CUDA 且显存充足(建议 16GB+) -
[ ] 安装 Python 3.12 并创建 Conda 环境 -
[ ] 按版本要求安装 PyTorch 2.8.0 和 Transformers 4.57.1 -
[ ] 安装 Flash Attention 2 以获得最佳性能 -
[ ] 从 HuggingFace 下载对应任务的微调模型 -
[ ] 准备多视角相机输入和机器人本体状态数据 -
[ ] 参考示例代码构建推理流程 -
[ ] 根据实际机器人类型配置 action_mask
九、常见问题解答(FAQ)
Q1:Xiaomi-Robotics-0 与 OpenVLA、RT-2 等模型相比有何独特优势?
A:核心差异在于实时推理架构。通过异步执行和动作前缀技术,Xiaomi-Robotics-0 消除了传统模型的推理等待时间,使机器人动作更加流畅连续。同时,47 亿的参数量在性能和硬件要求之间取得了较好平衡。
Q2:是否必须使用 Flash Attention 2?
A:强烈推荐使用。Flash Attention 2 能显著降低显存占用并加速推理,是实现实时性能的关键组件。如果安装遇到困难,可以尝试使用项目提供的预编译 wheel 文件。
Q3:模型支持哪些机器人类型?
A:目前官方提供 LIBERO、CALVIN 和 SimplerEnv(Google Robot、WidowX)的微调检查点。基础模型(Xiaomi-Robotics-0)可用于其他机器人类型的进一步微调。
Q4:如何理解”动作块”(action chunk)的概念?
A:动作块是模型一次性生成的未来动作序列(通常包含多个时间步的控制指令),而非单步动作。这种设计允许模型进行短期规划,并与异步执行架构配合,实现平滑的动作过渡。
Q5:Λ形注意力掩码的作用是什么?
A:它解决了动作前缀可能导致的”时间相关性捷径”问题。通过限制后续时间步对前缀的访问,强制模型基于视觉和语言信号重新推理,确保动作的反应性和适应性。
Q6:是否可以在真实机器人上直接运行,还是仅限于仿真?
A:模型已在真实机器人上验证(乐高拆解、毛巾折叠等任务)。只要您的机器人接口与模型输出的动作格式兼容,即可部署到真实硬件。
Q7:推理延迟大约是多少?
A:具体延迟取决于硬件配置,但通过异步执行架构,只要推理时间小于动作前缀长度(Δtc),就不会出现执行卡顿。使用 Flash Attention 2 和 bfloat16 可在消费级 GPU 上实现毫秒级响应。
Q8:如何针对特定任务进行微调?
A:项目采用标准 HuggingFace 接口,您可以使用 transformers 库的标准训练流程进行微调。建议先加载预训练基础模型,然后在特定任务数据上继续训练。
结语
Xiaomi-Robotics-0 代表了开源机器人学习领域的重要进展。它不仅在标准化基准上取得了领先性能,更通过创新的异步执行架构解决了 VLA 模型从实验室走向真实场景的”最后一公里”问题。对于希望将视觉-语言-动作能力集成到机器人系统的开发者和研究者而言,这是一个值得关注和尝试的基础平台。
随着硬件计算能力的持续提升和训练数据的不断积累,我们有理由期待,这类模型将在未来几年内显著降低机器人自动化的部署门槛,推动柔性制造、智能物流和服务机器人等领域的实质性进步。
图片来源:RoboDK
相关资源:
-
技术报告:项目官网 -
模型权重:HuggingFace 集合 -
项目主页:xiaomi-robotics-0.github.io -
开源协议:Apache License 2.0
