

Google AI 发布 VaultGemma:具备差分隐私训练的最大规模开放模型
在人工智能快速发展的今天,大型语言模型不仅需要强大的能力,更需要具备隐私保护的特性。Google AI Research 与 DeepMind 联合发布了 VaultGemma 1B,这是目前最大的、完全基于差分隐私训练并开放权重的语言模型。该模型的发布标志着 AI 模型在性能与隐私保护之间取得了重要突破。
为什么大型语言模型需要差分隐私?
大型语言模型通常在海量网络数据上进行训练,但这些数据中可能包含大量敏感或个人身份信息。模型在学习过程中容易记住训练数据的具体内容,从而导致隐私泄露风险。差分隐私通过数学方法严格限制单个训练样本对模型的影响,为模型提供了可证明的隐私保证。
与仅在微调阶段应用差分隐私的方法不同,VaultGemma 在整个预训练过程中都实施了差分隐私机制。这意味着隐私保护从模型构建的最初阶段就已融入,确保了更高层次的数据安全。

VaultGemma 的模型架构是怎样的?
VaultGemma 延续了 Gemma 系列的基本架构,但在多个关键方面进行了优化以支持高效的差分隐私训练。
以下是该模型的主要架构参数:
| 参数 | 值 |
|---|---|
| 参数量 | 1B |
| 层数 | 26 |
| 注意力机制 | 多查询注意力(MQA) |
| 前馈网络维度 | 13,824 |
| 词汇表大小 | 256K |
| 序列长度 | 1024 |
该模型采用仅解码器(Decoder-only)的 Transformer 结构,使用 GeGLU 激活函数和 RMSNorm 进行归一化。值得一提的是,序列长度被缩短至 1024,这显著降低了计算成本,使得在差分隐私约束下也能使用较大的批大小。


训练数据是如何处理和过滤的?
VaultGemma 使用了与 Gemma 2 相同的训练数据,总计 13 万亿个 token。数据来源包括网页文档、代码和科学文章,以英文为主。
数据处理过程包括多个过滤阶段:
-
移除不安全或敏感内容; -
减少个人信息的暴露; -
防止评估数据被污染。
这些步骤不仅提升了模型的安全性,也保证了基准测试的公平性。
差分隐私在训练中是如何实现的?
VaultGemma 使用差分隐私随机梯度下降(DP-SGD)进行训练,通过对梯度进行裁剪和添加高斯噪声来实现隐私保护。该实现基于 JAX Privacy,并引入了多项优化以提升扩展性:
-
向量化逐样本梯度裁剪,提高并行效率; -
梯度累积,以模拟大批次训练; -
截断泊松子采样,在数据加载过程中实现高效动态采样。
模型实现了序列级别的正式差分隐私保证,其隐私参数为(ε ≤ 2.0,δ ≤ 1.1e−10)。
实际场景示例:
假设一家医院希望使用语言模型处理电子病历,但又担心患者隐私泄露。使用 VaultGemma 这类具备差分隐私训练的模型,可以在不暴露任何个体病历信息的前提下,完成诸如诊断辅助或医学文献生成等任务。
差分隐私训练中的扩展规律有何不同?
在差分隐私约束下训练大规模模型需要新的扩展策略。VaultGemma 团队提出了专为差分隐私设计的扩展规律,主要包括三大创新:
-
使用二次拟合对不同训练配置中的最优学习率进行建模; -
通过参数化推断损失值,减少对中间检查点的依赖; -
使用半参数拟合,泛化到不同的模型大小、训练步数和噪声-批次比例。
该方法能够准确预测可实现损失,并在 TPUv6e 训练集群上高效利用资源。
训练配置与基础设施概述
VaultGemma 在 2048 个 TPUv6e 芯片上完成训练,使用了 GSPMD 分区和 MegaScale XLA 编译技术。其主要训练超参数如下:
| 超参数 | 值 |
|---|---|
| 批大小 | ~518K tokens |
| 训练迭代次数 | 100,000 |
| 噪声乘数 | 0.614 |
最终实现的损失值与扩展规律的预测相差不到 1%,验证了该方法的有效性。
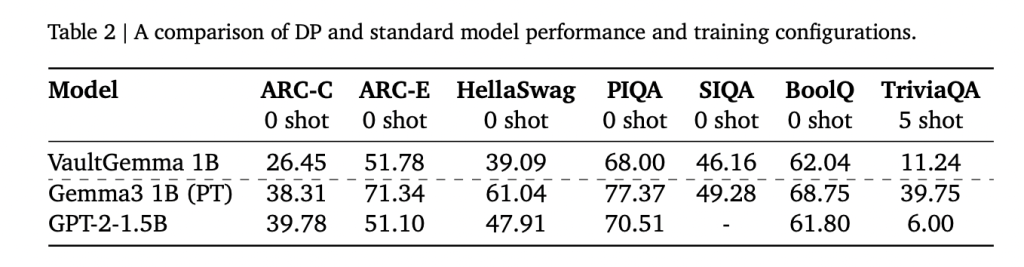
VaultGemma 与非隐私模型的性能对比
在多项学术基准测试中,VaultGemma 的表现虽略逊于非隐私模型,但仍显示出较强的实用性:
| 任务 | VaultGemma 1B | Gemma3 1B | GPT-2-1.5B |
|---|---|---|---|
| ARC-C | 26.45 | 38.31 | 39.78 |
| PIQA | 68.0 | 77.37 | 70.51 |
| TriviaQA (5-shot) | 11.24 | 39.75 | 6.00 |
这些结果表明,当前的差分隐私模型在性能上大致相当于五年前的非隐私模型。更重要的是,记忆测试显示,VaultGemma 中未检测到任何训练数据泄露,这与非隐私版本的 Gemma 模型形成鲜明对比。

总结与实际意义
VaultGemma 的发布证明,在保证差分隐私的前提下,仍然可以训练出实用的大规模语言模型。尽管目前与完全开放训练的模型相比还存在一定的性能差距,但其在隐私保护方面的优势不可忽视。
该模型不仅为学术界和工业界提供了重要的基础资源,也为我们展示了隐私与效用之间可实现的平衡。未来,随着算法和训练策略的进一步优化,差分隐私语言模型有望在医疗、金融、法律等对数据敏感度要求极高的领域发挥更大价值。
作者反思:
在深入研究 VaultGemma 的技术细节后,我更加确信,隐私与性能并非完全对立。通过科学的噪声控制与优化策略,我们可以在不大幅牺牲模型能力的前提下,实现真正意义上的数据保护。这也为下一代可信 AI 系统的设计指明了方向。
实用摘要与操作清单
-
适用场景:处理敏感数据的文本生成、问答、摘要等任务。 -
推荐配置:使用 Hugging Face 提供的预训练权重,搭配 JAX 或 PyTorch 进行微调。 -
隐私设置:如需进一步训练,建议沿用 DP-SGD 并合理设置噪声乘数与裁剪阈值。 -
评估建议:在任务相关的基准数据集上验证模型效果,并额外进行记忆化测试。
一页速览(One-page Summary)
| 项目 | 说明 |
|---|---|
| 模型名称 | VaultGemma 1B |
| 核心特点 | 完全基于差分隐私训练的大规模开放语言模型 |
| 参数量 | 10亿 |
| 训练数据 | 13万亿 token,多源英文文本 |
| 差分隐私保证 | (ε ≤ 2.0, δ ≤ 1.1e−10) |
| 典型性能 | 接近五年前同等规模非隐私模型 |
| 适用领域 | 医疗、金融、法律等对数据隐私要求较高的场景 |
| 开源地址 | Hugging Face |
常见问题(FAQ)
1. VaultGemma 能否用于商业场景?
是的,该模型权重开放,可用于商业用途,但需遵守相应的许可协议。
2. 如何在自己的数据上微调 VaultGemma?
可使用 Hugging Face 提供的脚本,配合 DP-SGD 训练器进行微调。
3. 差分隐私训练是否一定会降低模型性能?
在当前技术条件下,隐私训练通常会有一定的性能代价,但 VaultGemma 表明这一差距正在缩小。
4. 是否支持多语言任务?
目前模型主要以英文训练,对多语言任务的支持有限。
5. 如何评估模型的隐私保护效果?
可通过记忆化测试,检查模型是否生成训练数据中的原文内容。
6. 能否在消费级 GPU 上运行 VaultGemma?
可以,1B 规模的模型在主流 GPU 上均可加载和推理。
7. 模型是否支持长文本生成?
由于序列长度设定为 1024,建议在长文本任务中使用分段处理或上下文窗口扩展技术。
8. 有没有更大的版本计划?
目前仅发布 1B 版本,但技术报告显示其扩展规律支持更大规模的模型训练。

