

在现代人工智能飞速发展的浪潮中,大型语言模型(LLM)正以前所未有的速度演进。通义千问团队最新推出的 Qwen3-Next-80B 系列模型,正是在这一背景下应运而生的技术成果。该系列不仅显著提升了模型的能力和效率,还针对长文本处理、推理任务和智能体应用等场景做了深度优化。本文将系统性地介绍这一系列模型的核心特性、性能表现以及实际部署方法,为技术研究者和工程实践者提供详实的参考。
一、模型架构与核心创新
Qwen3-Next-80B 系列包括两个版本:Qwen3-Next-80B-A3B-Instruct 和 Qwen3-Next-80B-A3B-Thinking。两者均基于统一的底层架构,但在功能定位上有所区分。Instruct 版本专注于指令遵循与内容生成,而 Thinking 版本强化了复杂推理和思维链(Chain-of-Thought)能力。
1. 关键架构创新
该系列模型引入了多项前沿技术,在保持高性能的同时大幅提升了训练和推理效率:
-
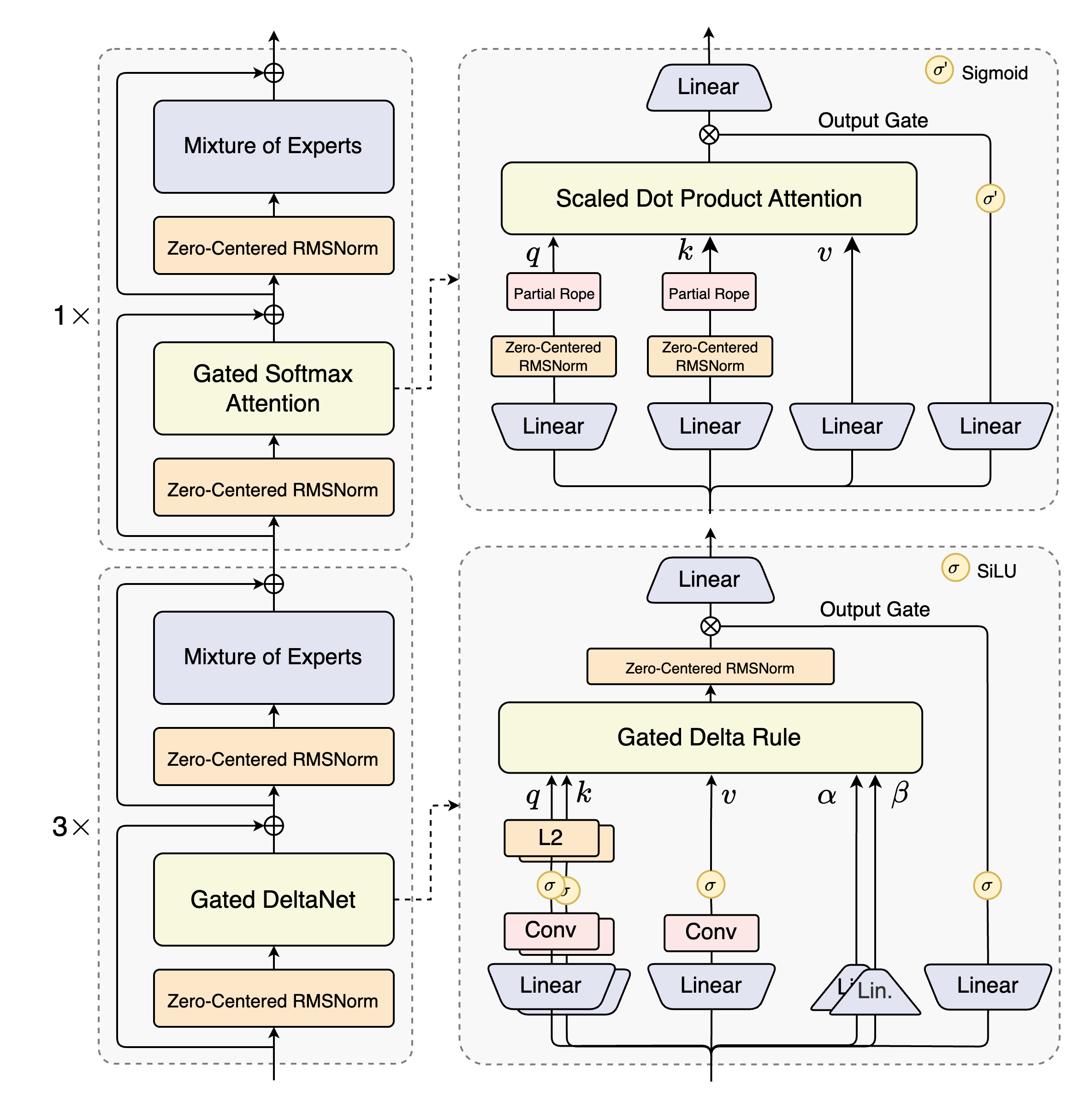
混合注意力机制(Hybrid Attention):
结合了门控 DeltaNet 和门控注意力(Gated Attention),替代传统的标准注意力机制。这一设计显著提升了对长上下文信息的建模效率,支持最高达 26.2万 token 的原生上下文长度,并可通过 YaRN 扩展技术处理超过 100万 token 的文本。 -
高稀疏性混合专家模型(High-Sparsity MoE):
模型总参数量达到 800亿,但每次推理仅激活 30亿参数。这种极低的激活比例(约 3.75%)在几乎保持模型容量的同时,大幅降低了计算开销。 -
多令牌预测(Multi-Token Prediction, MTP):
在预训练阶段同步预测多个后续 token,加速模型训练并提升推理效率。 -
稳定性优化:
采用零中心加权衰减的 LayerNorm 等多种技术,增强训练稳定性,保障模型在不同任务中的鲁棒性。

二、模型性能一览
Qwen3-Next-80B 在多项标准评测中表现出色,以下为部分关键数据对比(百分制或特定分值):
知识能力(Knowledge)
| 模型 | MMLU-Pro | MMLU-Redux | GPQA | SuperGPQA |
|---|---|---|---|---|
| Qwen3-Next-80B-Instruct | 80.6 | 90.9 | 72.9 | 58.8 |
| Qwen3-Next-80B-Thinking | 82.7 | 92.5 | 77.2 | 60.8 |
推理能力(Reasoning)
| 模型 | AIME25 | HMMT25 | LiveBench |
|---|---|---|---|
| Qwen3-Next-80B-Instruct | 69.5 | 54.1 | 75.8 |
| Qwen3-Next-80B-Thinking | 87.8 | 73.9 | 76.6 |
编程能力(Coding)
| 模型 | LiveCodeBench | MultiPL-E | CFEval |
|---|---|---|---|
| Qwen3-Next-80B-Instruct | 56.6 | 87.8 | – |
| Qwen3-Next-80B-Thinking | 68.7 | – | 2071 |
长上下文性能
在长达 100万 token 的 RULER 评测中,Qwen3-Next-80B 也表现出了优秀的性能稳定性,尤其在 128K–256K token 长度范围内准确率保持在90%以上。
三、如何使用 Qwen3-Next-80B
环境安装与模型加载
推荐使用最新版的 Hugging Face transformers 库,并从中调用 ModelScope 中的模型:
pip install git+https://github.com/huggingface/transformers.git@main
以下是一个基本的代码示例,展示如何加载模型并生成文本:
from modelscope import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-Next-80B-A3B-Instruct" # 或 Thinking 版本
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
dtype="auto",
device_map="auto"
)
prompt = "请简要介绍大语言模型。"
messages = [{"role": "user", "content": prompt}]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=16384
)
output = tokenizer.decode(generated_ids[0], skip_special_tokens=True)
print(output)
处理思维内容(Thinking 版本)
若使用 Thinking 版本,模型输出的文本中可能包含 <think>…</think> 标签内的“思考过程”,需额外解析:
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
try:
index = len(output_ids) - output_ids[::-1].index(151668) # 151668 是 </think> 的 token
except ValueError:
index = 0
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip()
final_output = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip()
print("思考内容:", thinking_content)
print("最终回复:", final_output)
四、高效部署与服务化
为充分发挥模型效能,推荐使用专用推理框架如 vLLM 或 SGLang 部署为 OpenAI 兼容的 API 服务。
使用 vLLM 部署
pip install git+https://github.com/vllm-project/vllm.git
VLLM_USE_MODELSCOPE=true VLLM_ALLOW_LONG_MAX_MODEL_LEN=1 \
vllm serve Qwen/Qwen3-Next-80B-A3B-Instruct \
--port 8000 \
--tensor-parallel-size 4 \
--max-model-len 262144
使用 SGLang 部署
pip install 'sglang[all] @ git+https://github.com/sgl-project/sglang.git@main#subdirectory=python'
SGLANG_USE_MODELSCOPE=true SGLANG_ALLOW_OVERWRITE_LONGER_CONTEXT_LEN=1 \
python -m sglang.launch_server \
--model-path Qwen/Qwen3-Next-80B-A3B-Instruct \
--port 30000 \
--tp-size 4 \
--context-length 262144 \
--mem-fraction-static 0.8
五、智能体与工具调用
Qwen3 系列模型在工具调用和智能体行为方面表现突出。推荐使用 Qwen-Agent 框架,大幅降低编码复杂度:
from qwen_agent.agents import Assistant
llm_cfg = {
'model': 'Qwen3-Next-80B-A3B-Thinking',
'model_server': 'http://localhost:8000/v1',
'api_key': 'EMPTY',
}
tools = ['code_interpreter', {'mcpServers': {...}}]
bot = Assistant(llm=llm_cfg, function_list=tools)
messages = [{'role': 'user', 'content': '请分析https://qwenlm.github.io/blog/ 的最新内容'}]
for response in bot.run(messages):
print(response)
六、超长文本处理与 YaRN 扩展
若需处理超过 26.2万 token 的文本,可借助 YaRN 方法扩展上下文长度。以下是在 vLLM 中启用 YaRN 的示例:
VLLM_USE_MODELSCOPE=true VLLM_ALLOW_LONG_MAX_MODEL_LEN=1 \
vllm serve Qwen/Qwen3-Next-80B-A3B-Instruct \
--rope-scaling '{"rope_type":"yarn","factor":4.0,"original_max_position_embeddings":262144}' \
--max-model-len 1010000
七、优化建议与推荐配置
-
采样参数推荐:
-
Instruct 版本: Temperature=0.7, TopP=0.8, TopK=20 -
Thinking 版本: Temperature=0.6, TopP=0.95, TopK=20
-
-
输出长度:
-
常规任务建议输出 16384 token; -
数学、编程等复杂任务推荐使用 32768 或更高。
-
-
提示词设计:
-
数学问题中加入“请逐步推理,并将最终答案置于 \boxed{}中”; -
选择题可要求以 JSON 格式输出答案,如 {"answer": "C"}。
-
结语
通义千问3-Next-80B 系列模型通过多项技术创新,在模型规模、推理效率和应用范围上实现了显著提升。无论是处理长文本、执行复杂推理,还是构建智能体应用,该模型都为开发者提供了强大而高效的底层支持。我们希望本文提供的技术细节与实践方法能够帮助读者更好地理解与应用这一先进模型。
参考文献:
如您认为本文内容对您有帮助,可引用以下文献:
-
Qwen Team. (2025). Qwen3 Technical Report. arXiv:2505.09388. -
Yang, A., et al. (2025). Qwen2.5-1M Technical Report. arXiv:2501.15383.

