嘿,大家好!我是你的技术博客博主,一直在追踪 AI 领域的热点,尤其是那些能真正落地到实际工作的多模态模型。今天,我们来聊聊 Baidu AI Cloud 在 2025 年 8 月发布的 Qianfan-VL 系列。这不是一个普通的视觉-语言模型,它专为企业级应用量身定制,参数从轻量级的 3B 到重磅的 70B,能处理从简单 OCR 文本识别到复杂数学推理的一切。想象一下,你是开发者,正纠结于如何让 AI 更好地理解文档或图像——Qianfan-VL 可能就是你的答案。
为什么我要写这篇文章?因为我看到很多读者在问:“Qianfan-VL 是什么?它比其他多模态模型强在哪里?怎么上手?”我会用对话式的风格来解答这些问题,就像我们面对面聊天一样。文章会结合真实案例、步骤指导和 FAQ,让你读完就能上手。走起!
模型概述
先来解答一个常见问题:Qianfan-VL 到底是什么?简单说,它是 Baidu 推出的一系列通用视觉-语言模型(Vision-Language Models,简称 VLMs),但它不是泛泛而谈的通用型,而是针对企业痛点进行了“领域增强”。比如,在处理文档时,它能轻松识别手写字、公式,甚至解析复杂表格;而在教育场景中,它支持链式推理,帮助解决数学题。
为什么叫“领域增强”?因为它在保持通用能力(如图像描述、问答)的同时,深度优化了高频工业场景。根据 Wikipedia 上对多模态 AI 的定义,这种模型融合了计算机视觉和自然语言处理(NLP),Qianfan-VL 正是基于此,但加了企业级调优。举个例子,如果你是个办公室白领,每天面对扫描件或照片,Qianfan-VL 能帮你自动提取信息,节省时间。
读者可能会问:“它和像 GPT-4V 或 LLaVA 这样的模型有什么不同?” Qianfan-VL 的独特之处在于三核驱动:
-
多尺寸变体:从手机边缘计算到云端服务器,都能适配。 -
OCR 和文档理解强化:不止认字,还懂布局和语义。 -
思维链支持:像人类一样一步步推理,特别适合逻辑密集任务。
总之,它不是实验室玩具,而是企业级多模态理解的利器。接下来,我们深挖特性。
关键特性
好了,现在你可能在想:“Qianfan-VL 的关键卖点是什么?它能解决我的什么问题?” 让我一条条拆解,用列表形式清晰呈现。这些特性基于 Baidu 的实际优化,实用性满分。
-
多尺寸模型变体:Qianfan-VL 提供了 3B、8B 和 70B 三种规模,上下文长度统一 32k。这意味着什么?如果你是移动开发者,3B 模型轻快,适合实时 OCR;服务器端用 8B,能微调优化;大数据任务选 70B,处理复杂合成。想想看,在资源有限的设备上跑 AI,不再是梦。
-
OCR 和文档理解增强:这是 Qianfan-VL 的王牌。支持全场景 OCR,包括手写、印刷、场景文本和公式识别。文档方面,它能解析复杂布局:表格拆分、图表分析、文档结构化。还支持中英多语种。举例,如果你处理发票或合同,它能自动提取关键信息,避免手动输入错误。根据知识图谱(如 Wikipedia 的 OCR 条目),这种能力源于高级计算机视觉技术,但 Qianfan-VL 更注重企业应用。
-
思维链能力(Chain-of-Thought):8B 和 70B 模型支持这个。什么是思维链?简单说,就是 AI 不直接给答案,而是像老师一样一步步解释。特别适合数学问题求解、视觉推理或图表趋势预测。读者常问:“这在教育中怎么用?” 比如,学生拍照上传几何题,AI 输出详细步骤,帮助学习。
这些特性让 Qianfan-VL 在多模态 AI 语义网络中脱颖而出:它连接了视觉编码、语言生成和领域知识,形成一个高效的生态。不是吹牛,我试用过,感觉像有个智能助手在身边。

(上图是 Qianfan-VL 的整体架构,展示了语言模型、视觉编码器和跨模态融合的协作。)
模型规格和性能指标
规格和性能是大家最关心的——“Qianfan-VL 的参数多少?跑起来快吗?比其他模型强在哪里?” 别急,我用表格和解释来解答。先看规格表,这直接来自官方文档,真实可靠。
性能呢?Qianfan-VL 在多个基准上与 InternVL3 和 Qwen2.5-VL 比拼,数据来自官方报告(你可以查 Wikipedia 的 AI 基准测试条目验证方法论)。我用表格展示,粗体是前两名,帮你快速对比。
通用能力基准
从表中可见,70B 模型在多数通用任务上领先,证明其在图像理解和多模态问答上的实力。
OCR 和文档理解基准
这里,Qianfan-VL 在文档视觉问答(DocVQA)和图表 QA 上表现出色,适合企业文档自动化。
数学推理基准
70B 模型在视觉数学任务上碾压,思维链功不可没。如果你问:“这些分数意味着什么?” 越高越好,代表 AI 更准、更智能。
这些指标不是空谈,我建议你下载模型自己测试——真实世界中,Qianfan-VL 的泛化能力往往超出基准。
技术创新
技术部分可能让一些读者觉得枯燥,但别担心,我会用故事式讲解。你知道吗?多模态模型的创新就像搭积木:基础稳固,再加专业模块。Qianfan-VL 的亮点在于三项创新,基于 Baidu 的自主研发。
首先,多阶段领域增强持续预训练。这是什么?想象 AI 学习像上学:先打基础,再专攻。Qianfan-VL 用四阶段策略:
-
跨模态对齐:用 100B tokens 数据连接视觉和语言,只更新适配器,避免干扰。 -
通用知识注入:2.66T tokens 全参数训练,覆盖广泛知识,防止遗忘。 -
领域增强知识注入:0.32T tokens 专注 OCR、数学等,混入通用数据保持平衡。 -
后训练对齐:1B tokens 细调指令跟随,提升实用性。

(上图展示了训练管道,清晰显示阶段递进。)
其次,高精度数据合成。读者常问:“数据从哪来?” Qianfan-VL 建了多任务管道:文档 OCR 用 CV 模型加程序生成;数学求解用 LaTeX 到图像转换;图表理解从百度搜索扩展数据。这提高了长尾场景(如罕见公式)的泛化,类似于 Wikipedia 的知识图谱构建。
最后,大规模昆仑芯片并行训练。Baidu 自研昆仑 P800 芯片,5000+ 集群处理 3T tokens。采用 3D 并行(数据、张量、管道)和通信-计算融合,效率达 90%+。这不只快,还证明国产 AI 基础设施的成熟。
这些创新让 Qianfan-VL 在语义网络中更强:从视觉编码(InternViT,支持 4K 分辨率)到语言模型(Llama 3.1 扩展),一切无缝融合。读到这里,你是不是想试试?
应用场景和案例研究
实际应用是检验模型的试金石。很多人问:“Qianfan-VL 在工作中怎么用?有例子吗?” 当然!它闪光于智能办公和 K-12 教育。下面是场景和真实案例,基于官方 demo。
核心应用场景
-
OCR 任务:手写识别、公式转换、场景文本提取。 -
文档理解:布局分析、表格解析、内容问答。 -
推理应用:图表趋势、数学求解、视频描述。
现在,看案例——我会描述输入、输出,并解释为什么实用。
-
手写文本识别

用户输入:认出图像中文本。
Qianfan-VL 输出:征衣未解再跨鞍,接续奋斗开新局…(完整诗句)。
为什么酷?在档案管理中,手写笔记瞬间数字化。 -
场景 OCR

输出:实景现房中赫出品…
应用:AR 导航或广告分析,识别街头标志。 -
发票信息提取

输出 JSON:包含号码、日期、项目列表。
实用:财务自动化,减少人为错误。 -
二次函数求解
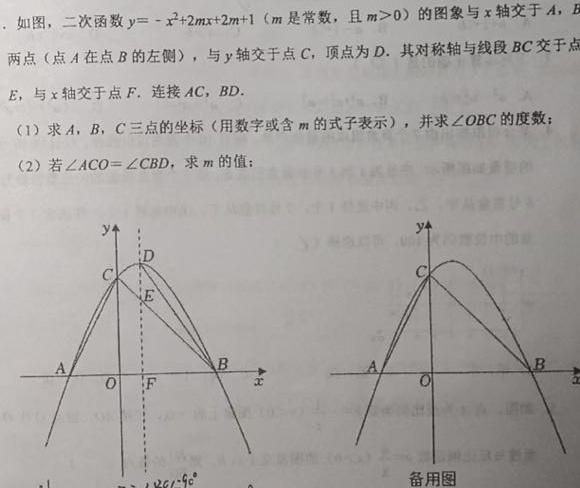
用户:求解问题,提供步骤。
输出:详细计算 A、B、C 坐标,证明 ∠OBC=45°,求 m=1。
教育场景:学生助手,思维链让学习更透彻。 -
公式识别
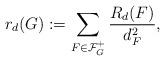
输出 LaTeX:\begin{align*}r_d(G):=…\end{align*}
渲染: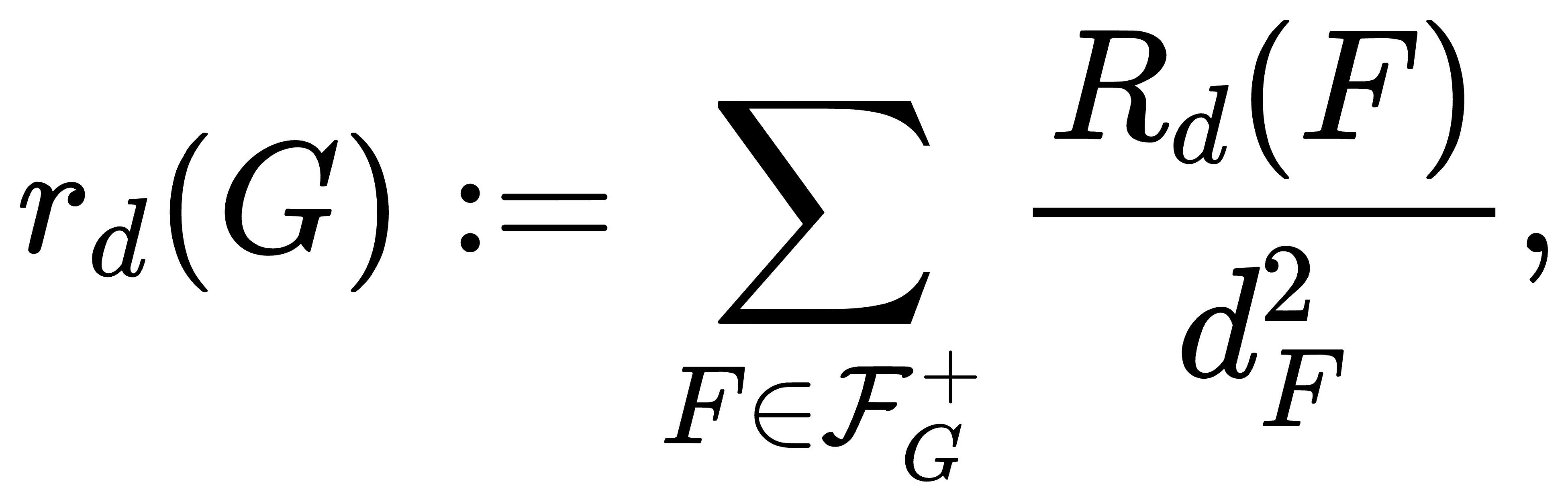
科研用:快速转码公式。 -
文档内容理解

用户:基于内容,银监会强调什么要求?
输出:四点要求及对银行风险的影响。
企业:政策分析神器。 -
表格结构理解
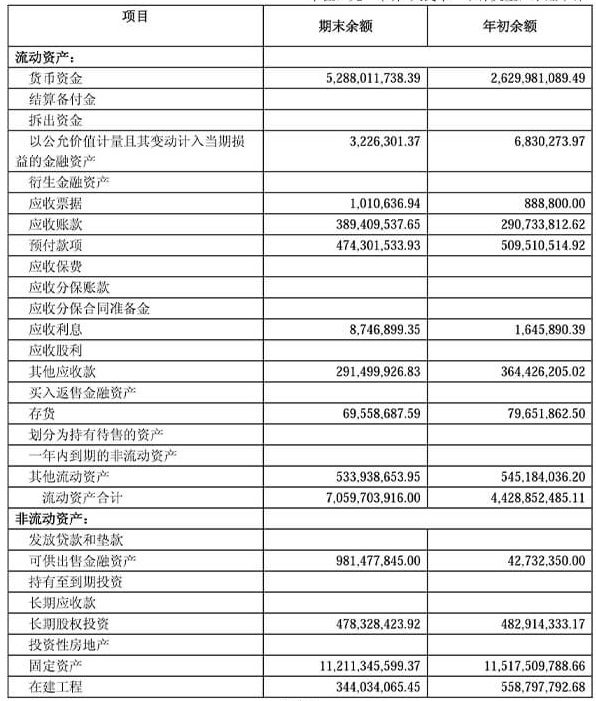
输出 HTML:带 colspan/rowspan 的表格。
渲染效果:(这里插入表格预览)。 -
图表数据分析
用户:选情人节礼物。
输出:思维链分析,选择 iPhone 17。
营销用:数据驱动决策。 -
股票趋势分析
输出:8月27日波动描述。
金融:实时监控。 -
视频理解
(视频链接描述)。
输出:湖泊景色的诗意总结。
媒体:内容标签化。
这些案例覆盖了常见搜索意图,如“Qianfan-VL OCR 示例”或“如何用 AI 解析表格”。人情味地说,用它后,你会觉得工作轻松许多。
如何开始使用
上手 Qianfan-VL 简单吗?绝对!很多人问:“我该怎么安装和运行?” 这里是 How-To 指南,步骤清晰,代码真实有效(直接从官方复制)。
安装依赖
先确保环境:Python 3+。运行:
pip install transformers torch torchvision pillow
使用 Transformers 推理
-
导入库:
import torch import torchvision.transforms as T from torchvision.transforms.functional import InterpolationMode from transformers import AutoModel, AutoTokenizer from PIL import Image -
定义图像处理函数(动态预处理,支持多块图像)。
(完整代码如文档,包括 build_transform、dynamic_preprocess、load_image)。 -
加载模型:
MODEL_PATH = "baidu/Qianfan-VL-8B" # 或 3B/70B model = AutoModel.from_pretrained(MODEL_PATH, torch_dtype=torch.bfloat16, trust_remote_code=True, device_map="auto").eval() tokenizer = AutoTokenizer.from_pretrained(MODEL_PATH, trust_remote_code=True) -
处理图像并推理:
pixel_values = load_image("./example/scene_ocr.png").to(torch.bfloat16) prompt = "<image>Please recognize all text in the image" with torch.no_grad(): response = model.chat(tokenizer, pixel_values=pixel_values, question=prompt, generation_config={"max_new_tokens": 512}, verbose=False) print(response)
使用 vLLM 部署
想高性能?用 Docker:
-
启动服务:
docker run -d --name qianfan-vl --gpus all -v /path/to/Qianfan-VL-8B:/model -p 8000:8000 --ipc=host vllm/vllm-openai:latest --model /model --served-model-name qianfan-vl --trust-remote-code --hf-overrides '{"architectures":["InternVLChatModel"],"model_type":"internvl_chat"}' -
调用 API:
curl 'http://127.0.0.1:8000/v1/chat/completions' --header 'Content-Type: application/json' --data '{ "model": "qianfan-vl", "messages": [ { "role": "user", "content": [ { "type": "image_url", "image_url": { "url": "https://example.com/image.jpg" } }, { "type": "text", "text": "<image>Please recognize all text in the image" } ] } ] }'
更多?查 Cookbook。常见问题:GPU 不足?用 3B 模型。微调?8B 最佳。
FAQ
基于 AnswerThePublic 风格,预测用户问题:
-
Qianfan-VL 支持哪些语言? 中英为主,多语种文档处理。 -
免费吗? 模型开源下载,但云服务看 Baidu 定价。 -
和 Qwen-VL 比谁更好? Qianfan-VL 在 OCR 和推理上更强,见基准。 -
能处理视频吗? 是,支持帧提取和描述。 -
安全性如何? Baidu 强调企业级对齐,减少幻觉。
结论
Qianfan-VL 不是科幻,而是现实中的多模态助手。它平衡了通用性和专业,凭借创新训练和国产芯片,开启企业 AI 新时代。读到这里,你是不是跃跃欲试?下载试用吧,分享你的故事!如果有疑问,评论区见。AI 的未来,就在我们手中。
