Perch 2.0:生物声学领域的新突破,无需微调即可实现跨物种识别
生物声学作为连接生态保护与人工智能的桥梁,近年来在物种监测、栖息地评估等领域展现出巨大潜力。谷歌DeepMind团队最新发布的Perch 2.0模型,通过引入多物种训练数据和创新的训练策略,在无需复杂微调的情况下实现了跨生物类群的声学识别能力突破。
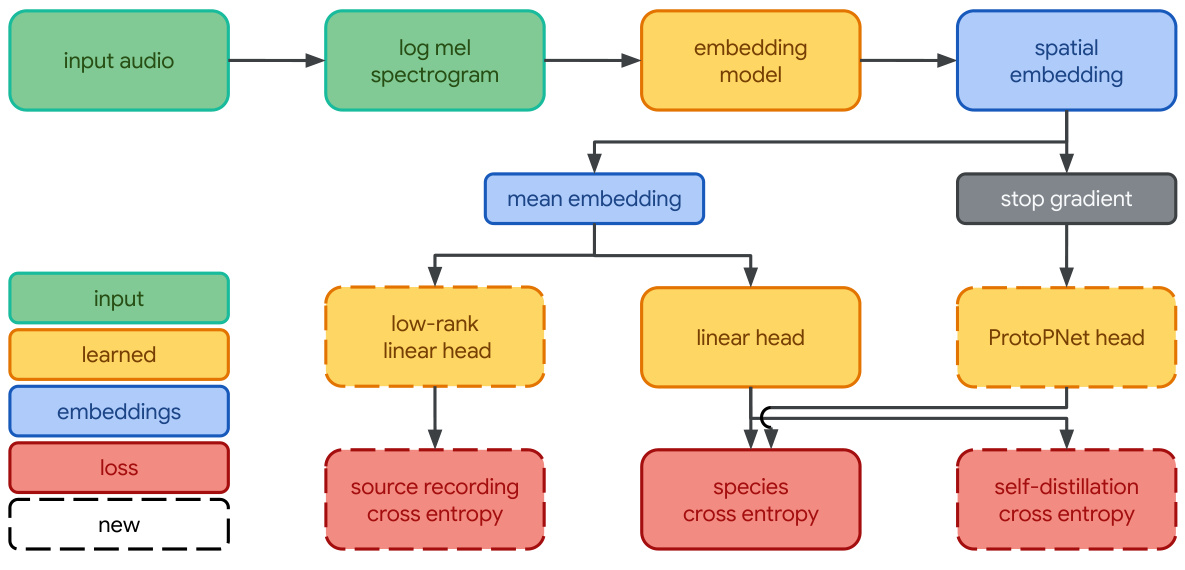
图1:Perch 2.0模型架构采用EfficientNet-B3作为主干网络,通过多任务学习提升特征表达能力
一、什么是Perch 2.0?
Perch 2.0是继2023年Perch 1.0之后的升级版本,主要改进体现在三个方面:
-
训练数据扩展
从仅鸟类数据扩展到包含两栖类、昆虫、哺乳动物及环境声等14,795个分类的训练集(表1),数据量达154万条5秒音频片段。 -
混合监督训练策略
采用**自我蒸馏(Self-Distillation)和源预测(Source Prediction)**双目标优化:-
自我蒸馏:用原型学习分类器作为教师模型,指导线性分类器的软标签学习 -
源预测:要求模型识别每段音频的原始录音来源,增强细粒度特征提取
-
-
高效迁移能力
在BEANS跨物种基准测试中,线性探针(Linear Probing)准确率比Perch 1.0提升3.1%,海洋哺乳动物识别任务AUC达0.977(表2)。
二、为什么选择监督学习?
面对近年来自监督学习(Self-Supervised Learning)的兴起,Perch团队通过实验发现:在生物声学领域,监督学习仍具备不可替代的优势。
2.1 监督学习的核心优势
| 对比维度 | 监督学习 | 自监督学习 |
|---|---|---|
| 所需数据量 | 中等规模(百万级) | 需要海量数据(亿级) |
| 标签粒度要求 | 细粒度标签效果更佳 | 对标签依赖度低 |
| 迁移学习表现 | 跨物种泛化能力强 | 需要大量领域适配微调 |
| 计算资源需求 | 较小(EfficientNet-B3) | 通常需要更大模型 |
表1:监督学习 vs 自监督学习在生物声学中的对比
2.2 生物声学的特殊性
论文指出两个关键观察:
-
细粒度分类即强监督
鸟类物种分类(>10,000类)本身已构成高难度的特征学习任务,模型被迫学习声纹、频谱形态、时序模式等通用生物声学特征。 -
跨类群声学机制相似性
陆生脊椎动物的声带结构具有演化同源性,使得鸟类训练的模型能有效迁移到鲸类、灵长类等声学特征差异较大的物种。

图2:Perch 2.0在6个北美鸟类声景数据集上的ROC-AUC对比(颜色越深性能越好)
三、实际应用表现如何?
3.1 核心基准测试结果
| 基准测试 | 关键指标 | Perch 1.0 | Perch 2.0 (随机窗口) |
|---|---|---|---|
| BirdSet | ROC-AUC | 0.839 | 0.908 |
| BEANS分类任务 | 准确率 | 0.809 | 0.838 |
| BEANS检测任务 | mAP | 0.353 | 0.502 |
表2:Perch 2.0在主要基准测试中的提升幅度
3.2 海洋任务惊喜表现
尽管训练数据中海洋哺乳动物样本极少,Perch 2.0在三个水下声学任务中:
-
DCLDE 2026(鲸类识别)
对座头鲸、虎鲸的AUC达0.977,超过专门训练的Multispecies Whale模型(0.954) -
NOAA PIPAN(鲸类监测)
在包含6种须鲸的复杂场景中AUC达0.924 -
ReefSet(珊瑚礁声景)
准确识别鱼类发声与物理环境声的AUC达0.981
四、常见问题解答(FAQ)
Q1:Perch 2.0需要微调才能使用吗?
不需要。论文强调模型优势在于”固定嵌入(Fixed Embeddings)”——只需将音频输入模型获取1536维特征向量,即可直接用于聚类、相似性搜索等任务,大幅降低部署门槛。
Q2:如何获取模型权重?
目前模型尚未开源,但作者提供代码仓库供研究复现。开发者可通过HuggingFace Transformers库加载预训练模型。
Q3:支持实时处理吗?
模型输入为5秒/段的音频片段,EfficientNet-B3在TPUv3-8上训练,但在消费级GPU(如RTX 3090)上可实现实时处理(<5秒/段)。
Q4:如何处理长录音?
建议将长录音分割为5秒窗口,保留0.5秒重叠。对于整小时录音(约720段),可采用能量峰值检测(附录B算法)筛选关键片段。
五、未来研究方向
-
半监督学习扩展
利用源预测任务特性,通过大量未标注数据增强模型对哺乳类、爬行类等数据稀缺类群的识别能力。 -
动态声学监测
结合卫星追踪数据,建立跨物种声学活动模式数据库,用于生态廊道规划。 -
声学特征可解释性
通过原型学习分类器可视化声纹特征,辅助生物学家发现新的物种声学标记。
六、结语
Perch 2.0的成功印证了生物声学领域一个重要趋势:当监督数据达到百万级规模时,简单的分类任务预训练可能比复杂自监督方法更有效。对生态监测从业者而言,这意味着可以用更低的计算成本构建跨物种声学监测系统。
