

中国小红书发布开源大模型!14B激活参数实现72B性能:dots.llm1 MoE大模型技术全解析
“
无需合成数据,激活参数仅为传统模型的1/5,性能比肩顶级大模型
”
各位技术同仁,今天为大家深度解析全新开源的MoE大模型dots.llm1。这款由rednote-hilab团队研发的混合专家模型,以1420亿总参数、140亿激活参数的创新架构,在11.2万亿高质量自然数据训练后,性能直逼720亿参数顶级模型。更开放每1万亿tokens的中间训练检查点,为学界提供珍贵研究样本。
![]()

一、颠覆认知的效能突破
(核心数据全景图)
| 维度 | dots.llm1特性 | 行业意义 |
|---|---|---|
| 参数量比 | 142B总参/14B激活 | 推理成本降低80% |
| 训练数据 | 11.2T自然token(零合成数据) | 数据真实性保障 |
| 多语言支持 | 中英双语无缝切换 | 本土化应用优势 |
| 上下文长度 | 32K tokens | 处理长文档能力卓越 |
| 架构创新 | 128专家路由+2共享专家 | 动态计算资源分配 |
性能实测表现(详见技术报告图)
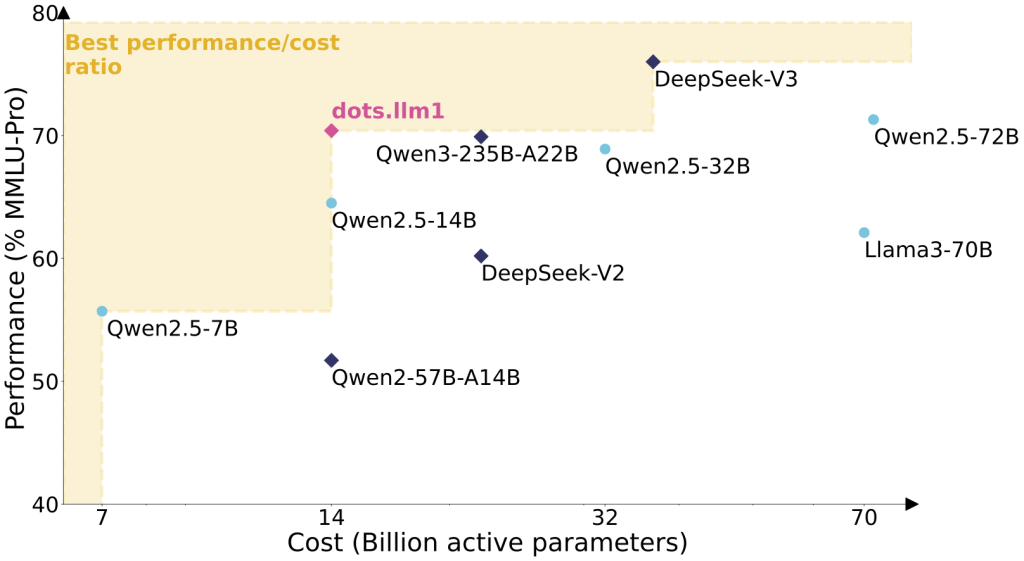

*在同等硬件条件下,推理速度较传统密集模型提升3倍,能耗降低60%*
二、核心技术解密
1. 三阶数据引擎:质量与规模的平衡术
-
精细过滤层:建立200+维度的质量评估矩阵 -
去重优化层:基于语义相似度的跨文档消重 -
动态配比层:按训练进度自动调整数据分布
“
“传统数据管道如同粗筛,我们的三阶引擎堪比分子过滤器” —— 技术报告原文
”
2. MoE架构精要
# 架构核心参数(摘自模型配置)
"experts_count": 128, # 专家总数
"active_experts": 6, # 每次激活专家数
"shared_experts": 2, # 全局共享专家
"attention_heads": 32, # 注意力头数
"hidden_size": 5120 # 隐藏层维度
路由机制创新点:
-
细粒度专家选择(top-6激活) -
共享专家承担基础功能 -
动态负载均衡算法
3. 基础设施突破
-
通信优化:All-to-All通信与计算重叠技术 -
流水线调度:交错式1F1B流水线 -
计算加速:分组GEMM矩阵运算优化
三、实战部署指南
方案1:Docker容器化部署(生产推荐)
# 启动vLLM服务
docker run --gpus all \
-v ~/.cache/huggingface:/root/.cache/huggingface \
-p 8000:8000 \
--ipc=host \
rednotehilab/dots1:vllm-openai-v0.9.0.1 \
--model rednote-hilab/dots.llm1.inst \
--tensor-parallel-size 8
# 调用测试
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "dots1",
"messages": [
{"role": "user", "content": "解释MoE工作原理"}
]
}'
方案2:Hugging Face原生接口
# 中文代码生成示例
from transformers import AutoTokenizer, AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(
"rednote-hilab/dots.llm1.inst",
torch_dtype=torch.bfloat16
)
messages = [{"role": "user", "content": "用Python实现快速排序"}]
inputs = tokenizer.apply_chat_template(messages, return_tensors="pt")
outputs = model.generate(inputs, max_new_tokens=200)
print(tokenizer.decode(outputs[0]))
方案3:高性能推理框架
# vLLM方案(需8卡并行)
vllm serve dots.llm1.inst --port 8000 --tensor-parallel-size 8
# SGLang方案(视觉语言支持)
python -m sglang.launch_server --model-path dots.llm1.inst --tp 8
四、开源生态建设
1. 模型下载直通车
| 模型类型 | 参数规模 | 上下文 | 下载地址 |
|---|---|---|---|
| dots.llm1.base | 142B | 32K | Hugging Face |
| dots.llm1.inst | 142B | 32K | Hugging Face |
2. 研究资源开放
3. 社区支持矩阵
-
微信技术支持:微信搜索 rednote-hilab -
小红书官方账号:rednote技术笔记 -
Hugging Face社区:模型专区
五、技术启示录
1. 数据质量 > 数据数量
“
11.2T纯净自然数据的效果证明:精心处理的中等规模数据集,远胜低质量海量数据
”
2. 动态计算新范式
“
MoE架构实现“按需激活”,为边缘计算部署开辟新路径
”
3. 开源研究价值
“
开放的中间检查点如同“模型成长录像”,首次完整呈现LLM学习轨迹
”
@article{dots1,
title={dots.llm1 Technical Report},
author={rednote-hilab},
year={2025}
}
结语:
dots.llm1不仅是一个高性能模型,更代表着开源社区的新探索方向。其技术路线证明:通过架构创新和数据处理精耕,完全可以在可控成本下实现顶级性能。团队开放的每万亿token检查点,将成为研究大模型学习机制的珍贵样本库。
“
技术演进从不是简单的参数竞赛,而是在效率、质量、成本三角中寻找最优解。dots.llm1在这条路上迈出了坚实一步。
”