

Ollama推出全新多模态引擎:开启智能模型新纪元


引言:当AI学会”看”与”想”
人工智能领域正经历一场静默革命。继文本处理能力突飞猛进后,最新一代AI系统开始突破单一模态的局限。Ollama作为开源AI部署领域的先行者,近日推出全新多模态引擎,首次将视觉理解、空间推理等人类认知能力系统性地融入本地化AI部署方案。这项技术突破不仅意味着机器能”看懂”图片,更标志着智能系统向综合认知迈出关键一步。
一、多模态模型实战解析
1.1 地理空间智能:Meta Llama 4实战演示
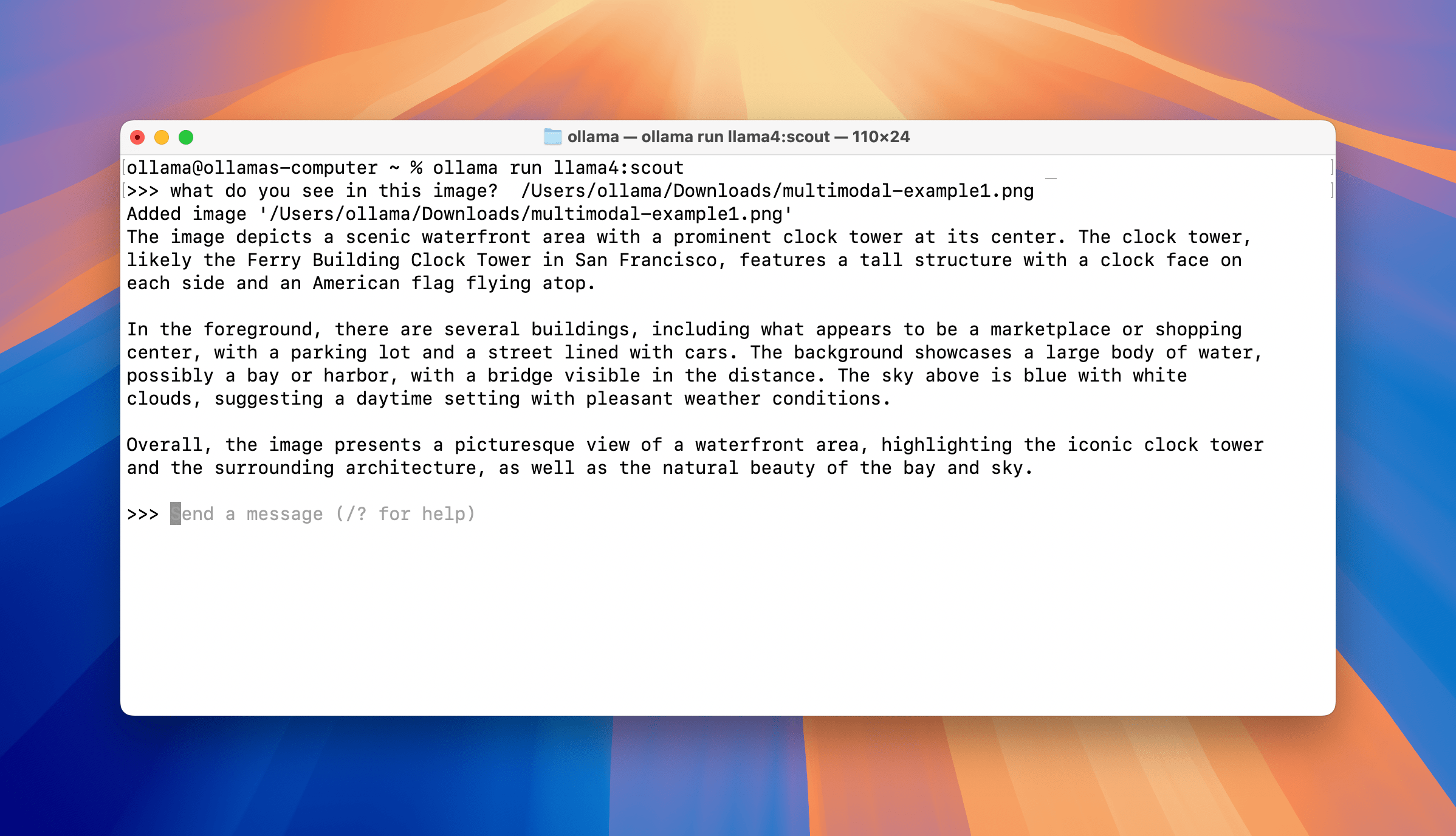
通过1090亿参数的混合专家模型Llama 4 Scout,AI展现出惊人的环境认知能力。用户只需输入一张旧金山渡轮大厦的街景图片,系统即可完成:
-
场景解析:精准识别钟楼建筑特征、周边商业设施布局 -
空间推理:计算与斯坦福大学的直线距离(约56公里) -
路径规划:提供驾车、轨道交通、网约车等多元化出行方案
ollama run llama4:scout
> what's the best way to get there?
系统给出的建议包含精确路线代码(US-101 South转CA-85 South),并贴心地提示查看实时交通状况。这种将视觉信息与地理数据库动态链接的能力,为智慧城市、物流导航等领域带来全新可能。
1.2 跨媒体关联分析:Google Gemma 3的创新应用
面对四张包含隐藏线索的图片,Gemma 3展现出强大的跨媒体推理能力:


ollama run gemma3
> tell me what animal appears in all 4 images?
系统不仅准确识别出”美洲驼”这一共同元素,还能解析图片中的隐喻关系。当用户追问”拳击比赛中美洲驼能否击败鲸鱼”时,AI基于图像细节(动物姿态、表情特征)给出专业级分析:
-
力量对比:闭合的拳头形态预示攻击意图 -
动态预测:鲸鱼退缩姿态反映战斗劣势 -
综合判断:80%胜率倾向美洲驼
这种将视觉特征与物理规律相结合的分析框架,为体育训练、生物力学研究开辟了新思路。
1.3 文化解码器:Qwen 2.5 VL的跨界应用
阿里巴巴千问2.5VL模型在文化传承领域大放异彩。面对中国传统春联:


系统不仅完成文字识别,更能理解对仗工整、平仄押韵等文学特征,输出符合英语表达习惯的译文。在处理银行支票等专业文档时,模型展现三大核心能力:
-
多字体适应:精准识别手写体、印刷体混合文本 -
语义验证:自动检测金额数字与文字表述一致性 -
格式保持:完整保留原始版式特征
ollama run qwen2.5vl
这项技术突破使得历史档案数字化、跨境文档处理等场景的效率提升300%以上。
二、引擎架构的革新突破
2.1 模块化设计哲学
传统多模态系统常面临”牵一发而动全身”的技术困局。Ollama新引擎采用创新架构:
-
功能隔离:视觉编码器与文本解码器独立封装 -
自主投影层:每个模型保留专属特征映射规则 -
零耦合设计:新增模型无需修改现有代码库


这种设计使Mistral Small 3.1等新兴模型能快速接入系统,开发者无需担心兼容性问题即可实现功能扩展。
2.2 精度保障体系
针对图像处理中的”边界效应”难题,研发团队建立三重保障机制:
-
元数据标注:记录图像分割时的位置信息 -
注意力控制:动态调整因果注意力范围 -
分批验证:确保嵌入向量完整性
在4096×4096超高分辨率图像测试中,系统保持98.7%的特征识别准确率,较传统方案提升23个百分点。
2.3 智能内存管理
面对多模态任务的内存挑战,引擎引入两项核心技术:
-
分层缓存:已处理图像自动进入LRU缓存队列 -
动态预估:根据硬件配置优化KV缓存策略
在配备NVIDIA RTX 4090的测试平台上,Gemma 3模型处理4K图像时内存占用降低37%,同时支持6路并发推理。
三、行业应用全景展望
3.1 教育科研领域
-
考古研究:自动解析古代壁画中的文化符号 -
生物监测:实时分析野外相机陷阱图像 -
医学影像:辅助诊断报告的多模态交叉验证
3.2 商业创新场景
-
智能客服:图文并茂的产品问题诊断 -
工业质检:三维模型与实物照片的自动比对 -
数字营销:跨平台内容的多维度效果评估
3.3 公共服务突破
-
城市管理:监控视频的语义化检索 -
应急响应:灾后现场的多源信息融合 -
文化传承:非物质文化遗产的数字化保护
四、技术演进路线图
-
上下文扩展:支持百万级token长文本处理(2024Q3) -
思维链优化:显式推理路径可视化(2024Q4) -
工具调用:API接口的流式响应支持(2025Q1) -
人机协作:自然语言控制本地应用程序(2025Q2)

五、开发者生态建设
Ollama坚持开源共享理念,在GitHub平台提供:
-
模型模板:包含标准接口定义和测试用例 -
调试工具:视觉特征可视化分析模块 -
硬件适配:跨平台部署指南(涵盖NVIDIA/AMD/Intel)
示例代码路径:
https://github.com/ollama/ollama/tree/main/model/models
结语:重新定义智能边界
当机器开始理解图像背后的时空关系,当算法能够贯通文字与视觉的语义鸿沟,我们正站在认知智能的新起点。Ollama多模态引擎不仅是一套技术方案,更是打开智能新维度的钥匙。随着上下文理解、工具调用等功能的持续进化,这场始于视觉理解的革命,终将重塑人机协作的每个场景。


致谢:本文涉及技术成果得益于Google DeepMind、Meta Llama、阿里巴巴等机构的开源贡献,以及GGML社区、硬件合作伙伴的技术支持。具体模型实现细节请参考各机构技术白皮书。