MIT革命性方法让AI规划能力提升64倍,准确率高达94%!
用逻辑思维链和外部验证,MIT研究人员教会了语言模型如何一步步严谨思考。
一直以来,大语言模型(LLM)在生成多步计划方面表现糟糕——它们经常写出看起来合理但根本经不起推敲的方案。如今,MIT CSAIL 的研究人员提出了一个名为 PDDL-INSTRUCT 的新框架,彻底改变了这一现状。
通过将逻辑思维链(Logical Chain-of-Thought) 与外部自动验证器(VAL) 相结合,他们成功让一个仅拥有80亿参数的模型(Llama-3-8B)在经典规划问题Blocksworld上实现了94%的有效规划率,在更复杂的Mystery Blocksworld上甚至实现了64倍的性能提升。
大纲
-
为什么AI不擅长做规划?
-
当前LLM在规划任务中的常见失败模式 -
“听起来合理”与“逻辑正确”之间的差距
-
-
PDDL与符号规划:机器如何理解“行动”与“状态”
-
什么是PDDL?——规划问题的“通用语言” -
行动的前提条件、添加效果与删除效果
-
-
MIT的解决方案:PDDL-INSTRUCT 框架详解
-
两大阶段:初始指令调优 + 思维链指令调优 -
逻辑思维链:让模型一步步推理状态变化 -
外部验证器(VAL):充当“严厉的老师” -
两种反馈:二进制反馈 vs. 详细反馈
-
-
结果令人震撼:准确率大幅提升,泛化能力强劲
-
Blocksworld: 94% 有效规划 -
Mystery Blocksworld: 从近零基线提升64倍 -
Logistics: 稳定显著提升
-
-
深远影响:更可靠的自主智能体与AI未来
-
在机器人、自动驾驶、医疗等关键领域的应用潜力 -
神经符号AI的高效结合:LLM的创造力 + 符号逻辑的可靠性
-
-
局限与未来方向
-
当前依赖外部验证器 -
如何扩展到更复杂的规划问题?
-
-
FAQ:关于PDDL-INSTRUCT,你想知道的都在这
1 为什么AI不擅长做规划?
如果你让ChatGPT之类的模型为你制定一个“用积木搭塔”的计划,它通常能给出一个语法正确、步骤清晰的方案。但如果你仔细检查每一步的前提条件——比如机械臂是否已经抓取了正确的积木,或者目标位置是否为空——你经常会发现这些计划根本无法执行。
这就是当前LLM在规划任务中的核心问题:它们擅长模仿和生成文本模式,但缺乏深层的、基于规则的逻辑推理能力。它们写出的计划是“看似合理(plausible-sounding)”的,而不是“可证明有效(provably valid)”的。
2 PDDL与符号规划:机器如何理解“行动”与“状态”
为了让机器进行自动化规划,研究人员开发了一种名为 PDDL(Planning Domain Definition Language) 的标准语言。你可以把它理解为给AI用来描述世界和行动的一套格式化语法。
在PDDL中,每个动作(Action) 都明确定义了三大要素:
-
前提条件(Preconditions):执行该动作前必须为真的条件。例如,要执行“拿起积木A”的动作,前提条件是“积木A必须在桌上”且“机械臂是空的”。 -
添加效果(Add Effects):执行该动作后变为真的事实。例如,“拿起积木A”后,“机械臂拿着积木A”为真。 -
删除效果(Delete Effects):执行该动作后变为假的事实。例如,“拿起积木A”后,“积木A在桌上”和“积木A顶部是空的”不再为真。
一个规划问题就由一个初始状态和一个目标状态组成,求解器的任务就是找出一系列动作,能够将世界从初始状态逐步转变到目标状态。
3 MIT的解决方案:PDDL-INSTRUCT 框架详解
MIT团队没有试图重新发明轮子,而是选择教会现有的LLM如何更好地使用PDDL这套“语言”进行思考。他们的PDDL-INSTRUCT框架包含两个核心阶段和一个关键外部工具。
阶段一:初始指令调优(Initial Instruction Tuning)
在这个阶段,研究人员对预训练好的LLM(如Llama-3-8B)进行基础教学。他们不仅给模型看正确的计划,还会特意展示错误的计划,并详细解释每一个错误:
-
动作的前提条件未满足 -
效果应用错误 -
违反状态恒常性(Frame Axiom) -
计划未能达到目标
通过这种对比学习,模型初步建立了什么是有效计划、什么是无效计划的概念。
阶段二:思维链指令调优(CoT Instruction Tuning)
这是整个框架的创新核心。在此阶段,模型被要求逐步生成其推理过程,格式为明确的状态-动作-状态序列:⟨s₀, a₁, s₁⟩, ⟨s₁, a₂, s₂⟩, ..., ⟨sₙ₋₁, aₙ, sₙ⟩。
关键一步:生成的每一个推理步骤都会立刻被送入外部验证器VAL进行检查。VAL是一个经典的、可靠的规划验证工具,它能精确地判断一个动作在给定状态下是否可行。
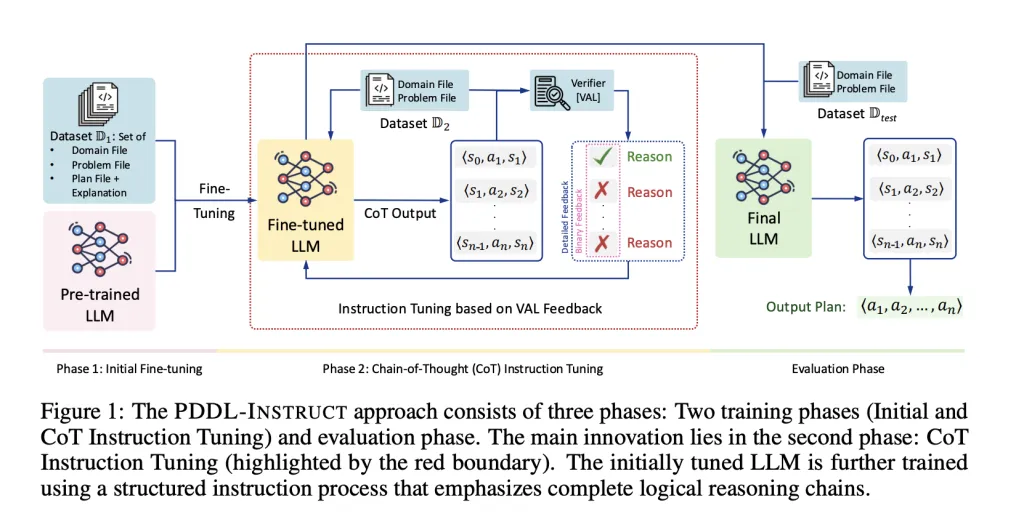
PDDL-INSTRUCT 框架流程示意图(图片来源:原论文)
研究人员试验了两种反馈类型:
-
二进制反馈(Binary Feedback):只告诉模型“对”或“错”。 -
详细反馈(Detailed Feedback):明确指出错误类型和具体原因(例如:“ precondition (holding A)was not satisfied”)。
实验结果清晰表明,提供详细反馈的效果远好于简单的二进制反馈,因为它让模型更清晰地认识到自己具体错在哪里,从而学习得更快、更扎实。
两阶段优化:打磨推理,再优化结果
在第二阶段内部,还有一个精巧的两阶段优化过程:
-
阶段2.1:推理链优化:专注于优化模型生成逻辑连贯、逐步推理的能力。损失函数会惩罚那些前提条件不满足、效果应用错误或违反约束的步骤。 -
阶段2.2:最终性能优化:在拥有了良好的推理能力基础上,进一步微调模型,确保其最终生成的整个计划是高度准确的。
这种分工确保了模型既懂得如何正确思考,又能产出高质量的实际解决方案。
4 结果令人震撼:准确率大幅提升,泛化能力强劲
团队在PlanBench基准上进行了严格测试,涵盖了三个经典规划领域:
| 领域 | 描述 | 挑战点 |
|---|---|---|
| Blocksworld | 积木堆叠 | 基础推理,相对简单 |
| Mystery Blocksworld | 积木世界变体 | 谓词名称被混淆,无法依赖模式匹配 |
| Logistics | 物流运输 | 多步运输,复杂连接关系 |
结果如下表所示,PDDL-INSTRUCT带来了巨大的性能飞跃:
| 模型 | 领域 | 基线 | 仅阶段一 | PDDL-INSTRUCT (详细反馈) |
|---|---|---|---|---|
| Llama-3-8B | Blocksworld | 28% | 78% | 94% |
| Mystery Blocksworld | 1% | 32% | 64% (↑64x) | |
| Logistics | 11% | 23% | 79% | |
| GPT-4 | Blocksworld | 35% | 41% | 91% |
| Mystery Blocksworld | 3% | 17% | 59% | |
| Logistics | 6% | 27% | 78% |
数据来源:论文中Table 1,为100个测试任务上的计划准确率(%)
最令人印象深刻的是在Mystery Blocksworld上的表现。由于谓词名称被替换(例如“on”可能被叫成“foobar”),模型无法依靠记忆或表面模式匹配来作弊,必须真正理解动作的逻辑语义。PDDL-INSTRUCT将模型从近乎零的成功率(1%)提升到了可用的64%,这充分证明了其强大的泛化和深层推理能力。
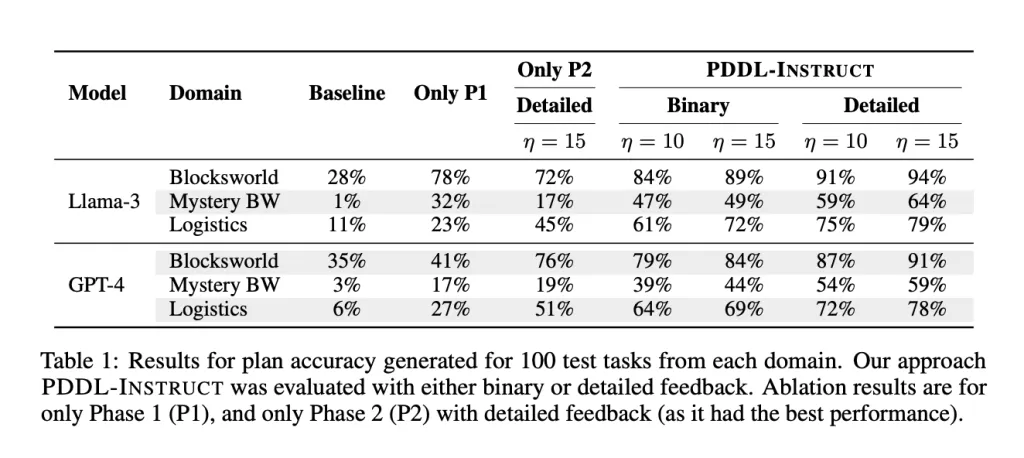
在PlanBench基准上的性能对比(图片来源:原论文)
5 深远影响:更可靠的自主智能体与AI未来
这项工作的意义远不止于让机器人在虚拟世界里堆积木。它为构建真正可靠、可信赖的AI智能体铺平了道路。
-
机器人:家庭服务机器人能够制定出可靠的多步任务计划,如准备餐食、整理房间。 -
自动驾驶:车辆可以规划出更安全、考虑周全的变道或超车序列。 -
医疗流程:AI助手可以帮助规划复杂的治疗或手术流程,并确保步骤的逻辑一致性。 -
工业自动化:优化仓库物流、生产线调度等复杂流程。
更重要的是,它展示了一条神经符号AI(Neuro-Symbolic AI) 的可行路径:利用LLM的生成能力和灵活性,同时用符号系统的严谨逻辑来约束和验证它,从而结合了二者的优势。
6 局限与未来方向
当然,PDDL-INSTRUCT并非万能。研究者们也坦诚地指出了其当前局限和未来的发展方向:
-
依赖外部验证器(VAL):目前仍需VAL这个“外部老师”来提供反馈。未来的目标是让LLM最终学会自我验证(Self-Verification),减少对外部工具的依赖。 -
经典的PDDL领域:当前工作局限于使用STRIPS表述的经典规划问题,不支持条件效果、数值运算或时间约束。扩展到更复杂的规划领域是下一步。 -
满意解而非最优解:目前框架只关心生成一个能用的计划(satisficing plan),而不一定是步骤最少的最优计划(optimal plan)。追求最优性是下一个挑战。 -
计算成本:两阶段训练和多次VAL验证迭代需要可观的算力资源。
7 FAQ:关于PDDL-INSTRUCT,你想知道的都在这
Q1: PDDL-INSTRUCT 是如何工作的?
它通过两个阶段训练LLM:1. 初始指令调优:用正例和反例教模型识别有效和无效的计划。2. 思维链指令调优:要求模型生成一步步的推理状态链(s, a, s’),并用外部验证器VAL检查每一步,将错误反馈给模型以学习改进。
Q2: 为什么需要外部验证器(VAL)?LLM不能自己检查吗?
研究表明,目前的LLM自我修正推理的能力非常有限。它们常常无法发现自身推理中的逻辑错误,甚至会产生“自圆其说”的错误解释。VAL作为一个基于形式化逻辑的、确定性的验证器,可以提供100%可靠的 ground-truth 反馈,这是可靠学习的基础。
Q3: 这个方法只适用于特定的模型吗?
不。论文在Llama-3-8B和GPT-4上都进行了实验,都观察到了显著的性能提升。这表明PDDL-INSTRUCT框架是模型无关的(model-agnostic),其核心思想可以应用于不同的LLM。
Q4: “详细反馈”比“二进制反馈”好在哪里?
二进制反馈只告诉模型“对”或“错”,而详细反馈会指明错误的具体类型和内容,例如“第3步的 precondition (clear B) 未满足”。这就像学生做题时,只知道叉叉和知道错在哪里、为什么错,后者显然更能帮助学生进步。
Q5: 这个技术现在能用了吗?
论文提供了完整的方法论、损失函数和超参数配置(见表2),理论上其他研究者或开发者可以复现。然而,由于其训练过程需要大量的PDDL规划示例和VAL验证基础设施,直接应用仍有一定的技术门槛。它目前更像一个强大的研究原型,指明了未来发展的方向。
论文地址: https://arxiv.org/abs/2509.13351
MIT的这项工作深刻地告诉我们,通过精巧的设计和神经与符号方法的结合,我们完全可以引导大语言模型走向更严谨、更可靠的推理之路。这不仅是AI规划领域的突破,更是迈向能真正理解世界、并可靠地在其中行动的智能体的一大步。
