

想象一下,你在开发一个电商应用,用户可能用西班牙语搜索产品,但产品描述全是英文。如何让系统快速、准确地找到匹配项,而不牺牲速度?这就是LFM2-ColBERT-350M这类模型的价值所在。它是一个基于晚期交互的检索器,专为多语言和跨语言场景设计,能让你用一个模型处理多种语言的查询和文档。今天,我们来一步步拆解这个模型:它是怎么工作的,为什么适合实际应用,以及如何上手使用。我会用简单的话解释技术点,同时分享一些实际测试数据和代码示例,帮助你快速评估是否适合你的项目。
晚期交互检索器是什么,为什么值得一试?
如果你已经在用检索增强生成(RAG)系统,你可能遇到过两种常见选择:双编码器(bi-encoders)或重排序器(rerankers)。双编码器速度快,能独立处理查询和文档,但容易忽略查询和文档之间细粒度的词级互动,比如精确的术语匹配。重排序器则通过联合编码捕捉这些互动,准确率高,但计算成本太重,不适合大规模检索。
晚期交互检索器像是一个折中方案。它先独立编码查询和文档的每个token(词元),然后在查询时通过MaxSim这样的函数比较这些token向量,并聚合分数。这样,你既保留了重排序器的表达力,又保持了双编码器的效率——文档可以预先编码存储,查询时只需快速计算互动。
LFM2-ColBERT-350M就是这样一个晚期交互模型。它基于高效的LFM2骨干网络,参数规模在350M左右,却能在多语言环境下表现出色。简单说,它能让你用英语索引文档,然后用德语或法语查询,准确率依然很高。这对全球应用特别实用,比如企业知识库或移动设备上的语义搜索。
你可能会问:为什么不直接用更大的模型?答案在于平衡。LFM2-ColBERT-350M的推理速度和比它小2.3倍的模型相当,这得益于LFM2的架构:它结合了短程输入感知门控卷积和分组查询注意力,让计算更高效。

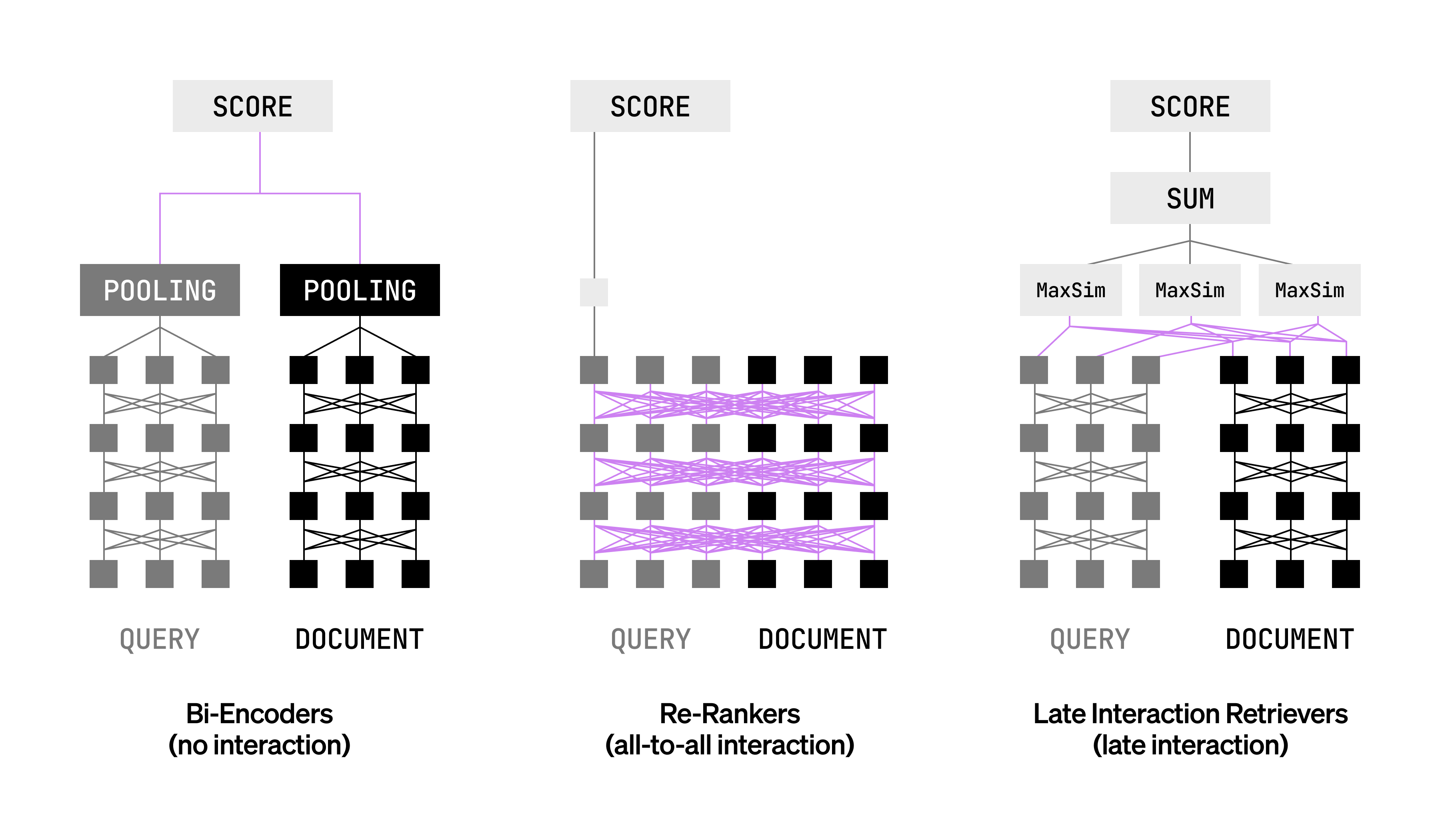
上图展示了晚期交互的核心:token级独立编码 + 查询时互动聚合。它不是科幻,而是能直接集成到你的RAG管道中,提升检索质量。
LFM2-ColBERT-350M的核心规格和适用场景
这个模型不是一个黑盒子。让我们看看它的关键参数,这样你能快速判断是否匹配你的需求。
| 属性 | 详情 |
|---|---|
| 总参数量 | 353,322,752 |
| 层数 | 25层(18个卷积块 + 6个注意力块 + 1个稠密层) |
| 上下文长度 | 32,768 token |
| 词汇表大小 | 65,536 |
| 训练精度 | BF16 |
| 文档长度 | 512 token |
| 查询长度 | 32 token |
| 输出维度 | 128 |
| 相似度函数 | MaxSim |
| 支持语言 | 英语、阿拉伯语、中文、法语、德语、日语、韩语、西班牙语 |
| 许可协议 | LFM Open License v1.0 |
这些规格让它适合边缘设备部署,比如手机上的语义搜索:用户用自然语言问“找找我的旅行笔记”,系统就能检索相关文件。
适用场景包括:
- •
电商搜索:英语产品描述 + 多语言查询。 - •
企业助手:跨语言检索法律或技术文档。 - •
移动应用:设备本地搜索邮件或笔记。
模型架构是一个ColBERT变体:Transformer(基于LFM2)后接一个稠密层,将特征从1024维降到128维。代码上,它像这样定义:
ColBERT(
(0): Transformer({'max_seq_length': 511, 'do_lower_case': False}) with Transformer model: Lfm2Model
(1): Dense({'in_features': 1024, 'out_features': 128, 'bias': False, 'activation_function': 'torch.nn.modules.linear.Identity'})
)
如果你在构建RAG管道,这能作为即插即用组件,提升从粗检索到细排名的整体流程。
如何评估它的多语言性能?
性能是模型的硬通货。我们来看看在NanoBEIR基准上的表现。这个基准扩展了原版,新增了日语和韩语数据集(开源在Hugging Face的LiquidAI/nanobeir-multilingual-extended),确保可复现。
LFM2-ColBERT-350M在单语言(文档和查询同一种语言)上表现出色,尤其在德语、阿拉伯语、韩语和日语上领先基线模型GTE-ModernColBERT-v1(150M参数)。英语性能保持稳定,没有牺牲。
更亮眼的是跨语言能力:用一种语言索引文档,用另一种查询。以下是NDCG@10分数表(越高越好,代表前10个检索结果的相关性):
| 文档语言 / 查询语言 | AR | DE | EN | ES | FR | IT | JA | KO | PT |
|---|---|---|---|---|---|---|---|---|---|
| AR | 0.490 | 0.288 | 0.339 | 0.303 | 0.304 | 0.286 | 0.357 | 0.338 | 0.291 |
| DE | 0.383 | 0.563 | 0.547 | 0.498 | 0.502 | 0.489 | 0.424 | 0.368 | 0.486 |
| EN | 0.416 | 0.554 | 0.661 | 0.553 | 0.551 | 0.522 | 0.477 | 0.395 | 0.535 |
| ES | 0.412 | 0.514 | 0.578 | 0.563 | 0.547 | 0.529 | 0.436 | 0.394 | 0.547 |
| FR | 0.408 | 0.527 | 0.573 | 0.552 | 0.564 | 0.537 | 0.450 | 0.388 | 0.549 |
| IT | 0.395 | 0.512 | 0.554 | 0.535 | 0.535 | 0.543 | 0.439 | 0.386 | 0.529 |
| JA | 0.375 | 0.365 | 0.409 | 0.358 | 0.345 | 0.337 | 0.557 | 0.491 | 0.330 |
| KO | 0.326 | 0.274 | 0.310 | 0.282 | 0.265 | 0.266 | 0.440 | 0.527 | 0.271 |
| PT | 0.402 | 0.499 | 0.558 | 0.545 | 0.528 | 0.529 | 0.436 | 0.382 | 0.547 |
平均来看,英语-其他语言对的分数在40-50%区间,远高于基线。相比之下,GTE-ModernColBERT-v1在跨语言上的分数明显低,比如英语文档+阿拉伯语查询只有0.042。

.png)
这个图直观显示了LFM2-ColBERT-350M在多语言上的优势:它不是简单堆参数,而是针对跨语言优化,让你用单一模型取代多模型架构。
你可能好奇:这些分数怎么算的?NDCG@10衡量的是检索列表的相关性排序,1.0是完美匹配。实际中,这意味着你的用户查询“un libro sobre historia”能高效拉出英语的“a book on history”文档。
推理速度:为什么它感觉像个小模型?
参数多不等于慢。LFM2-ColBERT-350M的查询编码用MS MARCO和Natural Questions数据集的真实查询测试,文档编码则覆盖不同长度和领域的文档。结果显示,它的吞吐量和GTE-ModernColBERT-v1相当,尽管参数是后者的2.3倍。
.png)
.png)
从图中可见,在不同批次大小下,速度曲线几乎重合。这让它适合实时应用,比如聊天机器人中的即时检索。背后的原因是LFM2骨干:卷积处理局部模式,注意力聚焦全局,减少了无谓计算。
如果你在部署时担心硬件,测试显示它在标准GPU上运行顺畅,不需要高端配置。
如何上手:从安装到检索的完整指南
现在,来点实际的。LFM2-ColBERT-350M支持Hugging Face集成,通过PyLate库实现索引和检索。别担心,我会一步步走你通过。
安装依赖
先安装核心库:
pip install -U pylate
这会拉取PyLate和transformers,确保环境兼容Python 3.x。
索引文档:预处理你的数据
索引是晚期交互的关键——一次性编码文档,多次查询。假设你有几份文档:
-
加载模型:
from pylate import indexes, models, retrieve # 加载ColBERT模型 model = models.ColBERT( model_name_or_path="LiquidAI/LFM2-ColBERT-350M", ) model.tokenizer.pad_token = model.tokenizer.eos_token -
初始化索引(用FastPLAID高效存储):
index = indexes.PLAID( index_folder="pylate-index", index_name="index", override=True, # 覆盖现有索引,便于测试 ) -
编码文档:
documents_ids = ["1", "2", "3"] documents = ["document 1 text", "document 2 text", "document 3 text"] documents_embeddings = model.encode( documents, batch_size=32, is_query=False, # 标记为文档 show_progress_bar=True, ) -
添加至索引:
index.add_documents( documents_ids=documents_ids, documents_embeddings=documents_embeddings, )
提示:索引后,你可以保存它,下次直接加载:
index = indexes.PLAID(
index_folder="pylate-index",
index_name="index",
)
这步在生产中只需跑一次,节省时间。
检索查询:获取トップ匹配
现在,处理用户查询:
-
初始化检索器:
retriever = retrieve.ColBERT(index=index) -
编码查询:
queries_embeddings = model.encode( ["query for document 3", "query for document 1"], batch_size=32, is_query=True, # 标记为查询 show_progress_bar=True, ) -
检索トップk:
scores = retriever.retrieve( queries_embeddings=queries_embeddings, k=10, # 前10个结果 )
scores会返回每个查询的匹配ID和分数。你可以用它构建响应,比如在RAG中喂给生成模型。
重排序:如果不需要全索引
有时,你只想在粗检索后重排候选文档。用rank模块:
from pylate import rank, models
queries = ["query A", "query B"]
documents = [["document A", "document B"], ["document 1", "document C", "document B"]]
documents_ids = [[1, 2], [1, 3, 2]]
model = models.ColBERT(model_name_or_path="LiquidAI/LFM2-ColBERT-350M")
queries_embeddings = model.encode(queries, is_query=True)
documents_embeddings = model.encode(documents, is_query=False)
reranked_documents = rank.rerank(
documents_ids=documents_ids,
queries_embeddings=queries_embeddings,
documents_embeddings=documents_embeddings,
)
这适合混合管道:先用双编码器粗筛,再用LFM2-ColBERT-350M精排。
完整Colab示例:这里。运行它,你能在几分钟内看到跨语言检索的效果。
常见问题解答(FAQ)
你可能还有些疑问,让我们直接聊聊。
什么是晚期交互检索器,它和ColBERT有什么关系?
晚期交互是一种架构,让模型在token级别编码查询和文档,然后延迟到查询时计算互动。LFM2-ColBERT-350M是ColBERT的变体,用LFM2作为骨干,专注于多语言。
这个模型支持哪些语言,为什么跨语言这么强?
它原生支持英语、阿拉伯语、中文、法语、德语、日语、韩语和西班牙语。评估还包括意大利语和葡萄牙语。跨语言强是因为训练捕捉了语言间相似性,比如英语和罗曼语系的共享模式。
我需要多少计算资源来运行它?
推理速度和150M模型相当,所以标准GPU(如RTX 3060)够用。批次大小32时,查询编码每秒处理数百个。
如何测试跨语言性能?
用NanoBEIR扩展数据集:下载后,跑评估脚本,比较NDCG分数。文档:Hugging Face数据集。
它能集成到现有RAG中吗?
是的,作为drop-in替换。编码文档时设is_query=False,查询时设True,然后用MaxSim聚合。
许可和引用怎么处理?
用LFM Open License v1.0。引用PyLate库时:
@misc{PyLate,
title={PyLate: Flexible Training and Retrieval for Late Interaction Models},
author={Chaffin, Antoine and Sourty, Raphaël},
url={https://github.com/lightonai/pylate},
year={2024}
}
实际洞见:从测试到部署的思考
用LFM2-ColBERT-350M时,我建议从小规模开始:先索引100个文档,跑几组跨语言查询,看分数是否达标。记住,MaxSim函数对token匹配敏感,所以文档预处理(如分句)很重要。
在多语言RAG中,它能减少模型切换的复杂性——一个模型管检索和重排,维护起来简单。速度优势让它适合低延迟场景,比如实时客服。
如果你在构建全球应用,不妨试试这个模型。它不是万能药,但数据证明,它在平衡准确和效率上做了不错的工作。感兴趣?直接去Hugging Face的互动demo上手玩玩。

