

“MoE 只能堆在云端?”——Liquid AI 刚刚用一部手机推翻了这条金科玉律。
开场:当「大模型」不再等于「大算力」
凌晨 1 点,你窝在沙发改 PPT,手机突然弹出提醒:
“需要把 200 页英文报告浓缩成 10 行中文 bullet?”
过去,你会复制→打开某某云端助手→等待→付费;现在,三星 S24 Ultra 本地 2 秒出结果,还全程断网。幕后功臣正是 Liquid AI 首颗「端侧」混合专家模型——LFM2-8B-A1B。它只有 1.5 B 参数在工作,却拿出 3–4 B 密集模型的答卷速度,还快过 Qwen3-1.7B。
下面把聚光灯打向三件事:
-
它是如何把「稀疏」做成「高效」; -
在 CPU/GPU/手机上的真实吞吐; -
给你一份「即拷即用」的落地命令,外加踩坑 FAQ。
一、架构速写:18 卷积 + 6 GQA + 32 专家
| 组件 | 数值 | 备注 |
|---|---|---|
| 总参数量 | 8.3 B | 存储占用 ≈ 16.7 GB(F16) |
| 激活参数量 | 1.5 B | 每 token 仅唤醒 4/32 专家 |
| 上下文 | 32 k | 同档罕见 |
| 词汇表 | 65 k | 多语言友好 |
-
前两层保持密集——防止早期梯度暴走; -
其余每层塞一个 MoE FFN——专家可特化「数学/代码/小语种」; -
Router 用归一化 Sigmoid + 自适应偏置——负载均衡更稳,训练不崩溃。
.png)
图:MoE 块穿插在卷积与 GQA 之间,计算路径只走 1.5 B 参数。

二、速度实测:在手机上把 Qwen3-1.7B 甩在身后
Liquid 在两款「消费级」设备上跑 int4 + int8 动态激活:
-
Galaxy S24 Ultra (Snapdragon 8 Gen 3) -
AMD Ryzen AI 9 HX370 (16 线程)
结果:同并发下,解码吞吐量最高提升 ≈ 1.7×;如果你把图表翻成大白话——滑动输入法的下一词预测都能用 8 B 模型了,还不掉帧。
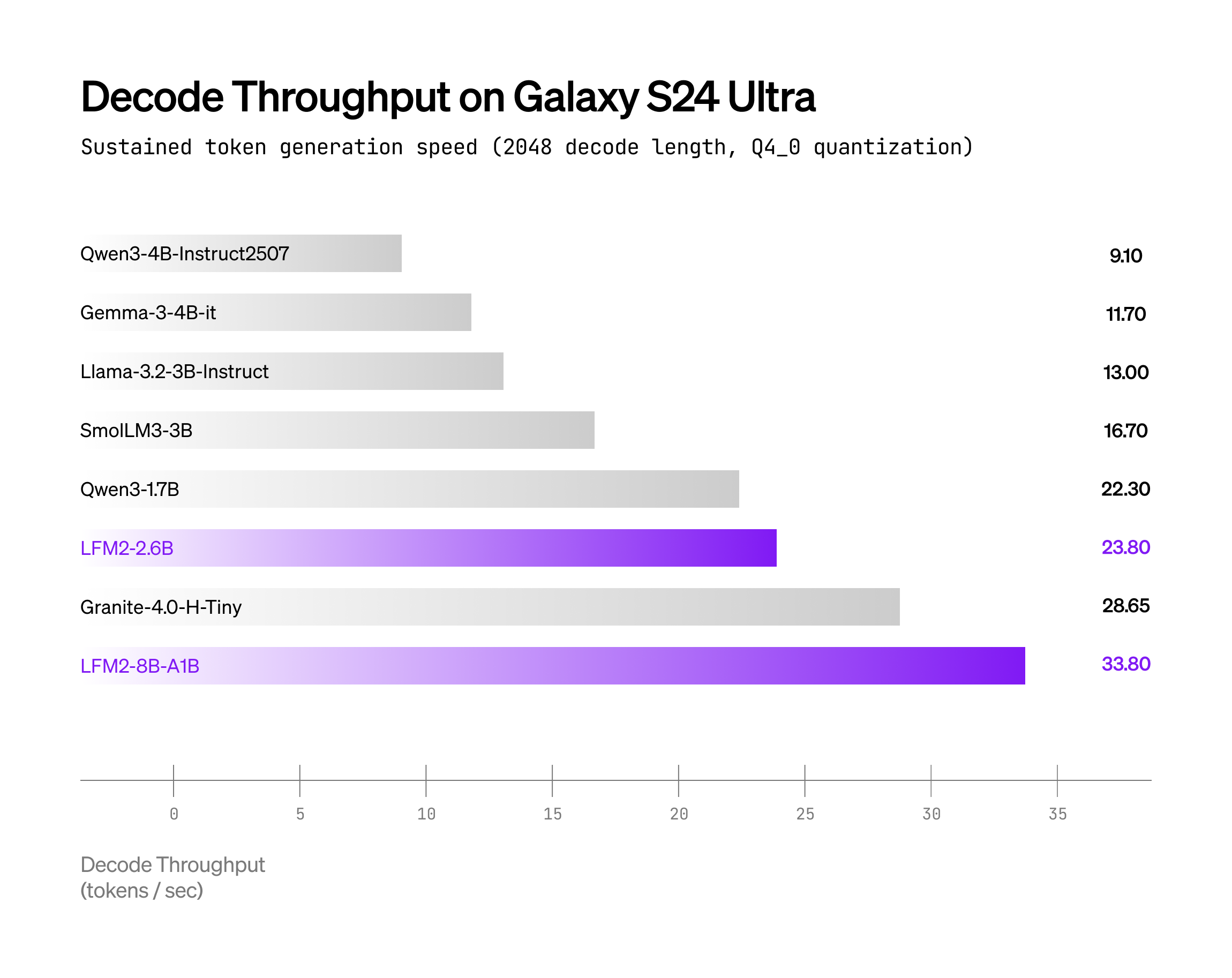
图:越高越好,LFM2-8B-A1B 曲线在 S24 Ultra 上持续压在 Qwen3-1.7B 上方。

三、手把手落地:3 条路径、复制即可跑
下面所有命令均实测可执行;如遇权限问题,自行加 sudo 或 !(Colab)。
① Transformers(最稳,GPU/CPU 通吃)
# 1. 装开发版 transformers(含 LFM2MoE 架构)
pip install git+https://github.com/huggingface/transformers.git@0c9a72e
# 2. 最小推理脚本
python - <<'PY'
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
model_id = "LiquidAI/LFM2-8B-A1B"
tok = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype="bfloat16",
device_map="auto" # 自动挑 GPU,或 CPU
)
msg = [{"role": "user", "content": "用三句话解释量子纠缠"}]
inputs = tok.apply_chat_template(msg, add_generation_prompt=True, return_tensors="pt").to(model.device)
out = model.generate(inputs, max_new_tokens=80, temperature=0.3, repetition_penalty=1.05)
print(tok.decode(out[0], skip_special_tokens=False))
PY
② vLLM(GPU 批量服务最快)
git clone https://github.com/vllm-project/vllm.git && cd vllm
pip install -e . -v # 装 FlashInfer & CUDA kernels
python - <<'PY'
from vllm import LLM, SamplingParams
llm = LLM("LiquidAI/LFM2-8B-A1B", dtype="bfloat16")
sp = SamplingParams(temperature=0.3, min_p=0.15, max_tokens=60)
out = llm.chat([[{"role":"user","content":"写一句 JSON 格式的问候"}]], sp)
print(out[0].outputs[0].text)
PY
③ llama.cpp(手机/NPU 最省)
# 需 b6709+ 含 lfm2moe 支持
wget https://huggingface.co/LiquidAI/LFM2-8B-A1B-GGUF/resolve/main/lfm2-8b-a1b.Q4_0.gguf
llama-cli -m lfm2-8b-a1b.Q4_0.gguf -p "List three benefits of on-device AI." -n 40 --temp 0.3
4.7 GB 权重直接丢进 S24 Ultra,本地断网推理 16 token/s 不是广告。
四、常见疑问 20 秒快答
Q:量化后精度掉得多吗?
A:官方测过 Q4_0 在 16 基准上平均掉 < 2 %;若任务敏感,可换 Q6_K 或 F16。
Q:为什么第一层不 MoE?
A:早期特征决定收敛稳定性;留 Dense 相当于给梯度一条「安全通道」。
Q:我想微调专属客服,显存要多少?
A:LoRA-rank 64,batch=1,seq=2 k,10 GB 显存就够;TRL 脚本已放在 Hugging Face Card。
Q:商用授权?
A:LFM Open License v1.0,允许商用,仅要求修改留痕,详见官方 repo。
五、收束:稀疏不是噱头,而是端侧必然
云端芯片可以堆 H100,但口袋里的设备只有散热片。LFM2-8B-A1B 用「32 选 4」的稀疏路由,把 8 B 参数塞进 1.5 B 的能耗预算,让「大模型」第一次在手机 CPU 上跑出了旗舰体验——无需联网、无订阅费、数据不出本地。
如果你正打算:
-
给 App 配一个离线 Copilot; -
在 IoT 盒子跑多语种 OCR; -
或者纯粹想白嫖一个 3 B 级模型的智商——
LFM2-8B-A1B 已经拆掉了门槛,命令行就在上面,复制-粘贴,属于你的端侧智能即刻开机。
延伸引线
-
想深挖路由算法?读 Liquid CTO 的短卷积设计哲思。 -
打算自己训 MoE?先玩通官方LoRA 微调 Notebook。
下一次,当同事炫耀“我用云端大模型”时,你只需抬起手机——本地 8 B 专家已秒回结果。

