

探索生成模型的强大之道:从自回归到扩散,再到更进一步
你有没有想过,为什么像GPT这样的语言模型总是在一步步“预测下一个词”?这听起来简单,却支撑了从聊天机器人到代码生成的整个AI世界。但当我们面对更棘手的任务,比如解数独谜题或生成符合生物约束的分子结构时,这种一步一个脚印的方式是不是有点力不从心?最近的一篇论文《On Powerful Ways to Generate: Autoregression, Diffusion, and Beyond》让我眼前一亮,它不只是聊技术细节,而是从生成过程本身入手,比较了不同方法的长处和短板,还提出了一个新想法:Any-Process Generation(简称APG)。作为一名对AI生成技术感兴趣的工程师,我读完后觉得,这不光是理论,还能直接应用到实际项目中。今天,我就来聊聊这些内容,用大白话解释清楚,顺便分享怎么上手代码实现。咱们一步步来,确保你读完能自己试试。
生成模型的基础:为什么顺序这么重要?
先从头说起。你可能好奇:生成模型到底是怎么工作的?简单讲,它就是AI从零开始“创造”序列的过程,比如一段文字、一段代码或一个图结构。传统上,大多数模型用自回归模型(Autoregressive Models, ARM),灵感来自人类说话:一个词接一个词,从左到右顺序生成。就像Shannon在1951年提出的信息论基础,ARM通过训练海量数据,学会预测下一个token(基本单位,比如单词或字符)。
ARM的魅力在于简单高效。拿GPT系列来说(从Radford et al. 2018到Achiam et al. 2023),它在自然语言任务上大放异彩,能处理通用任务和推理。但问题来了:现实世界不总是一维的。人类解决问题时,往往不是直线前进,而是试错、修改、回溯。比如写代码,你可能先搭个框架,然后插入函数、删除多余行,甚至重写一段逻辑。这在ARM里很难,因为它生成的token一旦吐出,就没法轻易改了。
论文作者(Chenxiao Yang、Cai Zhou、David Wipf和Zhiyuan Li)就抓住了这个痛点。他们把生成过程抽象出来,不纠结具体架构(如Transformer),而是用计算复杂度和可学习性来衡量。结果呢?ARM虽然强大(甚至图灵完备,能模拟任何可计算函数),但在需要并行处理或编辑的任务上,效率不高。举个例子,在并行随机访问机(PRAM)模型下,ARM的并行时间是线性于序列长度的,而我们需要的东西,往往更灵活。
你要是问:“那有什么替代方案?”答案就是掩码扩散模型(Masked Diffusion Models, MDM)。MDM不像ARM那样顺序生成,而是从一个全掩码的序列开始(想象成一串问号[M]),逐步“揭开”面纱。每个步骤,模型并行预测多个位置的token。这灵感来自Hoogeboom et al. 2021和Austin et al. 2021的工作,最近的扩散LLM(如DeepMind 2025和Nie et al. 2025)甚至比ARM快10倍,还在反序诗补全或数独上表现更好。


上图(来自论文)直观对比了三种生成:ARM是线性推进,MDM是任意顺序揭开,APG则能插入、删除、重掩码。MDM的并行性让它模拟PRAM算法只需O(T(n))步(T(n)是并行时间),上下文长度S(n)正比于总工作量。这意味着,对于NC类问题(如图连通性或上下文无关语言),MDM能指数级加速,而ARM得线性时间磨。
但别高兴太早。论文证明,MDM的“任意顺序”灵活性有限。一旦控制住并行度和架构,MDM的计算能重排成左到右顺序,由一个“掩码ARM”模拟(序列长O(S(n)),加几层额外网络)。简单说,任意顺序生成(Any-Order Generation)本身不比ARM多出新能力。两者都受空间限制:上下文S(n)下,只能高效处理P类问题(多项式时间),NP-hard任务(如大数独)得靠测试时扩展,但空间不够用。
这让我想到:如果你在开发一个代码生成工具,ARM适合流畅叙述,但MDM更适合并行填充变量。问题是,对于需要“后悔”或“扩展”的场景呢?论文的答案是:需要更强的工具。
引入Any-Process Generation:让生成像编辑文档一样自由
现在进入重头戏:Any-Process Masked Diffusion Models (AP-MDM)。作者们灵感来自自然界——基因剪接、蛋白质重组都不是顺序堆砌,而是结构化编辑。他们在标准MDM基础上,加了三个操作:remask(重掩码)、insert(插入)和delete(删除)。这些不是大改架构,只需在Transformer编码器上加三个小线性头,用3位控制向量(ct,i = (ct,i[1], ct,i[2], ct,i[3]))预测每个位置的动作。
-
Unmask:标准操作,揭开掩码填token。 -
Remask:用第一位决定,把已解码token变回[M],支持回溯和自纠错。 -
Insert:第二位控制,在任意位置加新[M],序列能动态增长。 -
Delete:第三位控制,移除[M],序列能收缩。
这摆脱了扩散模型的物理限制(如固定掩码比率、步数、长度),让生成像用Word编辑文档:试错、插入段落、删冗余。理论上,AP-MDM模拟PRAM时,既达最优并行时间,又用S(n)正比真空间(而非总工作)。多项式上下文下,它触及PSPACE(多项式空间),远超ARM和MDM的P类限制。论文甚至证明,常深度AP-MDM的生成过程,在标准复杂度假设下,无法被常深度ARM模拟。


上图展示了AP-MDM怎么用这些操作生成句子:从“the quick brown [M] [M]”开始,插入、删除、重掩码,最终得出自然序列。
为什么这实用?想想代码生成:ARM难保证括号平衡(两侧Dyck-k语言),因为它没法全局检查。论文证明,固定ARM无法生成任意长匹配括号,而AP-MDM用insert和remask就能精确生成Dyck语言——核心代码语法技能。在生物学,生成DNA序列时,insert能模拟重组,remask纠错突变。
理论 vs. 实践:实验结果告诉你谁更牛
论文不光理论,还做了硬核实验,覆盖数独、Dyck语言、图生成和奇偶校验。咱们用表格总结下关键对比(基于1.2M参数AP-MDM vs. 基线):
| 任务 | AP-MDM 准确率 | ARM 准确率 (1.8M 实例, 5x 参数) | AO-MDM 准确率 | 训练数据规模 | 关键洞见 |
|---|---|---|---|---|---|
| 数独 (n² x n²) | 99.28% | 87.18% | 89.49% | AP: 100 实例 | Remask 启用测试时扩展,指数改善NP-hard问题 |
| Dyck-k 语言 | 精确生成任意长 | 无法保证任意长 | N/A | N/A | Insert/remask 处理全局约束,如括号平衡 |
| 图编辑/生成 | ~100% (规模扩展) | 随图大小衰减 | N/A | 10k 实例 | Delete/insert 维持结构完整,ARM 顺序失效 |
| 奇偶校验 | 100% (OOD 泛化) | 挣扎 (长序列) | N/A | 长度2 训练 | Delete 学局部消除规则,泛化任意长 |
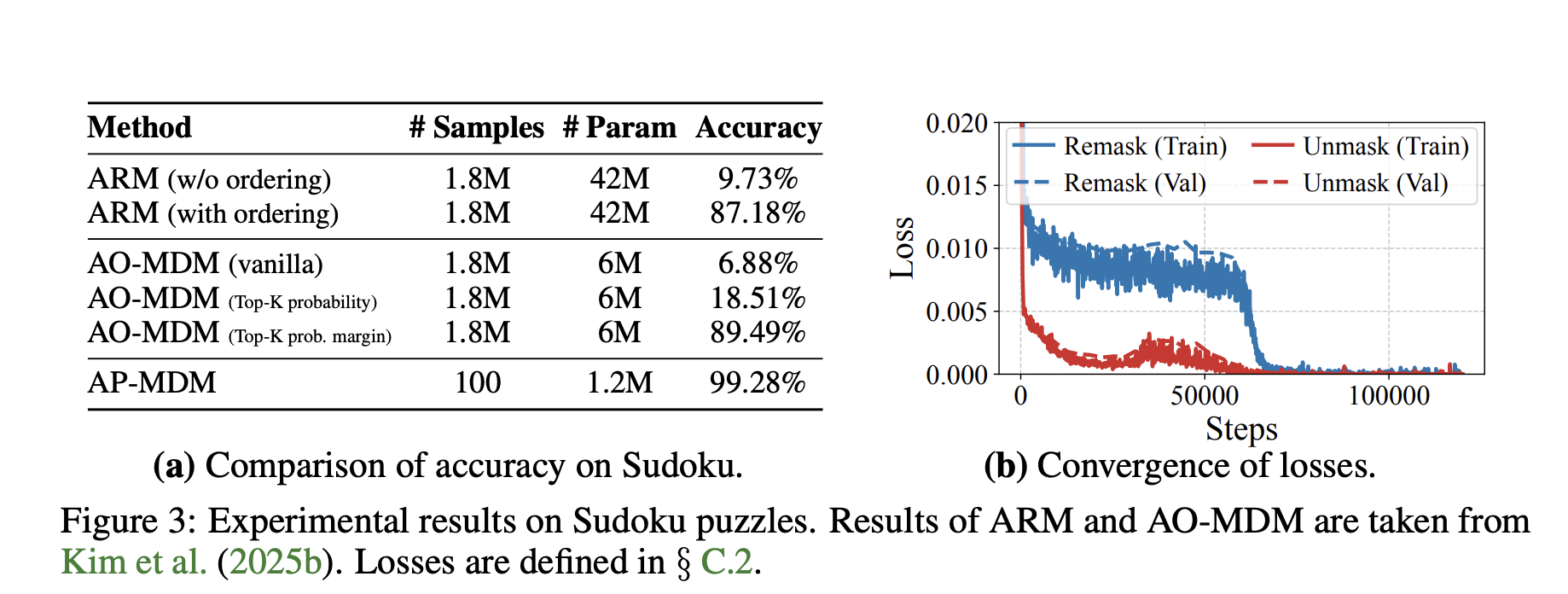
数独:小数据大惊喜
数独是NP-complete的经典。你知道吗?标准9×9是简单版,泛化到n² x n²就硬核了。AP-MDM只用100训练实例,就达99.28%准确;ARM需1.8M实例和5倍参数,才87.18%。为什么?AP-MDM用remask回溯死胡同,insert探索分支,像人类解谜。AO-MDM(纯任意顺序)也只89.49%,证明编辑操作是关键。

Dyck语言:代码生成的痛点
两侧Dyck-k模拟匹配括号。ARM顺序生成易失衡(尤其长序列),论文证明它数学上办不到。AP-MDM用insert加对、remask重试,完美生成。实际中,这对代码工具意味深远:生成函数时,确保scope一致。
图生成:结构编辑的战场
实验用max-flow图(10节点、50边,10k实例)。AP-MDM序列化图为token,用delete移除无效边、insert加约束边,准确率随规模稳如老狗。ARM随图大就崩,因为顺序难捕获全局连通。
奇偶校验:学习简单规则的艺术
奇偶校验检查比特和奇偶。AP-MDM训长度2序列,就100%泛化任意长——靠delete反复消除对(局部规则)。ARM需长训序列,还不稳。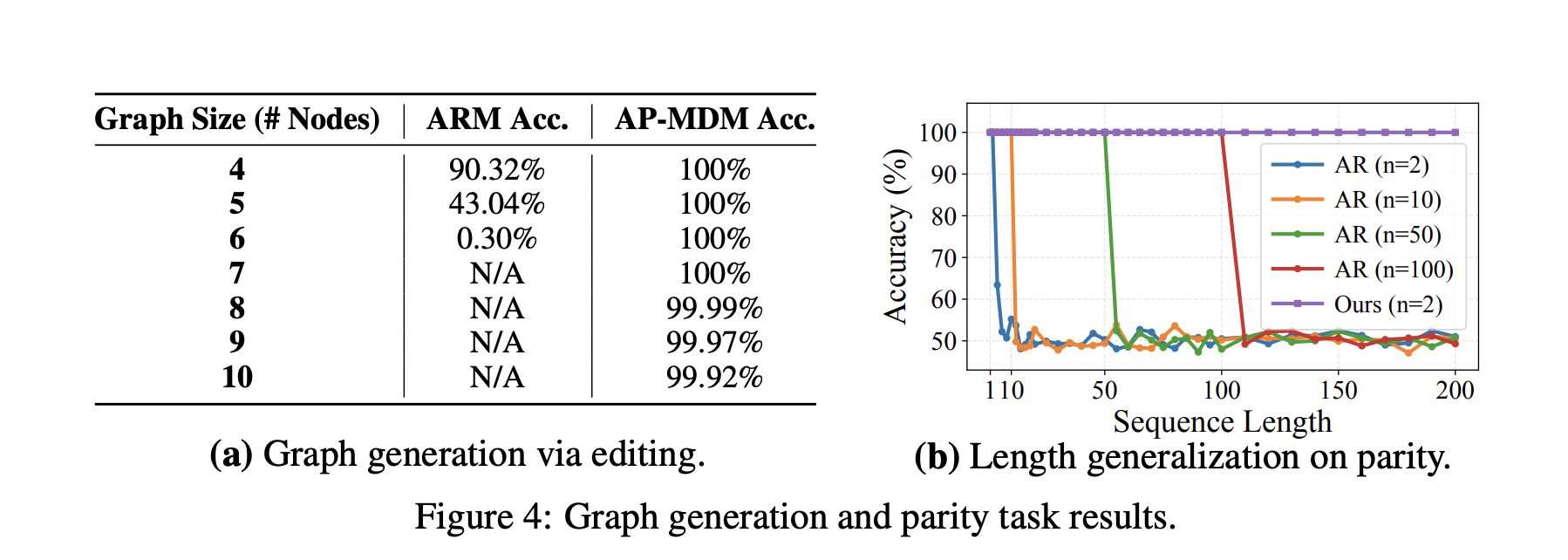

这些结果告诉我:AP-MDM不只快,还聪明。它在编码、数学、AI4Science(如蛋白设计)中潜力巨大,因为这些领域本就编辑导向。
如何上手:从安装到生成你的第一个数据集
理论听够了?来点动手。论文代码在GitHub(https://github.com/chr26195/AP-MDM),基于MDLM管道。环境是Python 3.12+,带numpy、torch等。咱们一步步走。
安装步骤
-
克隆仓库: git clone https://github.com/chr26195/AP-MDM.git && cd AP-MDM -
基础依赖: pip install -r requirements.txt(包括tqdm、numpy、torch等)。 -
Flash Attention(加速Transformer): pip install flash-attn --no-build-isolation。这对长序列必备,减少内存。
生成数据集:从简单开始
论文用控制任务验证,别担心,不是海量NLP数据。咱们试Sudoku——生成100个谜题。
Sudoku 数据集
cd dataset/sudoku
python sudoku_generator.py sudoku-100.npy
-
输出: sudoku-100.pkl.gz(训练样本)和vocab_cache.pkl(token词表)。 -
多文件: python sudoku_generator.py sudoku-100.npy sudoku-test.npy。 -
可视化: python serve.py,浏览器开http://localhost:8001/apmdm。看生成过程,像看AI解谜直播。
Parity 数据集(奇偶校验)
cd dataset/parity
python parity_generator.py
-
输出: parity_train.pkl.gz(7样本,重复扩到1000)和parity_vocab_cache.pkl(5 token:BOS, EOS, MASK, 0, 1)。 -
为什么简单?训短序列,测长泛化。
图生成数据集(Max-Flow)
cd dataset/max_flow
python maxflow_solver.py \
--num_instances 10000 \
--min_nodes 10 --max_nodes 10 \
--min_edges 50 --max_edges 50 \
--output graph.pkl.gz
-
自定义:调 --min_flow/max_flow保流约束。 -
输出: graph.pkl.gz(样本)和vocab_cache.pkl。
这些数据集小巧,适合本地跑。训评脚本在train/scripts,用PyTorch实现AP-MDM。想深挖?改--min_nodes测试规模泛化。
常见问题解答:你可能还在纠结什么?
我猜你读到这儿,可能有这些疑问。咱们直球回答。
FAQ
什么是Any-Process Generation,为什么它比标准扩散模型强?
Any-Process Generation是AP-MDM的核心,它扩展了MDM的“揭面纱”过程,加了remask、insert和delete。这些让模型像编辑器,能回溯错误、动态调整长度。标准MDM只并行揭开,但没法改已生成内容或变长短,导致在NP-hard任务上卡壳。AP-MDM理论上达PSPACE,实验上数独准99%以上。
ARM和MDM哪个适合我的项目?比如代码生成。
ARM简单,适合顺序任务如故事续写。但代码需全局约束(如括号),ARM易崩。MDM并行快,适合填充式生成;加AP-MDM编辑,就完美——insert函数、delete bug。论文证明ARM没法精确Dyck语言,AP-MDM能。
怎么用AP-MDM解决生物序列生成?
序列如DNA是图/树,AP-MDM用insert模拟重组、remask纠突变、delete剪冗余。训小数据集,就能泛化。起步:用parity代码改成序列编辑,测试平衡结构。
训练AP-MDM需要多大算力?
论文用1.2M参数,100实例本地GPU跑得动。Flash Attention帮大点。别担心规模,测试时扩展是它的强项。
AP-MDM能泛化到真实LLM吗?
能!它只加3个头到编码器Transformer,易集成现有扩散LLM。未来,编码/科学领域会先用上。
How-To: 快速构建你的AP-MDM实验
-
准备环境:如上安装。 -
生成数据:挑Sudoku跑generator。 -
训模型: cd train/scripts; python train_apmdm.py --dataset sudoku-100.pkl.gz --epochs 10(脚本细节见repo)。 -
评估: python eval.py --model checkpoint.pth --test sudoku-test.pkl.gz。测准确、步数。 -
可视:用serve.py看过程,调参观察remask使用率。 -
扩展:加 --enable_insert true测试动态长。
收尾:生成未来的新起点
聊了这么多,从ARM的线性优雅,到MDM的并行惊喜,再到AP-MDM的编辑自由,这篇论文让我反思:生成不是“下一个词”的游戏,而是算法设计。ARM/MDM在P类问题上高效,但硬推理需PSPACE级工具。AP-MDM不完美(还需更多领域验证),但它桥接了理论和实践:小数据高准、结构觉生成、OOD泛化。
如果你是开发者,试试repo里的Sudoku——生成一个谜题,看AI怎么remask纠错,那感觉像看到AI“思考”。对研究者,这提醒我们:别只规模数据,优化过程本身。未来,LLM或许不只预测,而是编辑世界。
引用论文时,别忘BibTeX:
@article{yang2025powerful,
title={On Powerful Ways to Generate: Autoregression, Diffusion, and Beyond},
author={Yang, Chenxiao and Zhou, Cai and Wipf, David and Li, Zhiyuan},
journal={arXiv preprint arXiv:2510.06190},
year={2025}
}

