Gemma 3量化模型:如何让普通显卡运行顶尖AI?

人工智能模型的计算需求一直是开发者面临的挑战。谷歌最新发布的Gemma 3量化模型(QAT)通过技术创新,让这一局面发生了根本性改变——即便是消费级显卡也能流畅运行27B参数的大型语言模型。本文将深入解析这项技术的原理、优势及实践方法。
一、为什么需要量化技术?
1.1 从H100到RTX 3090的硬件革命
传统大模型如Gemma 27B需要54GB显存(BF16精度),必须依赖NVIDIA H100等高端显卡。而通过量化技术,显存需求可压缩至14.1GB(int4),使RTX 3090等消费级显卡也能胜任。这种改变意味着:
-
成本降低:单卡成本从数万美元降至千元级 -
普及加速:个人开发者、中小团队获得与大厂同等的技术工具 -
场景拓展:模型可部署至笔记本电脑甚至移动设备
1.2 量化技术的本质
量化(Quantization)是通过降低数值精度来压缩模型的技术,类比于将高清图片转为矢量图:
| 精度类型 | 比特数 | 显存占用 | 典型硬件 |
|---|---|---|---|
| BF16 | 16位 | 54GB | H100 |
| int8 | 8位 | 27GB | A100 |
| int4 | 4位 | 14.1GB | RTX 3090 |
二、Gemma 3的量化突破
2.1 量化感知训练(QAT)的奥秘
传统量化在训练完成后进行,容易导致性能损失。Gemma 3采用QAT技术,在训练阶段就模拟低精度运算:
-
分阶段优化:在最后5000步训练中引入量化模拟 -
目标对齐:以原始高精度模型的输出为学习目标 -
损失控制:困惑度(Perplexity)下降减少54%
2.2 实测性能对比
根据Chatbot Arena的人类评分体系(Elo分数),量化后的Gemma 3展现出惊人稳定性:
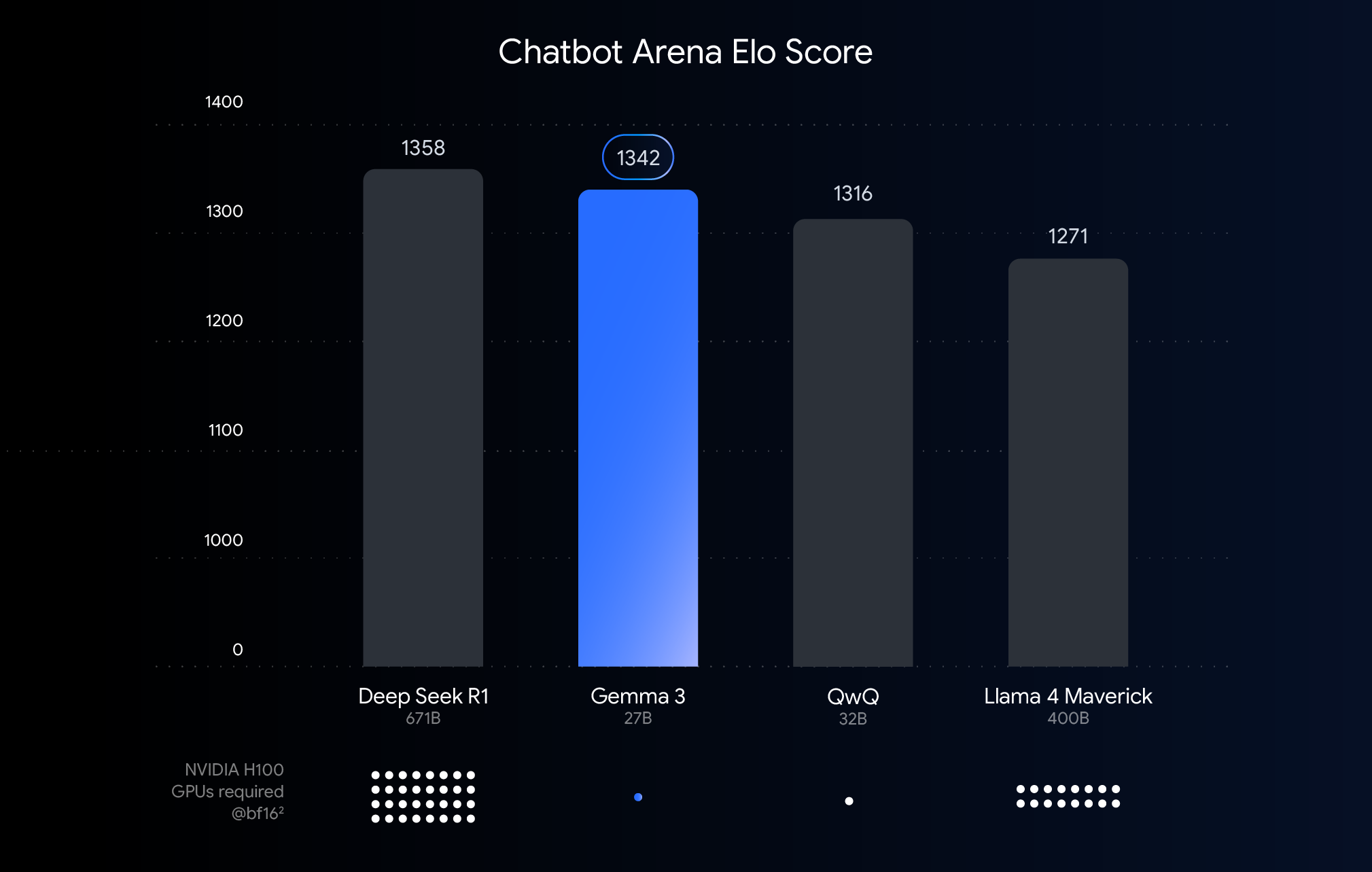
-
27B模型:量化后性能保留98.5% -
12B模型:在RTX 4060笔记本GPU上实现实时响应 -
4B模型:嵌入式设备推理速度提升3倍
三、四步实现本地部署
3.1 硬件选择指南
根据模型规模匹配设备:
| 模型版本 | 量化精度 | 显存需求 | 适配硬件 |
|---|---|---|---|
| Gemma 27B | int4 | 14.1GB | RTX 3090/4090 |
| Gemma 12B | int4 | 6.6GB | RTX 4060笔记本 |
| Gemma 4B | int4 | 2.6GB | 安卓旗舰手机 |
| Gemma 1B | int4 | 0.5GB | 树莓派5 |
3.2 工具链全景图
谷歌提供多平台支持方案:
桌面端
-
Ollama: ollama run gemma3:27b-q4一键启动 -
LM Studio:图形界面管理多模型版本 -
llama.cpp:CPU推理优化方案
移动端
-
MLX:苹果M系列芯片原生加速 -
Google AI Edge:安卓设备端侧部署
云平台
-
Hugging Face:直接调用API接口 -
Kaggle:免费GPU资源快速验证
四、技术细节深度解析
4.1 KV缓存的内存管理
模型运行除了权重加载,还需管理对话上下文(KV缓存):
-
计算公式:内存需求 = 2 × 层数 × 头数 × 维度 × 序列长度 × 字节数 -
优化策略:动态批次处理 + 上下文窗口限制 -
实测数据:2048 tokens上下文长度下,27B模型需额外8GB显存
4.2 量化格式的选择
不同场景需要匹配量化方案:
| 格式 | 优势 | 适用场景 |
|---|---|---|
| Q4_0 | 平衡精度与速度 | 通用推理 |
| Q5_K_M | 更高精度保留 | 创意文本生成 |
| Q3_K_L | 极致压缩 | 嵌入式设备 |
五、开源社区的创新实践
5.1 第三方量化方案对比
除官方QAT外,社区提供多种PTQ(训练后量化)方案:
| 提供方 | 技术特点 | 典型应用 |
|---|---|---|
| Bartowski | 混合精度量化 | 长文本生成 |
| Unsloth | 内存优化算法 | 多任务并行处理 |
| GGML | 硬件指令级优化 | 老旧设备兼容 |
5.2 量化模型的微调技巧
-
数据准备:使用原始高精度模型的输出作为监督信号 -
学习率设置:采用余弦退火策略,初始值设为1e-5 -
评估指标:同时监控困惑度和人工评估分数
六、技术变革的行业影响
6.1 开发模式的转变
-
原型验证周期:从周级缩短至小时级 -
硬件采购成本:团队入门门槛降低90% -
隐私合规:医疗/金融等敏感数据可在本地处理
6.2 新兴应用场景
-
个人知识库:在本地构建专属ChatGPT -
工业物联网:设备端实时质量检测 -
教育普惠:老旧电脑运行智能辅导系统
七、实践指南与资源汇总
7.1 快速入门路径
-
访问Hugging Face模型库 -
选择适配硬件的量化版本 -
通过Ollama/LM Studio加载模型 -
使用API或Web界面进行测试
7.2 进阶学习资源
-
量化技术白皮书 -
性能优化案例库(Kaggle) -
社区最佳实践(Gemmaverse论坛)
技术民主化的新里程碑
Gemma 3的量化突破不仅是技术优化,更代表着AI开发从”算力垄断”向”普惠创新”的转型。当27B参数模型能在游戏显卡上流畅运行,每个开发者都站在了与大厂同等的起跑线上。这场静悄悄的革命,正在重新定义人工智能的未来图景。
