嵌入检索的理论限制:为什么即使最先进的模型也会在简单任务上失败?
即使使用最好的嵌入模型和无限的数据,有些检索任务也永远无法完成——这不是技术问题,而是数学上的根本限制。
你是否曾经想过,为什么有时候即使使用了最先进的搜索引擎,它仍然无法找到你知道肯定存在的文档?或者为什么两个看似相关的文档却永远不会一起出现在搜索结果中?
这背后可能不是算法的问题,而是嵌入检索技术本身存在的理论限制。
最近,Google DeepMind 的研究人员发表了一项研究,揭示了基于向量嵌入的检索系统存在的根本性限制。他们不仅提供了理论证明,还创建了一个名为 LIMIT 的数据集来验证这一理论——结果令人惊讶:即使是最先进的嵌入模型,在这个看似简单的任务上也表现糟糕。
什么是嵌入检索?
在我们深入探讨这些限制之前,先简单了解一下嵌入检索是什么。
嵌入检索是现代信息检索系统的核心。它的基本思想是将文本(无论是查询还是文档)转换为数学空间中的点(称为向量或嵌入),然后通过计算这些点之间的距离或相似度来找到最相关的结果。
想象一下,你把所有的文档都放在一个巨大的多维空间中,相似的文档会聚集在一起。当用户输入查询时,系统也将查询转换为这个空间中的一个点,然后找到离它最近的那些文档点。
这种方法之所以强大,是因为它能够捕捉语义相似性,而不仅仅是关键词匹配。例如,它能理解” canine “和” dog “虽然用词不同,但含义相近。
理论限制:为什么嵌入维度至关重要
这项研究的核心发现是:对于任何给定的嵌入维度 d,存在某些文档组合无法作为任何查询的检索结果返回。
这是什么意思呢?让我们用一个简单的类比来解释。
假设你只能使用两个特征(如重量和颜色)来描述水果,那么你的描述能力是有限的。你可以说”找一个重100克且红色的苹果”,但如果你需要同时考虑甜度、产地和成熟度,两个特征就不够用了。
同样,嵌入维度 d 决定了模型能够区分的不同”概念”的数量。研究表明,随着文档数量 n 的增加,模型需要区分的可能组合数量呈组合级增长(具体是二项式系数,即从 n 个文档中选择 k 个的方式数),而嵌入模型能够表示的不同区域数量只能随维度 d 多项式增长。
数学形式化
研究人员通过将问题形式化为矩阵秩的问题来精确描述这一限制。假设我们有:
-
m 个查询和 n 个文档 -
一个真实相关性矩阵 A ∈ {0,1}^{m×n},其中 A_ij = 1 表示文档 j 与查询 i 相关
嵌入模型将每个查询映射到向量 u_i ∈ R^d,每个文档映射到向量 v_j ∈ R^d。相关性由点积 u_i^T v_j 建模,相关文档应比不相关文档得分更高。
研究发现,能够正确排序文档所需的最小嵌入维度 d 与矩阵 2A – 1_{m×n} 的符号秩(sign-rank)密切相关。具体来说:
rank_±(2A - 1_{m×n}) - 1 ≤ rank_rop A ≤ rank_gt A ≤ rank_±(2A - 1_{m×n})
其中 rank_rop A 是行保序秩,rank_gt A 是全局阈值秩。
这意味着什么呢?符号秩越高,准确捕捉相关性关系所需的嵌入维度就越大。对于某些矩阵,符号秩可以非常高,以至于实际可行的嵌入维度无法表示所有可能的组合。
实证验证:自由嵌入实验
理论很美好,但实际如何呢?研究人员设计了一组精巧的实验来验证这一理论限制。
他们创建了一种”自由嵌入”优化设置,其中向量本身可以直接通过梯度下降进行优化。这种方法消除了自然语言带来的任何约束,显示了任何嵌入模型解决这个问题的最佳可能性能。
实验设置如下:
-
创建一个随机文档矩阵(大小 n)和一个随机查询矩阵,包含所有 top-k 组合(即大小 m = C(n, k)) -
使用 Adam 优化器和 InfoNCE 损失函数直接优化解决约束条件 -
逐渐增加文档数量(从而增加查询的二项式数量),直到优化无法再解决问题(达到 100% 准确率) -
他们称这一点为”临界n值”
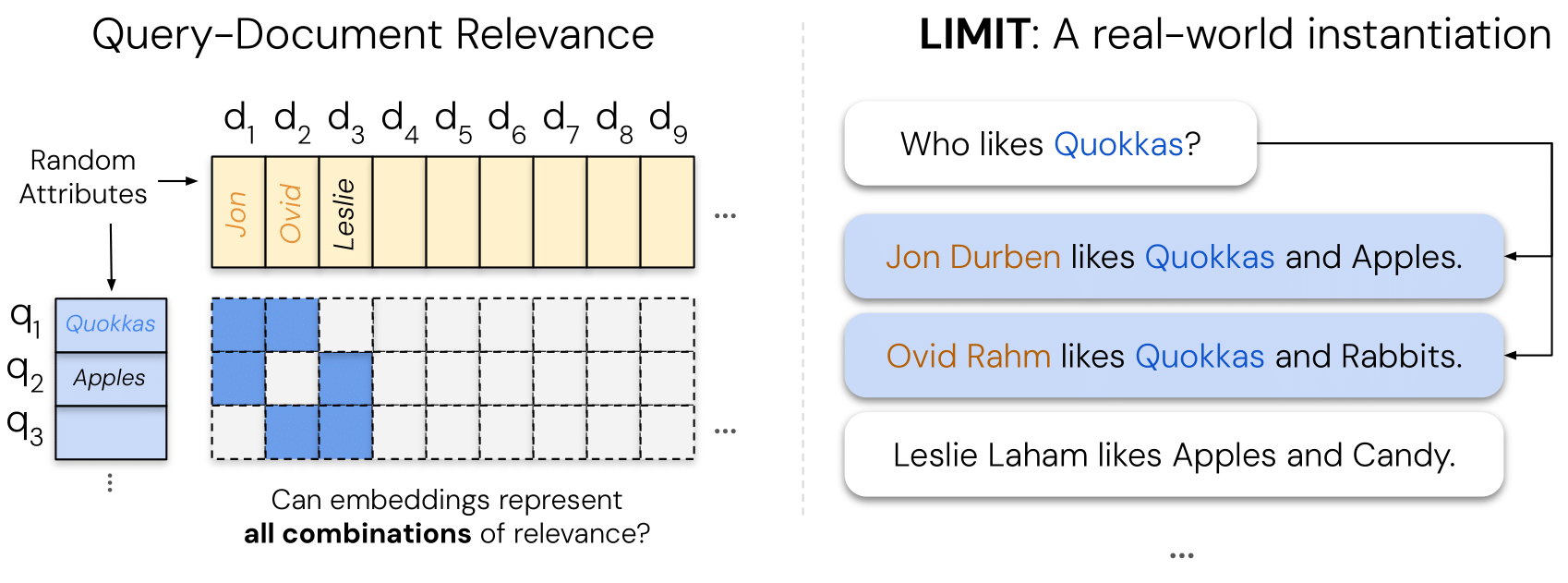
图:维度太小而无法成功表示所有 top-2 组合的临界n值。趋势线符合三次多项式函数。
结果令人惊讶:即使在这种最佳情况下,性能也会在某个点急剧下降。曲线拟合了一个三次多项式函数:
y = -10.5322 + 4.0309d + 0.0520d² + 0.0037d³ (r²=0.999)
向外推断这条曲线得到的临界n值(对于嵌入大小)为:
-
512维 → 500k文档 -
768维 → 1.7m文档 -
1024维 → 4m文档 -
3072维 → 107m文档 -
4096维 → 250m文档
请注意这是最佳情况:真实的嵌入模型无法直接优化查询和文档向量来匹配测试相关性矩阵(并且受到”建模自然语言”等因素的约束)。这些数字已经表明,对于网络规模的搜索,即使具有理想测试集优化的最大嵌入维度也不足以建模所有组合。
LIMIT 数据集:简单却困难的任务
为了在现实环境中测试这些理论限制,研究人员创建了 LIMIT 数据集——一个看似简单却极其困难的检索任务。
数据集构建
LIMIT 数据集的构建过程既巧妙又简单:
-
选择属性:收集一个人可能喜欢的属性列表(如夏威夷披萨、跑车等),通过 prompting Gemini 2.5 Pro 获得并清理至最终1850个项目 -
创建文档:使用5万个文档,每个文档赋予随机姓名和一组随机选择的属性 -
设计查询:创建1000个查询,每个查询只询问一个项目(如”谁喜欢X?”) -
设置相关性:选择46个文档,使用所有可能的双文档组合(C(46,2)=1035)作为相关文档对
尽管任务简单(例如”谁喜欢苹果?乔恩喜欢苹果”),但由于理论基础,即使最先进的嵌入模型也难以应对,对于小嵌入维度的模型甚至不可能完成。
惊人的实验结果
研究人员评估了最先进的嵌入模型,包括:
-
GritLM -
Qwen 3 Embeddings -
Promptriever -
Gemini Embeddings -
Snowflake的Arctic Embed Large v2.0 -
E5-Mistral Instruct
这些模型的嵌入维度范围从1024到4096,训练风格也各不相同(基于指令、难负样本优化等)。他们还评估了三种非单向量模型以显示区别:BM25、gte-ModernColBERT和词级TF-IDF。
结果令人震惊:模型严重困难,即使任务非常简单。
在完整设置中,模型难以达到甚至20%的recall@100,在46文档版本中,模型即使使用recall@20也无法解决任务。
以下是一些关键结果:
| 模型 | 维度 | Recall@2 | Recall@10 | Recall@100 |
|---|---|---|---|---|
| E5-Mistral 7B | 4096 | 1.3 | 2.2 | 7.3 |
| Snowflake Arctic L | 4096 | 0.4 | 0.8 | 3.3 |
| GritLM 7B | 4096 | 2.4 | 4.1 | 12.9 |
| Promptriever Llama3 8B | 4096 | 3.0 | 6.8 | 18.9 |
| Qwen3 Embed | 4096 | 0.8 | 1.8 | 4.8 |
| Gemini Embed | 3072 | 1.6 | 3.5 | 10.0 |
| GTE-ModernColBERT | default | 23.1 | 34.6 | 54.8 |
| BM25 | default | 85.7 | 90.4 | 93.6 |
表:各模型在LIMIT数据集上的表现结果
值得注意的是,BM25这种稀疏检索方法表现接近完美,而即使最好的神经嵌入模型也远远落后。这强调了问题的本质不是关于理解语义,而是关于表示所有可能组合的理论限制。
为什么这不是领域偏移问题?
一个合理的疑问是:模型表现不佳是否是因为查询与模型训练数据之间存在领域偏移?
为了测试这一点,研究人员进行了另一组实验:他们取一个现成的嵌入模型,在训练集(使用非测试集属性创建)或LIMIT的官方测试集上对其进行训练。
结果显示:
-
在训练集上训练的模型无法解决问题 -
在测试集上训练的模型可以学习任务,过拟合测试查询中的词符
这表明性能不佳不是由于领域偏移,而是任务本身固有的困难。真实嵌入模型即使有64维也无法完全解决任务,这表明现实世界的模型比自由嵌入限制多得多,加剧了图中显示的限制。
相关性模式的影响
LIMIT 之所以困难,关键在于它测试了比通常使用更多文档组合的模型。为了验证这一点,研究人员比较了四种不同的相关性模式:
-
随机:从所有组合中随机抽样 -
循环:下一个查询与上一个查询的一个文档和下一个文档相关 -
不相交:每个查询与两个新文档相关 -
密集:使用适合查询集的最大文档数的最大连接数(n选k)
结果很明显:除了密集模式外,所有模式都具有相对相似的性能。转向密集模式显示所有模型的分数显著降低:GritLM的recall@100下降50个绝对点,而E5-Mistral几乎减少了10倍(从40.4到4.8)。
与现有数据集的比较
现有的检索数据集通常使用有限数量查询的静态评估集,因为对每个查询进行相关性标注成本高昂。这意味着用于评估的查询空间只是潜在查询数量的非常小的样本。
例如,QUEST数据集有32.5万个文档和查询,每个查询有20个相关文档,总共有3357个查询。使用QUEST语料库可以返回的唯一前20文档集的数量将是C(325k,20) = 7.1e+91(比可观测宇宙中的原子估计数10^82还要大)。因此,QUEST中的3k查询只能覆盖相关性组合空间中极小的部分。
相比之下,LIMIT数据集评估了少量文档的所有top-k组合。与使用复杂查询运算符的QUEST、BrowseComp等不同,LIMIT选择非常简单的查询和文档来突出表示所有top-k组合本身的困难。
嵌入模型的替代方案
既然单向量嵌入模型有这些限制,有什么替代方案呢?
交叉编码器(Cross-Encoders)
虽然不适合大规模的第一阶段检索,但交叉编码器通常用于改进第一阶段结果。那么LIMIT对重排序器也有挑战吗?
研究人员评估了长上下文重排序器Gemini-2.5-Pro在小设置上作为比较。他们一次性给Gemini所有46个文档和所有1000个查询,要求它通过一次生成输出每个查询的相关文档。
结果发现它可以100%成功解决所有1000个查询。这与即使最好的嵌入模型也只有低于60%的recall@2形成鲜明对比。这表明LIMIT对最先进的重排序器模型来说很简单,因为它们没有基于嵌入维度的相同限制。然而,它们仍然比嵌入模型计算成本更高的限制,因此当有大量文档时不能用于第一阶段检索。
多向量模型
多向量模型通过每个序列使用多个向量并结合MaxSim运算符来表达更多内容。这些模型在LIMIT数据集上显示出前景,得分远高于单向量模型,尽管使用了较小的主干(ModernBERT)。
然而,这些模型通常不用于指令跟随或基于推理的任务,多向量技术将这些先进任务的表现如何仍然是一个悬而未决的问题。
稀疏模型
稀疏模型(包括词法和神经版本)可以被认为是单向量模型,但具有非常高的维度。这种高维度帮助BM25避免了神经嵌入模型的问题,如图3所示。由于它们的向量维度d很高,它们可以比密集向量对应物扩展到更多组合。
然而,如何将稀疏模型应用于指令跟随和基于推理的任务尚不清楚,这些任务中没有词法甚至类似释义的重叠。这个方向留给未来的工作。
实际影响和未来方向
这项研究对信息检索领域有着深远的影响:
-
评估设计:学术基准测试只测试了可能发出的查询的一小部分(而且这些查询通常被过拟合),隐藏了这些限制。研究人员在设计评估时应该意识到这些限制。
-
模型选择:当尝试创建能够处理全方位基于指令的查询的模型时(即任何查询和相关性定义),应该选择替代检索方法——如交叉编码器或多向量模型。
-
理论认识:社区应该认识到,随着赋予嵌入模型的任务需要返回日益增长的top-k相关文档组合(例如,通过逻辑运算符连接先前不相关的文档),我们将达到它们无法表示的组合限制。
-
未来研究:需要开发新的方法来解决这一根本限制,可能包括混合检索系统、动态嵌入维度或完全不同的检索范式。
常见问题解答
嵌入检索是什么?
嵌入检索是一种现代信息检索方法,它将文本转换为数学空间中的向量表示,通过计算向量之间的相似度来找到最相关的结果。这种方法能够捕捉语义相似性,而不仅仅是关键词匹配。
为什么嵌入检索会有理论限制?
由于嵌入维度 d 是固定的,而可能的相关文档组合数量随着文档数量增加呈组合级增长,因此对于任何给定的嵌入维度,总存在某些文档组合无法作为任何查询的检索结果返回。这是数学上的根本限制,而不是技术实现的问题。
LIMIT 数据集为什么困难?
LIMIT 数据集测试了比通常使用更多文档组合的模型。它使用了”密集”相关性模式,即使用适合查询集的最大文档数的最大连接数(n选k),这使得它特别困难,即使任务本身看似简单。
当前最先进的嵌入模型在LIMIT上表现如何?
即使最先进的嵌入模型在LIMIT上也表现不佳,在完整设置中难以达到甚至20%的recall@100,在46文档版本中即使使用recall@20也无法解决任务。性能高度依赖嵌入维度,维度越大性能越好。
有什么替代方案可以克服这些限制?
替代方案包括交叉编码器(计算成本高但表现好)、多向量模型(比单向量模型表达力更强)和稀疏模型(如BM25,具有非常高维度)。每种方法都有其权衡,需要根据具体应用场景选择。
这些限制会影响实际应用吗?
是的,随着指令跟随检索的增长,用户可能会创建越来越复杂的查询,连接先前不相关的概念,这些限制会变得更加明显。设计检索系统时需要意识到这些限制,并在适当的时候使用替代方法。
结论
这项研究揭示了基于向量嵌入的检索系统的根本限制。通过理论分析和实证验证,研究人员表明,对于任何给定的嵌入维度 d,存在某些文档组合无法作为任何查询的检索结果返回。
他们创建的LIMIT数据集即使对最先进的模型也构成了巨大挑战,突显了当前单向量嵌入范式的限制。这些发现表明,社区应该考虑基于指令的检索将如何影响检索器,因为将会存在无法表示的top-k文档组合。
未来的研究方向包括开发更表达力的检索器架构,更好地理解实际相关性矩阵的符号秩,以及设计考虑这些限制的评估基准。
这项工作不仅增进了我们对嵌入检索理论基础的理解,也为未来开发更强大、更可靠的检索系统指明了方向。
本文基于Google DeepMind的研究论文《On the Theoretical Limitations of Embedding-based Retrieval》,更多技术细节和实验数据请参考原始论文和GitHub仓库。
