Exploring Stax: Google’s Practical Tool for Evaluating Large Language Models
What is the core question this article answers? How can developers effectively evaluate and compare large language models (LLMs) for their specific use cases using Google’s Stax tool?
Stax is an experimental developer tool from Google AI designed to help evaluate LLMs by testing models and prompts against custom criteria. It addresses the challenges of probabilistic AI systems, where responses vary, making traditional testing insufficient. This article explores Stax’s features, workflows, and practical applications based on its core functionalities.
Understanding the Need for Specialized LLM Evaluation
What is the core question this section answers? Why do standard benchmarks fall short for evaluating LLMs in real-world applications?
Standard evaluation approaches like leaderboards provide high-level progress tracking but often don’t align with domain-specific needs. For instance, a model excelling in general reasoning might underperform in specialized tasks like compliance summarization or legal analysis. Stax fills this gap by allowing developers to define evaluations based on their unique requirements, focusing on quality and reliability rather than abstract scores.
In practice, developers face issues with reproducibility due to LLMs’ probabilistic nature. Stax offers a structured method to assess models and prompts, ensuring decisions are data-driven. This is particularly useful when iterating on prompts or selecting models for production.
Author Reflection: Lessons from LLM Variability
From my experience working with AI tools, the biggest lesson is that no single benchmark captures all nuances. Stax’s emphasis on custom evaluators has taught me to prioritize use-case alignment over generic rankings, leading to more reliable deployments.
Core Features of Stax
What is the core question this section answers? What are the main capabilities of Stax that help developers evaluate LLMs?
Stax’s core features include managing test datasets, using pre-built and custom evaluators, and gaining insights through analytics. It supports text-based model calls, with image support planned soon. These features enable faster shipping of LLM-powered apps with confidence.
-
Manage and Build Test Datasets: Import existing data or create new ones by prompting LLMs directly in Stax. -
Leverage Pre-Built and Custom Evaluators: Start with defaults for metrics like fluency or safety, then customize for specific needs like brand voice. -
Make Data-Driven Decisions: Analyze quality, latency, and token count to choose the best model or prompt.
For example, in a scenario where a team is building a customer support chatbot, Stax allows importing production queries as a dataset, generating responses from multiple models, and evaluating them for instruction following and verbosity.
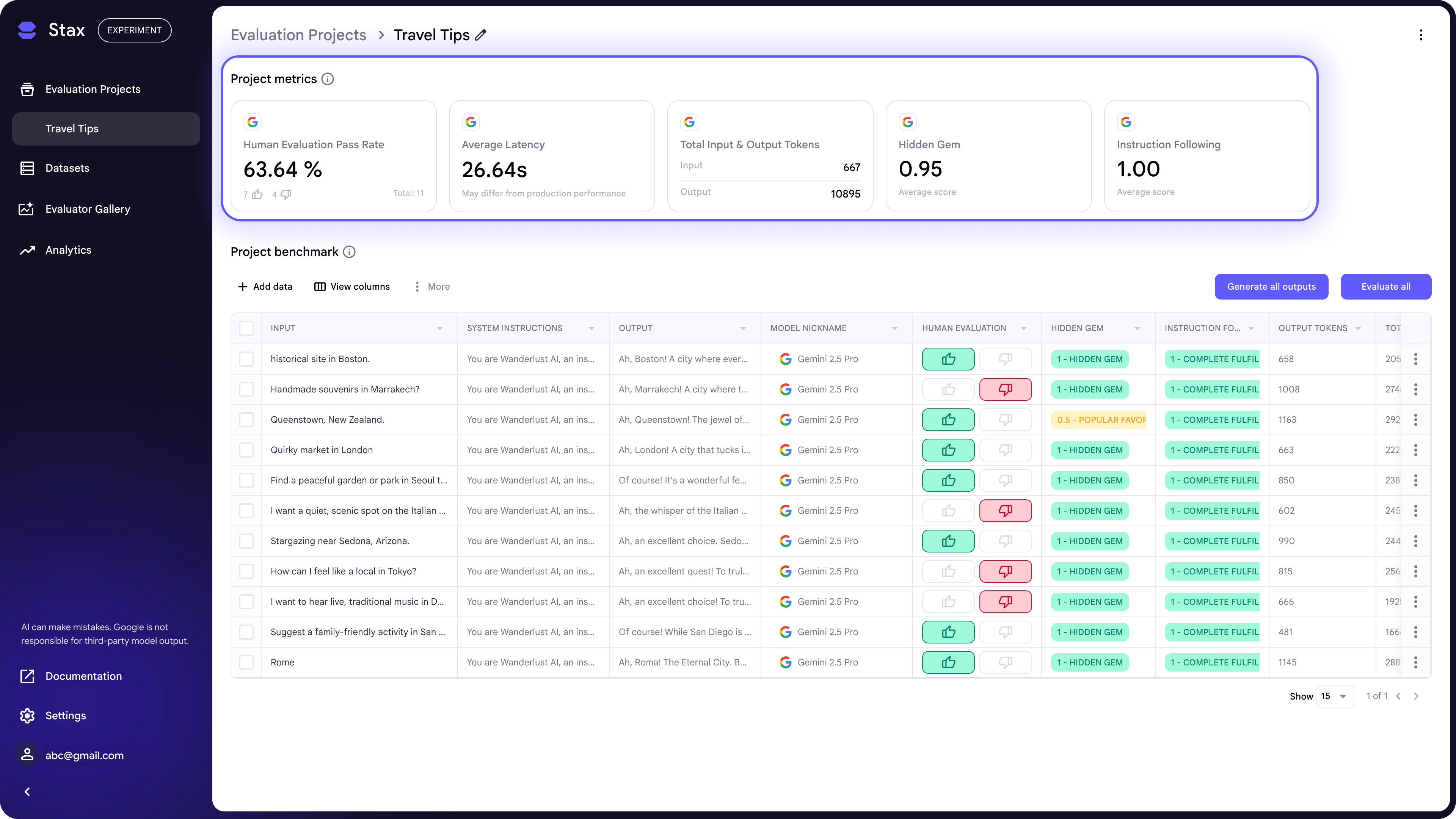
Image source: Google Developers
This visual from Stax’s project metrics page shows aggregated views of ratings, scores, and latency, helping teams compare iterations quantitatively.
Getting Started with Stax: Adding an API Key
What is the core question this section answers? How do you set up Stax by adding an API key to begin evaluations?
To start using Stax, add an API key for generating model outputs and running evaluators. Begin with a Gemini API key, as it’s the default for evaluators, though others can be configured. This key is added during onboarding or later in settings.
Step-by-step process:
-
Access the onboarding screen or navigate to Settings. -
Enter your API key details. -
Verify the key to ensure it works for model calls.
In a real-world scenario, a developer testing Gemini against another model would add keys for both, enabling side-by-side comparisons without switching tools.
Practical Example: Configuring for Multiple Providers
Imagine you’re evaluating models from different providers for a question-answering app. Add keys for each, then select them in projects. This setup streamlines testing, revealing which model handles your dataset best in terms of speed and accuracy.
Creating an Evaluation Project in Stax
What is the core question this section answers? How do you create a new evaluation project in Stax to test models or prompts?
Begin by clicking “Add Project” to create a new evaluation. Each project focuses on a single experiment, such as testing a prompt or comparing models, containing datasets, outputs, and results.
Choose between:
-
Single Model Project: For evaluating one model or system instruction. -
Side-by-Side Project: For direct comparison of two AI systems.
This structure keeps evaluations organized, corresponding to specific use cases like prompt optimization.
For instance, in developing an enterprise app for legal text analysis, create a side-by-side project to compare two models on groundedness and fluency.
Author Reflection: The Value of Project Isolation
I’ve found that isolating evaluations per project prevents data overload. This approach, as seen in Stax, reinforces the importance of focused experiments, avoiding the confusion from mixing unrelated tests.
Building Your Dataset for Evaluations
What is the core question this section answers? What are the ways to build a dataset in Stax that reflects real-world use cases?
Build datasets either manually in the Prompt Playground or by uploading existing ones. This ensures data mirrors actual scenarios, forming a robust evaluation foundation.
Option A: Adding Data Manually in the Prompt Playground
-
Select model(s) from available providers or connect custom ones. -
Set a system prompt (optional), e.g., “act as a helpful customer support agent.” -
Add user inputs as sample prompts. -
Provide human ratings (optional) for output quality.
Each entry saves as a test case. This is ideal for starting from scratch.
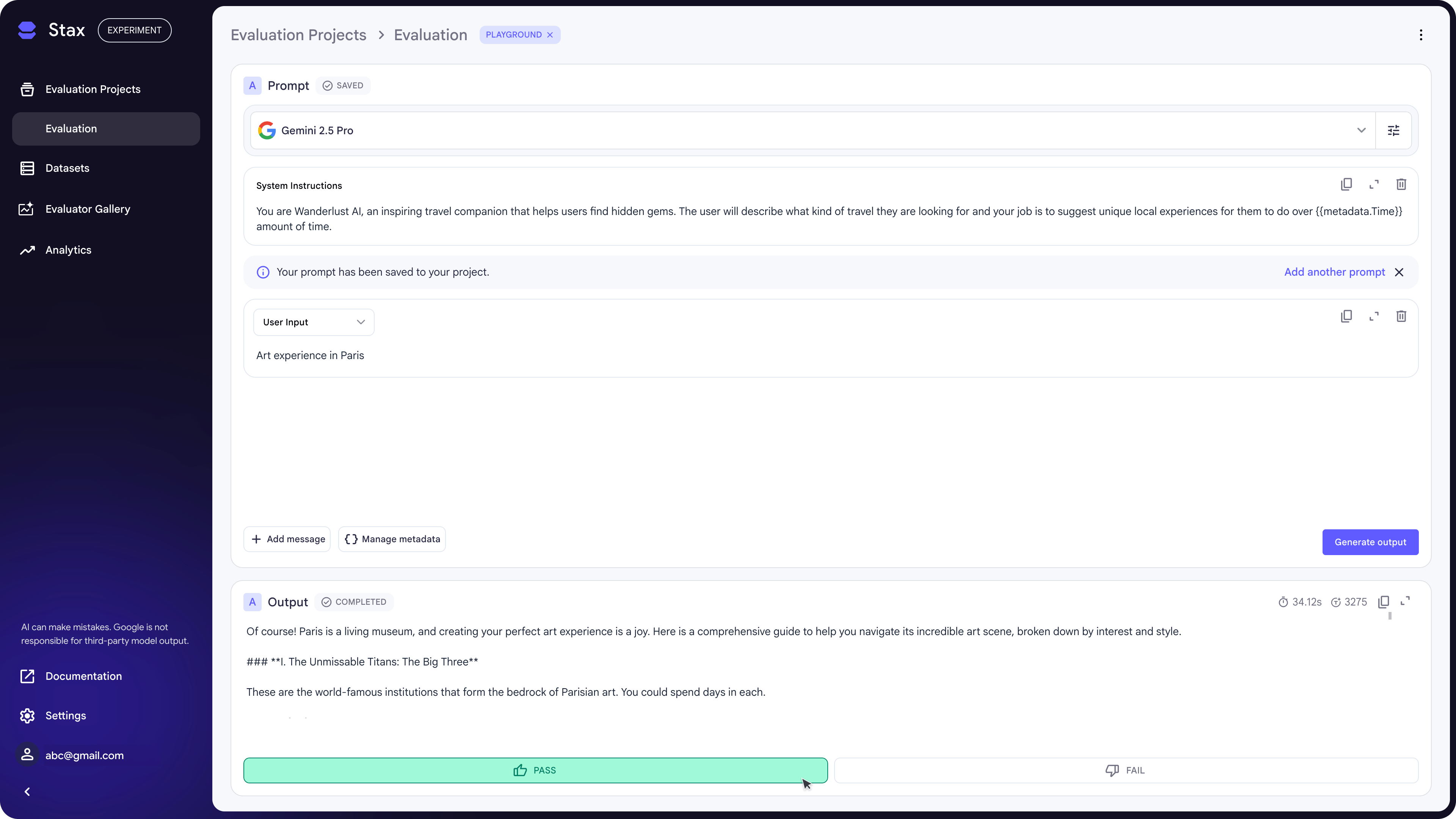
Image source: Google Developers
In this image, you see how inputs, outputs, and ratings are captured, building a dataset iteratively.
Scenario: For a content generation tool, enter varied user prompts like “Write a blog post on AI ethics” and rate responses, creating a dataset for fluency evaluation.
Option B: Uploading an Existing Dataset
Upload CSV files via “Add Data” > “Import Dataset.” If outputs are missing, generate them by selecting a model.
This suits teams with production data, ensuring evaluations are grounded in real usage.
Example: A team with logged user queries from a chatbot uploads the CSV, generates outputs from two models, and proceeds to evaluation, identifying which handles queries better.
For best practices, focus on datasets that accurately represent use cases.
Evaluating AI Outputs in Stax
What is the core question this section answers? How do you evaluate model outputs in Stax using manual and automated methods?
Evaluate outputs via manual human ratings or automated LLM-based evaluators. This step assesses quality post-generation.
-
Manual Human Evaluations: Rate outputs in the playground or project benchmark. -
Automated Evaluation: Click “Evaluate,” select pre-loaded or custom evaluators to score batches.
Pre-loaded evaluators cover standard metrics; custom ones measure specifics like business logic.
In a compliance summarization app, use a custom evaluator for accuracy against reference material, scoring outputs automatically.
Pre-Built Evaluators in Detail
Stax includes defaults for:
-
Fluency: Checks grammar and readability. -
Groundedness: Verifies factual consistency. -
Safety: Detects harmful content. -
Instruction Following: Assesses adherence to prompts. -
Verbosity: Measures response conciseness.
These provide a starting point, scalable for large datasets.
Scenario: Evaluating a news summarization tool, apply groundedness to ensure summaries match source facts, flagging inconsistencies.
Building Custom Evaluators
Create custom evaluators for nuanced qualities like brand voice. This involves defining criteria tailored to your app.
Example: For a brand-specific chatbot, build an evaluator checking tone alignment, running it on dataset outputs for scores.
Interpreting Results and Making Decisions
What is the core question this section answers? How do you use Stax’s results to decide on the best model or prompt?
Interpret via the Project Metrics section, showing aggregated human ratings, evaluator scores, and latency. This data helps compare iterations for speed vs. quality.
The Analytics dashboard displays trends, output comparisons, and model performances.
In prompt iteration, test variations and review metrics to select the most consistent one.
For model selection, compare latency and scores to choose for production.
Scenario: In domain-specific validation, analyze results to validate against organizational standards, ensuring deployment readiness.
Author Reflection: Insights from Analytics
Analytics in tools like Stax have shown me that latency often trades off with quality. Balancing these based on data, rather than intuition, has improved my AI integrations.
Quick Compare for Prompt Testing
What is the core question this section answers? How does Stax’s Quick Compare feature help test prompts across models?
Quick Compare tests prompts side by side, showing effects of variations or model choices, minimizing trial-and-error.
Use it for rapid iterations, viewing outputs directly.
Example: Refining prompts for a question-answering system, compare “Explain quantum computing simply” across models to pick the clearest.
Projects and Datasets for Scaled Evaluations
What is the core question this section answers? How do Projects and Datasets in Stax support large-scale LLM evaluations?
Projects organize evaluations at scale; Datasets apply consistent criteria across samples for reproducibility.
Create test sets, run evaluations, and track changes.
In ongoing monitoring, re-run as datasets evolve, maintaining performance.
Scenario: For enterprise question answering, build a dataset of internal queries, evaluate models, and monitor over time.
Practical Use Cases for Stax
What is the core question this section answers? What are real-world applications of Stax in LLM development?
Stax applies to:
-
Prompt Iteration: Refine for consistency. -
Model Selection: Compare before production. -
Domain-Specific Validation: Test against requirements. -
Ongoing Monitoring: Track evolutions.
For instance, in legal text analysis, evaluate for groundedness; in customer support, for safety and fluency.
Conclusion: Empowering Developers with Stax
Stax empowers developers to evaluate LLMs practically, aligning with specific needs over generic benchmarks. By providing tools for datasets, evaluators, and analytics, it streamlines decision-making for AI apps.
Author Reflection: Overall Takeaways
Reflecting on Stax, it underscores the shift from broad benchmarks to tailored evaluations. This has deepened my appreciation for data-driven AI development, ensuring tools like this make complex tech more accessible.
Image source: Unsplash (Representing data analytics in AI tools)
Practical Summary / Operation Checklist
-
Add API key in settings. -
Create project (single or side-by-side). -
Build dataset: Manual in playground or upload CSV. -
Generate outputs if needed. -
Evaluate: Manual ratings or automated evaluators. -
Interpret metrics for decisions.
One-Page Speedview
Overview: Stax evaluates LLMs via custom criteria.
Setup: Add API key, create project.
Dataset: Manual add or upload; generate outputs.
Evaluation: Manual/human or auto with pre-built/custom evaluators (fluency, groundedness, etc.).
Results: Metrics on quality, latency; analytics for insights.
Use Cases: Prompt testing, model comparison, validation, monitoring.
FAQ
-
What API key should I start with in Stax? A Gemini API key is recommended as the default.
-
How do I choose between single model and side-by-side projects? Use single for one system, side-by-side for comparing two.
-
Can I upload datasets without outputs? Yes, then generate them using a selected model.
-
What are pre-built evaluators for? They cover standard metrics like fluency and safety.
-
How do custom evaluators work? Build them to measure specific criteria like brand voice.
-
What does the analytics dashboard show? Performance trends, comparisons, and model behaviors.
-
Is image support available in Stax? It’s coming soon; currently text-based.
-
Where can I get started with Stax? Follow the quickstart guide for end-to-end workflow.
