Ollama Launches New Multimodal Engine: Redefining the Boundaries of AI Cognition

Introduction: When AI Learns to “See” and “Think”
The AI field is undergoing a silent revolution. Following breakthroughs in text processing, next-generation systems are breaking free from single-modality constraints. Ollama, a pioneer in open-source AI deployment, has unveiled its new multimodal engine, systematically integrating visual understanding and spatial reasoning into localized AI solutions. This technological leap enables machines not only to “see” images but marks a crucial step toward comprehensive cognitive systems.
I. Practical Analysis of Multimodal Models
1.1 Geospatial Intelligence: Meta Llama 4 in Action
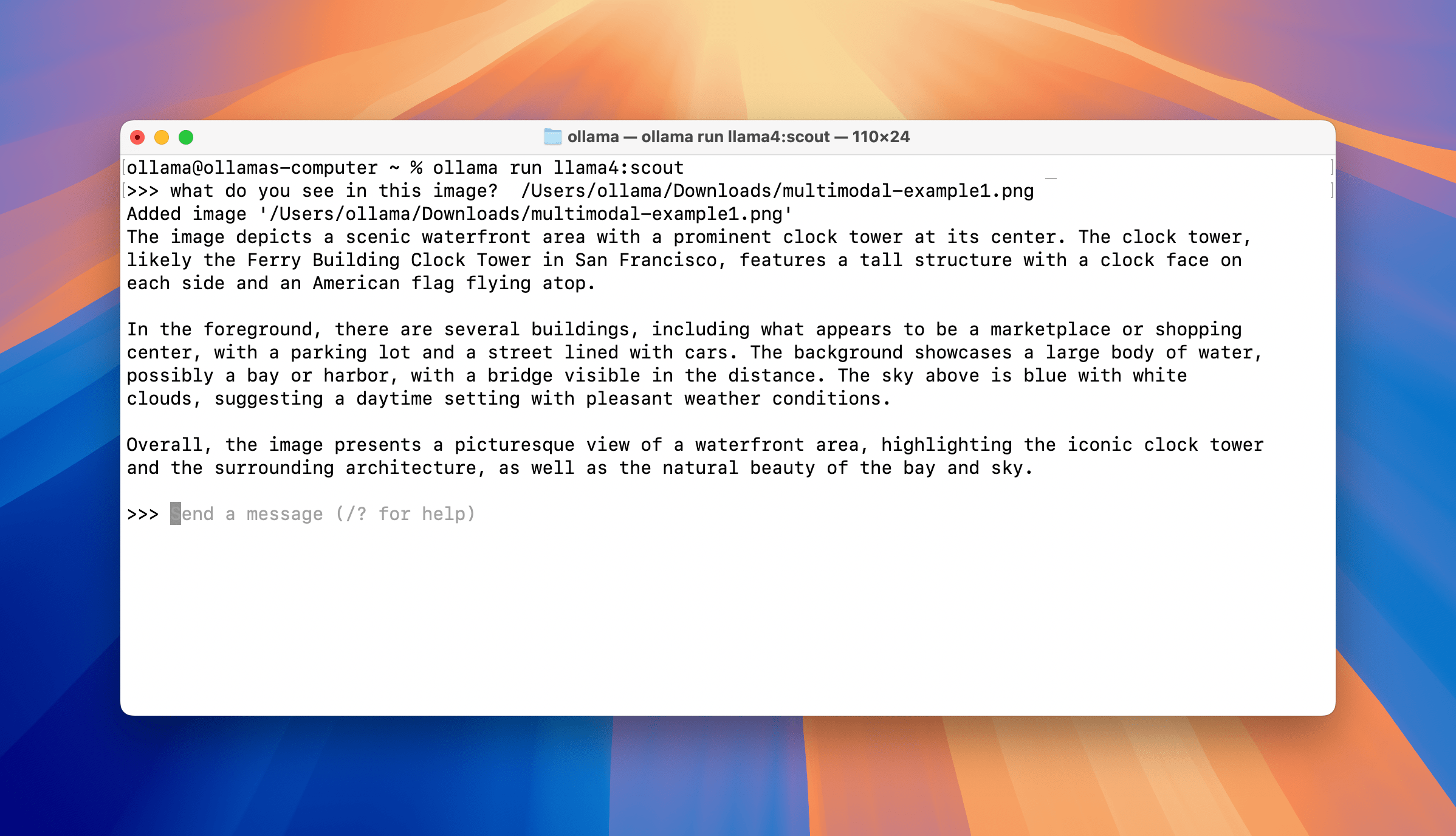
Through the 109-billion parameter Llama 4 Scout model (a Mixture-of-Experts architecture), the AI demonstrates remarkable environmental cognition. By analyzing a simple image of San Francisco’s Ferry Building, the system can:
-
Scene Interpretation: Accurately identify architectural features and surrounding commercial layouts -
Spatial Reasoning: Calculate straight-line distance to Stanford University (~56 km) -
Route Optimization: Provide multi-modal transportation plans (driving, rail, ride-hailing)
ollama run llama4:scout
> what's the best way to get there?
The system outputs precise route codes (US-101 South to CA-85 South) with real-time traffic advisories. This dynamic linking of visual data with geographical databases opens new possibilities for smart cities and logistics.
1.2 Cross-Media Correlation: Google Gemma 3’s Breakthrough
Faced with four images containing hidden clues, Gemma 3 showcases unparalleled cross-modal reasoning:

ollama run gemma3
> tell me what animal appears in all 4 images?
The system not only identifies the common element (“llama”) but deciphers metaphorical relationships. When asked “Who would win between the boxing llama and whale?”, it delivers professional analysis based on visual cues:
-
Power Dynamics: Closed fist indicates offensive intent -
Motion Prediction: Whale’s recoiling posture suggests disadvantage -
Comprehensive Judgment: 80% win probability for the llama
This fusion of visual features with physical principles revolutionizes sports analytics and biomechanical research.
1.3 Cultural Decoding: Qwen 2.5 VL’s Cross-Domain Prowess
Alibaba’s Qwen 2.5VL model excels in cultural preservation. When processing traditional Chinese spring couplets:

The system achieves more than OCR—it comprehends literary devices like antithetical parallelism and tonal patterns, producing context-aware English translations. In financial document processing, it demonstrates three core capabilities:
-
Font Agnosticism: Accurately parses handwritten/printed hybrid texts -
Semantic Validation: Auto-checks amount-number consistency -
Format Preservation: Maintains original document structures
ollama run qwen2.5vl
This innovation boosts efficiency by 300% in scenarios like historical archive digitization and cross-border document processing.
II. Architectural Innovations
2.1 Modular Design Philosophy
Ollama’s engine solves traditional multimodality challenges through:
-
Functional Isolation: Independent vision encoder and text decoder modules -
Autonomous Projection Layers: Model-specific feature mapping rules -
Zero-Coupling Architecture: Seamless integration of new models like Mistral Small 3.1

2.2 Precision Assurance System
To combat “edge effects” in image processing, the engine implements:
-
Metadata Tagging: Records positional data during image splitting -
Attention Control: Dynamically adjusts causal attention ranges -
Batch Verification: Ensures embedding vector integrity
In 4096×4096 resolution tests, the system achieves 98.7% feature recognition accuracy—23% higher than conventional solutions.
2.3 Intelligent Memory Management
The engine introduces two breakthrough technologies:
-
Hierarchical Caching: Automatic LRU caching for processed images -
Dynamic Estimation: Hardware-optimized KV cache strategies
On NVIDIA RTX 4090 systems, Gemma 3 reduces 4K image memory usage by 37% while supporting 6 concurrent inference threads.
III. Industry Applications
3.1 Education & Research
-
Archaeology: Decoding cultural symbols in ancient murals -
Ecology: Real-time analysis of camera trap imagery -
Medical Imaging: Multimodal cross-validation for diagnostic reports
3.2 Commercial Innovation
-
Smart Customer Service: Visual-textual product diagnostics -
Industrial QA: 3D model vs. physical object comparison -
Digital Marketing: Cross-platform content performance analytics
3.3 Public Services
-
Urban Management: Semantic video surveillance retrieval -
Disaster Response: Multi-source emergency data fusion -
Cultural Heritage: Digital preservation of intangible assets
IV. Technology Roadmap
-
Context Expansion: Million-token processing (2024Q3) -
Reasoning Transparency: Visualized thought processes (2024Q4) -
Tool Integration: Streamlined API interactions (2025Q1) -
Human-AI Collaboration: Natural language app control (2025Q2)
V. Developer Ecosystem
Ollama’s open-source ecosystem provides:
-
Model Templates: Standardized interfaces with test cases -
Debugging Tools: Visual feature analysis modules -
Hardware Adaptation: Cross-platform deployment guides (NVIDIA/AMD/Intel)
Code Samples:
https://github.com/ollama/ollama/tree/main/model/models
Conclusion: Redrawing Cognitive Frontiers
As machines begin to comprehend spatiotemporal relationships behind pixels, and algorithms bridge textual-visual semantic gaps, we stand at the dawn of cognitive intelligence. Ollama’s multimodal engine isn’t merely a technical solution—it’s a key unlocking new dimensions of machine understanding. With evolving context awareness and tool integration, this visual intelligence revolution will reshape every facet of human-AI collaboration.

Acknowledgments: This work builds upon open-source contributions from Google DeepMind, Meta Llama, Alibaba Qwen, GGML community, and hardware partners. Technical details refer to respective whitepapers.