miniCOIL: Revolutionizing Sparse Neural Retrieval for Modern Search Systems

In the age of information overload, efficiently retrieving relevant data from vast repositories remains a critical challenge. Traditional retrieval methods have distinct trade-offs: keyword-based approaches like BM25 prioritize speed and interpretability but lack semantic understanding, while dense neural retrievers capture contextual relationships at the cost of precision and computational overhead. miniCOIL emerges as a groundbreaking solution—a lightweight sparse neural retriever that harmonizes efficiency with semantic awareness.
This article explores miniCOIL’s design philosophy, technical innovations, and practical applications, demonstrating its potential to redefine modern search systems.
I. The Dilemma of Information Retrieval: Keywords vs. Semantics
1. Keyword-Based Retrieval: Limitations of BM25
BM25, a cornerstone of information retrieval, evaluates term relevance through statistical metrics like Term Frequency (TF) and Inverse Document Frequency (IDF). While efficient, it faces two critical shortcomings:
-
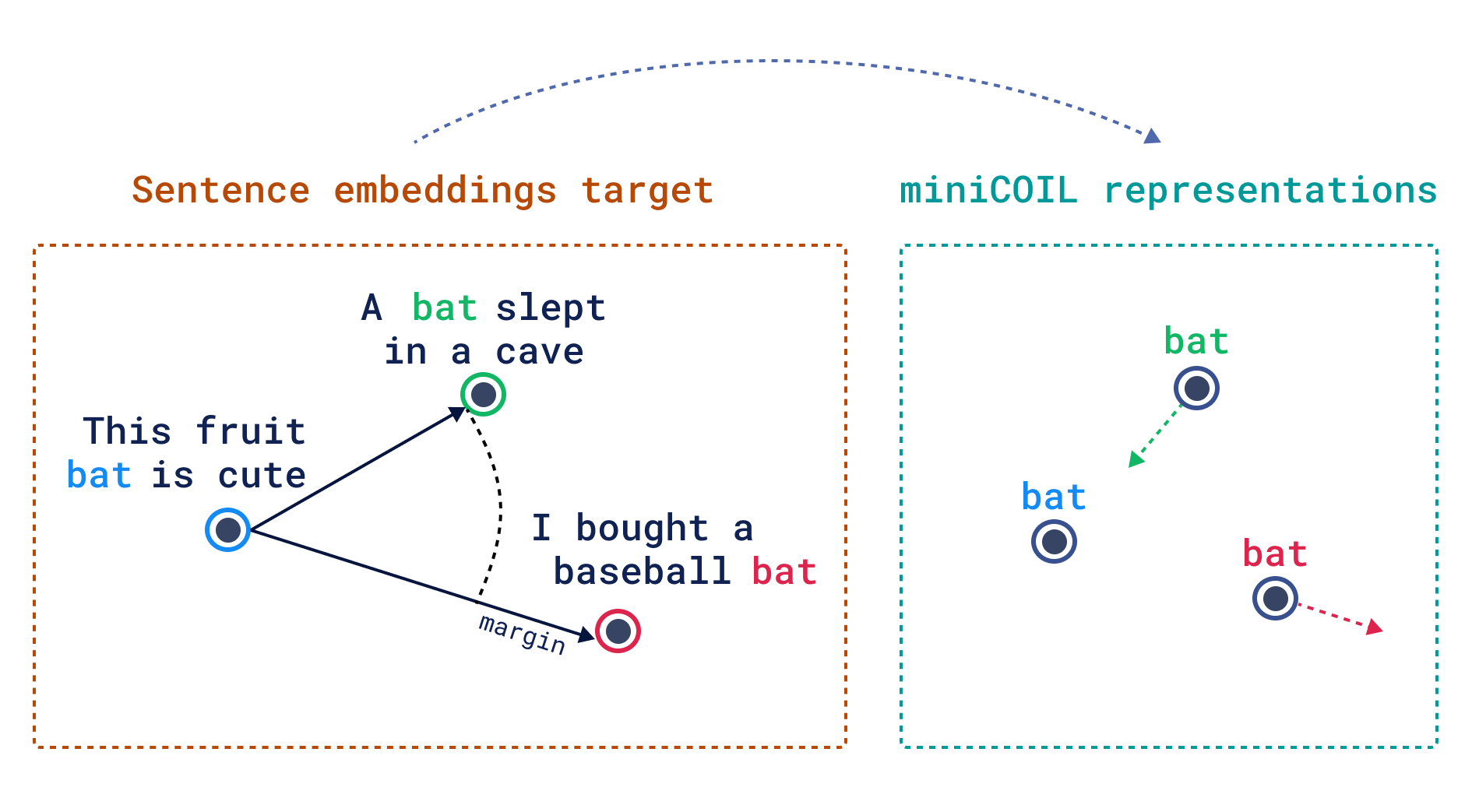
Ambiguity in Word Meanings: For example, the term “bat” could refer to an animal or a baseball tool, but BM25 cannot disambiguate context. -
Poor Performance on Short Texts: In scenarios like Retrieval-Augmented Generation (RAG), short text chunks weaken TF-IDF’s statistical relevance.
2. Dense Retrieval: The Cost of Semantic Understanding
Transformer-based dense retrievers (e.g., BERT) excel at semantic matching but introduce new challenges:
-
Keyword Precision Loss: Searching for “data point” might return irrelevant results like “floating-point precision.” -
High Computational Costs: Storing and computing high-dimensional vectors is resource-intensive for large-scale systems.
3. The Promise of Sparse Neural Retrieval
Sparse neural retrieval aims to merge the best of both worlds:
-
Sparsity: Maintains the efficiency of term-based sparse vectors. -
Semantic Awareness: Uses neural networks to dynamically weight terms based on context.
Existing models like SPLADE, however, often sacrifice speed due to query expansion techniques or struggle with domain generalization.
II. The Design Philosophy of miniCOIL: Simplicity Meets Power
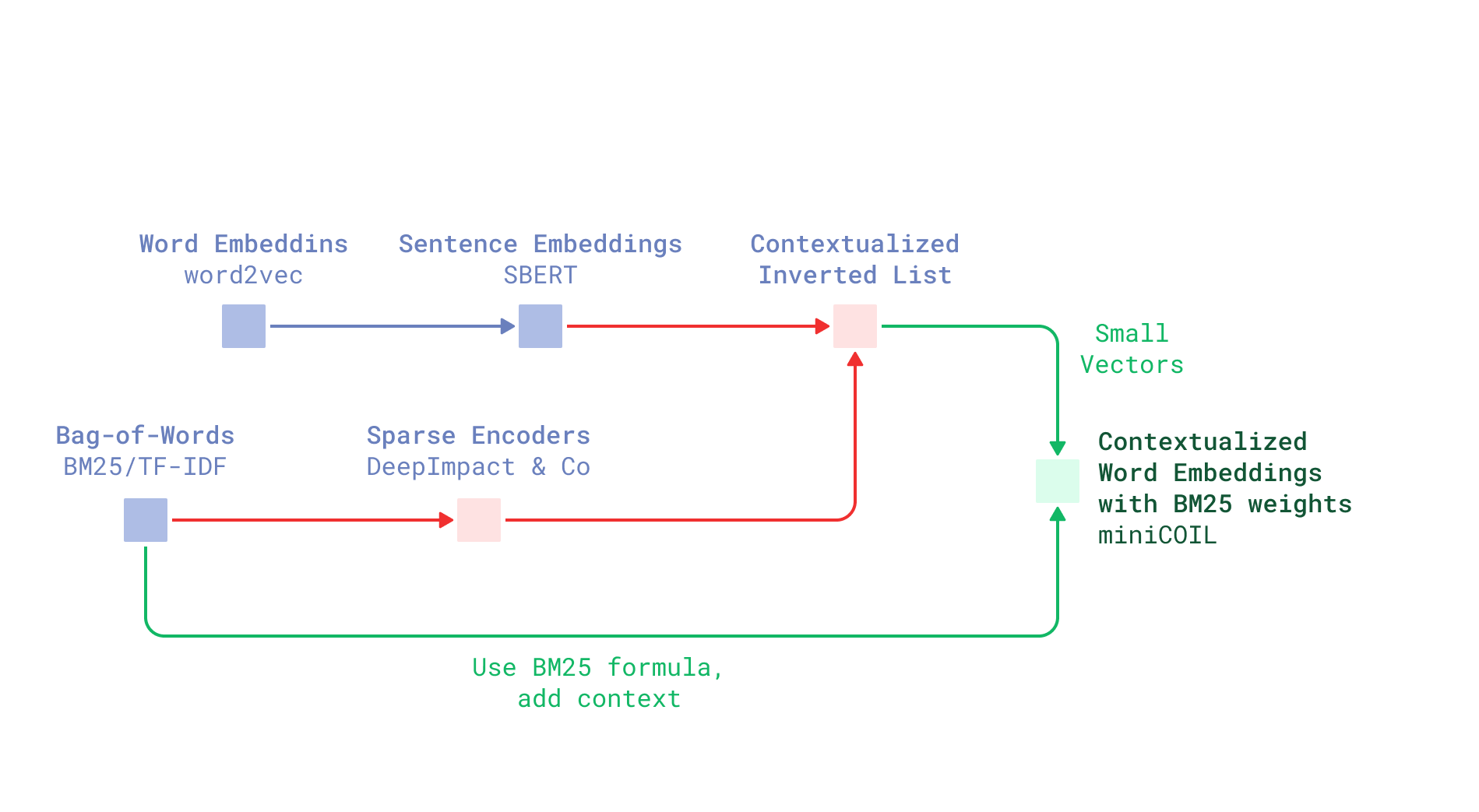
1. From COIL to miniCOIL: An Evolutionary Leap
COIL (Contextualized Inverted List) pioneered sparse neural retrieval by compressing word embeddings into 32-dimensional vectors stored in inverted indexes. Yet, its limitations were clear:
-
Index Incompatibility: Traditional inverted indexes weren’t designed for vector operations. -
Domain Dependency: Performance plateaued on out-of-domain data (e.g., trained solely on MS MARCO).
miniCOIL’s innovations address these gaps:
-
Simplified Architecture: Each word trains an independent lightweight model, avoiding complex end-to-end training. -
Backward Compatibility: Encodes word semantics into 4D vectors compatible with existing inverted indexes. -
Cross-Domain Generalization: Leverages self-supervised learning on massive unlabeled datasets.
2. Core Idea: Semantic Augmentation of BM25
miniCOIL enhances BM25 by integrating semantic weights:
Score(D, Q) = ∑ [IDF(q_i) × Term_Weight(D, q_i) × Semantic_Similarity(q_i, D)]
-
Semantic Similarity: Captures contextual meanings via 4D vectors. -
Fallback Mechanism: Automatically reverts to BM25 for untrained vocabulary.
This hybrid approach preserves BM25’s reliability while boosting ranking accuracy through semantic insights.
III. Technical Implementation: Balancing Lightweight Design and Generalization
1. Training Data and Model Architecture
-
Data Source: 40 million sentences from OpenWebText, spanning diverse domains. -
Dimensionality Reduction: Linear layers compress 512D dense vectors (e.g., Jina Embeddings) to 4D. -
Training Objective: Triplet loss ensures semantically similar sentences cluster in vector space.
2. Divide-and-Conquer Training Strategy
miniCOIL adopts a unique “one-word-one-model” paradigm:
-
Independent Training: 30,000 common English words each train a 4D vector model. -
Scalability: Vocabulary can be expanded or pruned without retraining the entire system. -
Efficient Inference: Each word trains in ~50 seconds on a single CPU, matching BM25’s speed.
3. Benchmark Validation
On BEIR benchmarks, miniCOIL outperforms BM25 across multiple domains:
| Dataset | BM25 (NDCG@10) | miniCOIL (NDCG@10) |
|---|---|---|
| MS MARCO | 0.237 | 0.244 |
| NQ | 0.304 | 0.319 |
| Quora | 0.784 | 0.802 |
| FiQA-2018 | 0.252 | 0.257 |
The sole exception is HotpotQA (0.634 vs. 0.633), highlighting room for improvement in complex reasoning tasks.
IV. Use Cases: When to Choose miniCOIL?
1. Semantic Refinement for Exact Matches
-
Example 1: Prioritizing “a data point is a record in Qdrant” over “floating-point precision” for the query “data point.” -
Example 2: Disambiguating “Apple Inc.” vs. “fruit apple” based on context.
2. Cost-Effective Hybrid Search Enhancement
-
Advantage: Reuses dense encoder outputs, upgrading sparse retrieval without added computation. -
Resource Efficiency: 4D vectors impose negligible storage and computational overhead.
3. Limitations to Consider
-
Broad Semantic Queries: For searches like “eco-friendly energy” where documents use “renewable energy,” dense retrievers remain superior. -
Long-Tail Vocabulary: Untrained rare terms default to BM25.
V. Future Directions: Toward Smarter Sparse Retrieval
1. Technical Improvements
-
Multilingual Support: Current models focus on English; expanding to other languages requires retraining. -
Dynamic Vocabulary Updates: Online learning for new terms to avoid manual updates. -
Higher-Dimensional Semantics: Exploring dimensions beyond 4D to balance efficiency and precision.
2. Ecosystem Integration
-
Open-Source Community: Code and models are available on GitHub and Hugging Face. -
Qdrant Compatibility: Direct integration via the FastEmbed library.
VI. Conclusion
miniCOIL marks a pivotal shift from theoretical research to real-world sparse neural retrieval. Instead of displacing traditional methods, it enhances BM25 with a layer of semantic intelligence—offering backward compatibility while unlocking new possibilities for context-aware search.
For developers and enterprises, miniCOIL delivers:
-
Low-Cost Upgrade: Boost retrieval quality without overhauling existing infrastructure. -
Customizability: Tailor vocabularies and models to specific use cases. -
Transparency: 4D vectors maintain interpretability, avoiding the “black box” pitfalls of dense models.
As the Qdrant team emphasizes: “Use the right tool for the job.” In scenarios where keyword precision meets semantic nuance, miniCOIL stands as a versatile Swiss Army knife—bringing us closer to search systems that truly understand both words and meanings.
Explore Further