GLM-TTS: The New Open-Source Benchmark for Emotional Zero-Shot Chinese TTS
Core question most developers are asking in late 2025: Is there finally a fully open-source TTS that can clone any voice with 3–10 seconds of audio, sound emotional, stream in real-time, and handle Chinese polyphones accurately?
The answer is yes — and it launched today.
On December 11, 2025, Zhipu AI open-sourced GLM-TTS: a production-ready, zero-shot, emotionally expressive text-to-speech system that is currently the strongest open-source Chinese TTS available.
![]()
Image credit: Official repository
Why GLM-TTS Changes Everything — In Four Bullet Points
-
Zero-shot voice cloning: 3–10 s reference audio is enough -
Streaming inference: real-time capable on a single GPU -
Emotion & prosody: boosted by multi-reward reinforcement learning (RL) -
Accurate pronunciation: Phoneme-in control for polyphones and rare characters
Let’s break down each part.
How Does Zero-Shot Cloning Work with Only 3–10 Seconds of Audio?
GLM-TTS uses a clean two-stage design that has become the industry standard but executes it exceptionally well:
-
Stage 1 – LLM generates discrete speech tokens
A Llama-based autoregressive model takes text + speaker embedding → speech token sequence -
Stage 2 – Flow Matching decoder
A Diffusion Transformer (DiT) with Continuous Flow Matching turns tokens into high-quality mel-spectrograms -
Vocoder
Currently a high-fidelity Vocoder; 2D-Vocos upgrade is coming soon
The zero-shot magic comes from the speaker embedding extracted by the CAMPPlus model in the frontend. Feed it any 3–10 second WAV, and the system instantly reproduces that voice — no per-speaker finetuning required.
Real-world use case
An audiobook app lets users record a 5-second greeting. The entire novel is then read aloud in the user’s own voice, on the fly.
Why Is Its Emotional Expressiveness a Generation Ahead?
Because it is the first open-source TTS optimized with multi-reward reinforcement learning and GRPO (Group Relative Policy Optimization).
Traditional TTS models are trained only with supervised loss — they learn to “pronounce correctly,” not to “perform.”
GLM-TTS adds several reward models after generation:
-
Speaker similarity -
Character error rate (CER) -
Emotional intensity -
Natural laughter -
Prosodic naturalness
A distributed reward server scores every candidate, and GRPO updates the LLM policy accordingly.
Objective results on the Seed-TTS-Eval Chinese test set (no phoneme mode)
| Model | CER ↓ | SIM ↑ | Fully Open-Source |
|---|---|---|---|
| MiniMax | 0.83 | 78.3 | No |
| VoxCPM | 0.93 | 77.2 | Yes |
| GLM-TTS (base) | 1.03 | 76.1 | Yes |
| GLM-TTS_RL | 0.89 | 76.4 | Yes |
The RL variant drops CER from 1.03 → 0.89 while keeping (or slightly improving) similarity — a clear leap in naturalness.
Personal take
Scale is no longer the bottleneck in 2025. Teaching a model to be judged (via RL) is the real differentiator. GLM-TTS proves it works for speech.
How Does It Solve Chinese Polyphones and Rare Characters?
Through the Phoneme-in (hybrid phoneme + text) mechanism.
During training, random characters are replaced with their pinyin so the model learns both modalities.
At inference, you can force exact pronunciation:
我是要去行[xíng]李,还是乘航[háng]班?
Just add the desired pinyin in brackets.
One-line activation
python glmtts_inference.py --data=example_zh --phoneme
Use case
Educational assessment platforms or children’s story apps can guarantee “长大” is read as cháng and “生长” as zhǎng — no more embarrassing mistakes.
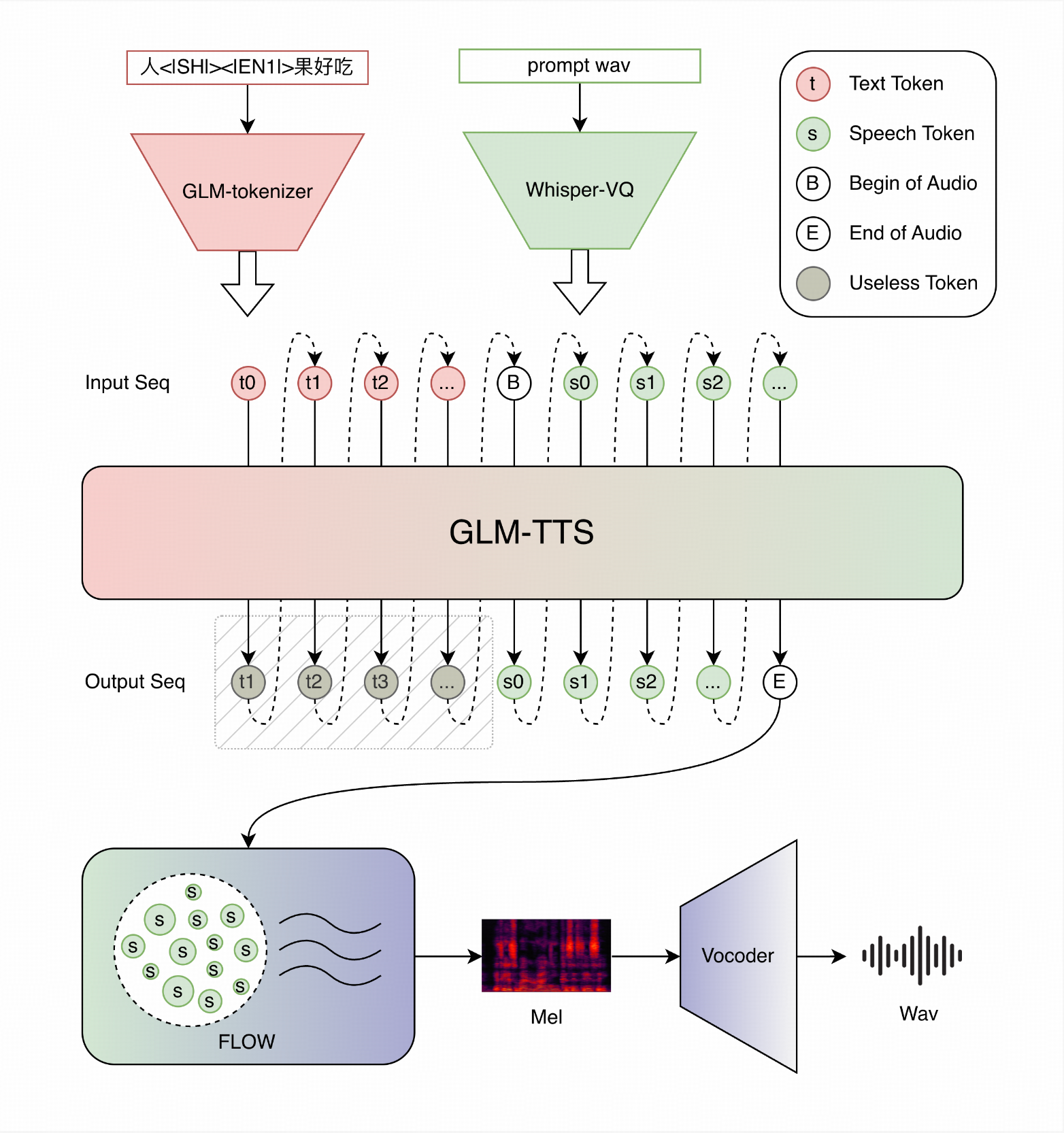
Image credit: Official repository
How to Run It Locally in Under 10 Minutes
Environment (Python 3.10–3.12)
git clone https://github.com/zai-org/GLM-TTS.git
cd GLM-TTS
pip install -r requirements.txt
Download the full checkpoint (~15 GB)
# Option 1 – Hugging Face (recommended)
huggingface-cli download zai-org/GLM-TTS --local-dir ckpt
# Option 2 – ModelScope
pip install modelscope
modelscope download --model ZhipuAI/GLM-TTS --local-dir ckpt
Quick inference
# One-click script
bash glmtts_inference.sh
# Or manual
python glmtts_inference.py --data=example_zh --exp_name=test --use_cache
Interactive Web UI (Gradio)
python tools/gradio_app.py
Upload your reference audio, type text, tweak temperature/top_p, and listen instantly.
Streaming Performance
Thanks to Flow Matching, streaming is built-in. On an RTX 4090 you get 3–5× real-time speed — perfect for live assistants, game characters, or streaming commentary.
Quick Codebase Map
GLM-TTS/
├── glmtts_inference.py # Main inference entry
├── llm/glmtts.py # Llama-based TTS backbone
├── flow/ # DiT + Flow Matching
├── cosyvoice/cli/frontend.py # Text normalization & speaker embedding
├── grpo/ # Full RL training code (GRPO, rewards, server)
└── tools/gradio_app.py # Web demo
One-Page Summary
| Feature | Supported | Notes |
|---|---|---|
| Zero-shot cloning | Yes | 3–10 s reference |
| Streaming inference | Yes | 3–5× RT on 4090 |
| Multi-reward RL | Yes | Best open-source CER 0.89 |
| Phoneme control | Yes | Perfect polyphone handling |
| Chinese + English mixed | Yes | Native support |
| Gradio Web UI | Yes | One command launch |
| License | Apache 2.0 (model) | Reference audio for research only |
FAQ
-
Is 3 seconds of reference really enough?
Yes. 5–10 seconds gives even more stable timbre. -
Does it work with pure English text?
Yes, mixed Chinese-English is fully supported; pure English works but Chinese is stronger. -
When will the RL-finetuned weights be released?
Marked as “Coming Soon” in the official roadmap. -
Can I deploy it offline?
Absolutely — everything is downloadable. -
Commercial use restrictions?
Model weights are Apache 2.0. Included prompt audio is research-only; replace with your own for production. -
Relationship with CosyVoice?
Shares frontend and vocoder code, but backbone LLM, Flow, and RL are completely new. -
VRAM requirements?
~20–24 GB for comfortable inference; streaming runs easily on a single 4090. -
Will training code be released?
RL training code is already public; pre-training code not yet.
GLM-TTS is not just “another open-source TTS.”
It is the first fully open model that Chinese developers can take straight to production with emotional, real-time, zero-shot capabilities.
Go star the repo and try it today — 2025 just raised the bar for open Chinese speech synthesis.
https://github.com/zai-org/GLM-TTS
Happy synthesizing! 🚀
