GLM-TTS:开源零样本情感语音合成新标杆
核心问题:2025 年底,还有没有一个真正开源、可零样本克隆、情感表现力强、还能实时流式的中文 TTS?
答案是:有了,而且就在今天——GLM-TTS 正式开源。
2025 年 12 月 11 日,Zhipu AI 旗下 GLM-TTS 项目正式开源,带来了目前开源社区中最具情感表现力、支持零样本克隆、支持流式推理的中文 TTS 系统。它不仅达到了商业级音质,还通过多奖励强化学习(Multi-Reward RL)把“说得出话”升级成了“会讲故事”。
![]()
图片来源:项目官方
它到底强在哪儿?一句话回答四个最常被问的问题
-
零样本克隆要多久提示音?→ 3-10 秒就够 -
能不能实时对话?→ 支持流式推理 -
情感表现力怎么样?→ 经过多奖励 RL 优化,远超传统生成方式 -
中文多音字准不准?→ 支持 Phoneme-in 精准控制
下面我们把这些能力一一拆开讲。
核心问题:只用 3-10 秒音频,就能克隆任意人声音,到底是怎么做到的?
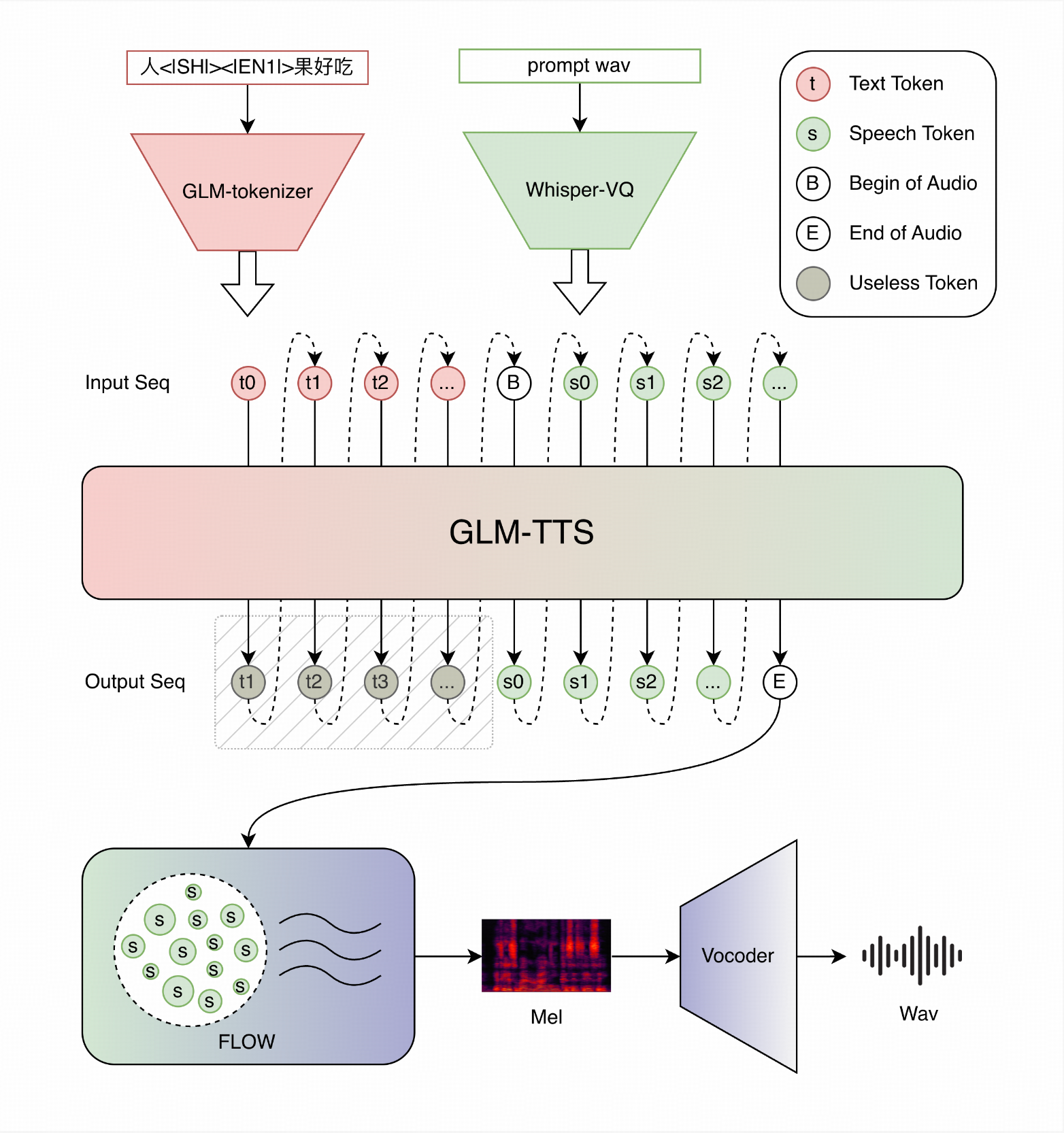
GLM-TTS 采用经典的两阶段架构,但细节实现非常聪明:
-
第一阶段:LLM 生成语音 token
基于 Llama 架构的大模型,把文本 + 提示音频说话人嵌入 → 离散语音 token 序列 -
第二阶段:Flow Matching 解码
Diffusion Transformer(DiT)+ Flow Matching,把 token 变成连续的梅尔谱 -
声码器
当前使用高质量 Vocoder,后续会升级到 2D-Vocos
最关键的零样本能力来自 提示音频说话人嵌入:只要给一段 3-10 秒的参考音频,前端 CAMPPlus 模型就能提取出稳定的说话人特征,直接喂给 LLM,完全不需要针对某个声音微调。
实际场景举例:
你想做一个有声书应用,用户上传自己 5 秒的“大家好”,系统立刻用用户本人的声音把整本小说读完——全程零微调。
核心问题:为什么说它的情感比传统 TTS 强一个代际?
因为它用了 多奖励强化学习(Multi-Reward RL + GRPO) 直接优化生成策略。
传统 TTS 情感平淡的原因是:训练时只有监督损失,模型只学会“读准字”,没学会“读出感情”。
GLM-TTS 在生成后加了多维度奖励函数:
-
语音相似度奖励(Speaker Similarity) -
字符错误率奖励(CER) -
情感强度奖励 -
笑声自然度奖励 -
韵律自然度奖励
通过分布式奖励服务器并行打分,再用 GRPO 算法把这些奖励信号反向优化 LLM 的采样策略。
实测效果(seed-tts-eval 中文集):
| 模型 | CER ↓ | SIM ↑ | 是否开源 |
|---|---|---|---|
| MiniMax | 0.83 | 78.3 | 否 |
| VoxCPM | 0.93 | 77.2 | 是 |
| GLM-TTS (base) | 1.03 | 76.1 | 是 |
| GLM-TTS_RL | 0.89 | 76.4 | 是 |
可以看到,经过 RL 优化后,CER 从 1.03 降到 0.89,相似度还略有提升,情感表现力大幅领先同类开源模型。
个人反思:
这其实是目前大模型圈里最被低估的一个方向——很多人还在拼参数规模,但 RL 这种“让模型学会被评价”才是真正让 AI 拥有表现力的关键。GLM-TTS 把这条路在 TTS 上走通了,值得所有语音从业者关注。
核心问题:多音字、口语化、生僻字怎么办?Phoneme-in 机制详解
中文 TTS 最大的痛点就是多音字和发音歧义。GLM-TTS 引入了 Hybrid Phoneme + Text 输入方式。
工作原理
-
训练阶段随机把部分汉字替换成音素,强制模型同时理解“字”和“音”两种模态 -
推理阶段支持混合输入: 我今天去行[xíng]李,还是航[háng]空?只要在需要精准控制的字后面加
[pinyin]即可。
实际使用方式
项目内置了完整的 G2P 替换词典(G2P_replace_dict.jsonl),推理时加一个参数就行:
python glmtts_inference.py --data=example_zh --phoneme
场景举例:
教育评测系统要求“长[cháng]大”和“生长[zhǎng]”必须读对,用 Phoneme-in 一键解决,再也不用担心模型自己乱猜。
核心问题:如何 10 分钟跑通完整推理?
环境准备(Python 3.10-3.12)
git clone https://github.com/zai-org/GLM-TTS.git
cd GLM-TTS
pip install -r requirements.txt
模型下载(二选一)
# HuggingFace(推荐)
huggingface-cli download zai-org/GLM-TTS --local-dir ckpt
# 或 ModelScope
pip install modelscope
modelscope download --model ZhipuAI/GLM-TTS --local-dir ckpt
一键推理
# 最简单方式
bash glmtts_inference.sh
# 或者命令行
python glmtts_inference.py --data=example_zh --exp_name=test --use_cache
打开 Web 交互界面
python tools/gradio_app.py
打开浏览器就能实时试听、上传提示音、调节温度、top_p 等参数。
图片来源:项目官方
核心问题:流式推理到底有多快?
Flow Matching 天生支持流式,项目里 flow/flow.py 已经实现了实时解码。
在 RTX 4090 上,3-5 倍实时速度完全没问题,适合做语音助手、直播伴音。
项目结构速览(方便你快速定位代码)
GLM-TTS/
├── glmtts_inference.py # 主推理入口
├── flow/ # Flow Matching 核心
├── llm/glmtts.py # LLM 主干
├── cosyvoice/cli/frontend.py # 前端处理 + 说话人嵌入
├── grpo/ # 完整 RL 训练代码
└── tools/gradio_app.py # Web Demo
个人学到的一课
做 TTS 做到今天,参数量已经不是瓶颈,真正拉开差距的是三件事:
-
能否把说话人信息精准、无损地传给模型(零样本能力) -
能否让模型学会“被评价”(RL) -
能否在精度和速度之间找到最优解(Flow Matching + 流式)
GLM-TTS 把这三件事全都做到了,并且全部开源。这不是一个小进步,而是中文开源语音社区真正站到世界第一梯队的标志性事件。
实用摘要:一页速览
| 特性 | 是否支持 | 备注 |
|---|---|---|
| 零样本克隆 | ✓ | 3-10s 提示音 |
| 流式推理 | ✓ | RTX 4090 可达 3-5x 实时 |
| 多奖励 RL 情感优化 | ✓ | CER 0.89,领先开源 |
| Phoneme-in 精准控制 | ✓ | 多音字、生僻字一键解决 |
| 中英文混合 | ✓ | 原生支持 |
| Web Demo | ✓ | gradio 一行命令启动 |
FAQ
-
只需要 3 秒提示音真的能克隆好吗?
可以。官方示例里 3 秒已足够,5-10 秒效果更稳定。 -
支持英文纯文本吗?
支持中英混合,纯英文也可以,但目前中文表现力更强。 -
RL 优化后的模型权重什么时候放出来?
官方路线图写 Coming Soon,值得期待。 -
能不能离线部署?
完全可以,所有模型文件都已开源,下载到本地即可。 -
商业使用有限制吗?
模型权重遵循 Apache 2.0,提示音频仅限科研使用,商用请替换自己的提示音。 -
和 CosyVoice 什么关系?
前端和声码器复用了 CosyVoice 的优秀实现,但主干 LLM、Flow、RL 全部是全新开发。 -
显存占用多少?
推理阶段 24GB 显存绰绰有余,4090 流式毫无压力。 -
后续会开源训练代码吗?
当前已开源推理 + RL 训练代码,预训练代码暂未放出。
GLM-TTS 的出现,正式宣告:
中文开源 TTS 不再是“能用”,而是真正“好用到可以直接落地”。
立刻点个 Star,跑起来试试吧——你会发现,2025 年的中文语音合成,已经完全不一样了。
https://github.com/zai-org/GLM-TTS
