引言:当 LLM 规模遇上网络瓶颈
想象一下,你正在尝试运行一个拥有万亿参数的大型语言模型,比如 DeepSeek V3(6710 亿参数)或 Kimi K2(1 万亿参数)。这些模型已经无法在单个 8 GPU 服务器上完整部署,必须跨多个计算节点分布。这时,你会发现一个令人惊讶的事实:制约性能的主要因素不再是计算能力(FLOPs),而是 GPU 之间的网络通信效率。
这就是现代大型语言模型系统面临的核心挑战。随着模型规模的爆炸式增长,传统的集体通信库(如 NCCL)在处理动态、稀疏的通信模式时显得力不从心。更复杂的是,不同云服务商采用了不同的 RDMA 网络硬件——NVIDIA ConnectX-7 使用有序传输,而 AWS Elastic Fabric Adapter(EFA)则采用无序传输协议。这种硬件碎片化导致现有的通信库要么性能严重下降,要么完全无法在跨供应商环境中工作。
Perplexity AI 的研究团队在技术论文中明确指出:“在本文工作之前,LLM 推理没有可行的跨提供商解决方案。”这一陈述揭示了行业面临的严峻现实:要么被锁定在单一硬件供应商,要么承担巨大的性能损失。
RDMA 网络:LLM 系统的隐形支柱
什么是 RDMA,为什么它对 LLM 如此重要?
远程直接内存访问(RDMA)是现代高性能计算的核心技术。它允许网络适配器直接访问远程主机的内存,无需 CPU 参与,从而实现了高吞吐量和低延迟的数据传输。在当前部署中,RDMA 网络接口卡(NIC)能够提供 400 Gbps 的带宽和微秒级的延迟。
对于大型语言模型系统,特别是混合专家模型(MoE)和分解推理架构,RDMA 的价值更加凸显:
- ❀
混合专家模型:每个输入令牌只需激活少数专家,产生稀疏但需要精确路由的通信模式 - ❀
分解推理:预填充和解码阶段运行在分离的设备上,需要高效的键值缓存(KvCache)传输 - ❀
异步强化学习:训练和推理节点分离,需要快速更新万亿级参数
云环境的网络碎片化挑战
当前主要云提供商部署了不同的 RDMA 实现:
- ❀
NVIDIA ConnectX 系列:使用传统的可靠连接(RC)传输,保证有序交付 - ❀
AWS Elastic Fabric Adapter(EFA):实现专有的可扩展可靠数据报(SRD)协议,提供可靠但无序的交付 - ❀
阿里云 eRDMA 和 Google Falcon:其他云服务商的定制解决方案
这种多样性导致了严重的兼容性问题。现有的高性能库如 DeepEP 依赖于 ConnectX 特有的 GPU 初始化 RDMA(IBGDA),在 EFA 上无法使用。NVSHMEM 虽然在 EFA 上 API 兼容,但在 MoE 路由等关键工作负载上性能严重下降。Mooncake 和 NIXL 等新库要么缺乏 EFA 支持,要么仍处于初步阶段。
TransferEngine:可移植 RDMA 通信的突破
核心设计洞察:在无序中建立秩序
Perplexity AI 的 TransferEngine 基于一个关键洞察:虽然不同 RDMA 硬件在消息排序保证上存在差异,但它们都提供可靠性保证。ConnectX 的 RC 传输可以配置为忽略排序,而 EFA 的 SRD 本质上是无序的。通过仅依赖可靠性而不假设任何排序,TransferEngine 能够在异构硬件上构建统一的抽象层。
这一设计决策使得 TransferEngine 成为首个真正支持跨供应商部署的 RDMA 通信库,同时在 NVIDIA ConnectX-7 和 AWS EFA 上都能达到接近硬件的峰值性能。
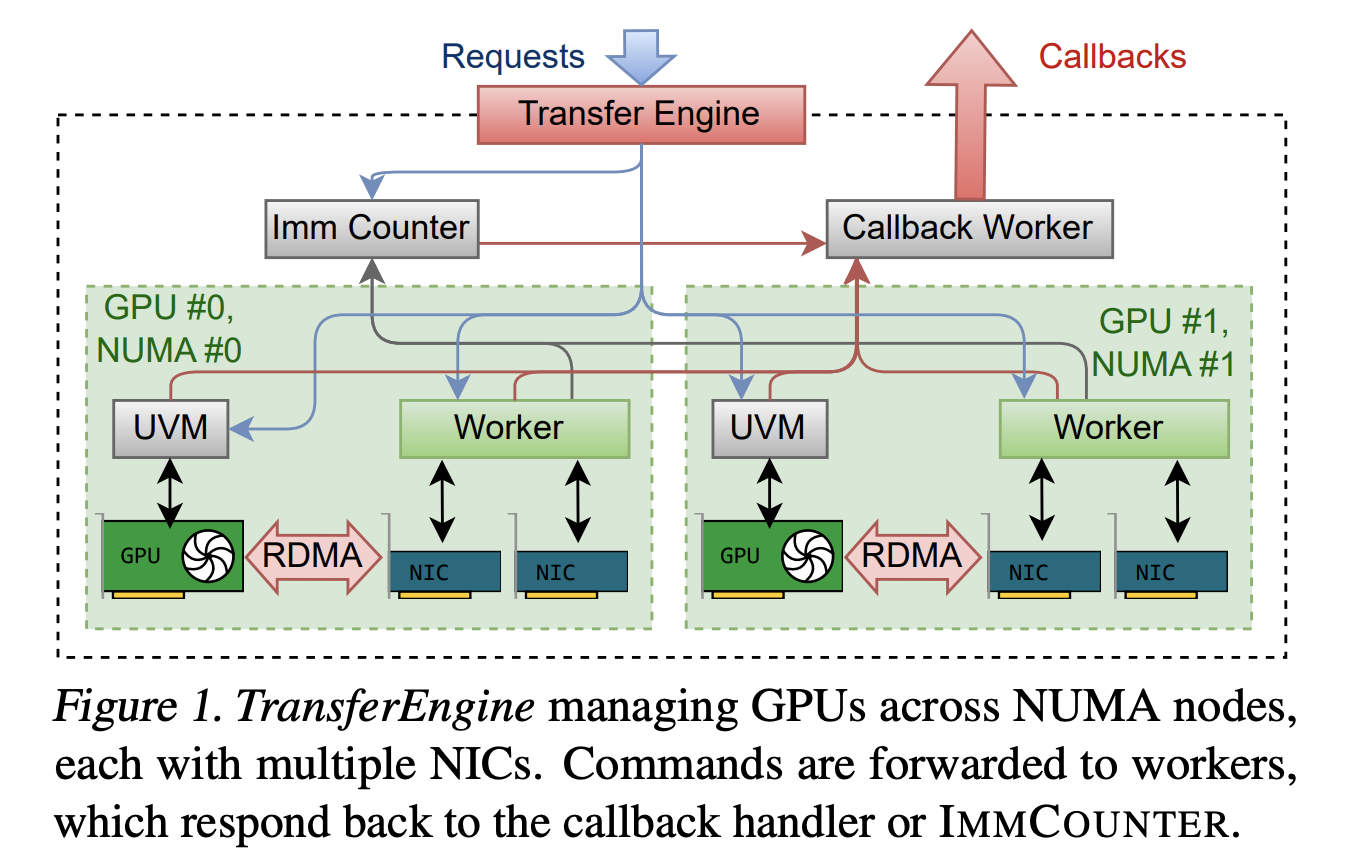
架构概览:统一抽象下的硬件多样性

TransferEngine 的架构精心设计以处理硬件多样性。其核心组件包括:
- ❀
DomainGroup:每个 GPU 对应一个 DomainGroup,协调所有关联的 RDMA NIC - ❀
Domain:管理单个 NIC,处理队列对管理、工作提交和完成轮询 - ❀
Worker 线程:每个 DomainGroup 一个工作线程,固定到相应的 NUMA 节点 CPU 核心
这种架构透明地处理了不同硬件平台的 NIC 数量差异。单个 ConnectX-7 NIC 提供 400 Gbps 带宽,而在 AWS p5 实例上,需要聚合四个 100 Gbps EFA NIC(或 p5en 实例上的两个 200 Gbps EFA NIC)才能达到相同的带宽。
核心 API 设计:简洁而强大
TransferEngine 通过精心设计的 Rust API 暴露其功能,主要操作包括:
- ❀
内存区域管理: reg_mr注册内存区域,返回可序列化的描述符 - ❀
双向发送/接收: submit_send和submit_recvs实现 RPC 式通信 - ❀
单向写入: submit_single_write和submit_paged_writes用于批量数据传输 - ❀
散点操作: submit_scatter向一组对等节点发送数据切片 - ❀
屏障同步: submit_barrier用于对等节点通知
这些 API 的一个关键特性是它们不提供跨操作的排序保证,这反映了底层硬件的现实情况。
ImmCounter:无序环境中的完成通知
传统 RDMA 实现严重依赖消息排序来进行完成通知,这在无序传输中不可行。TransferEngine 引入了创新的 ImmCounter 原语来解决这一挑战。
ImmCounter 跟踪每个即时值的计数器,这些计数器从底层设备的完成队列中检索到的事件递增。无论消息到达顺序如何,当特定即时值的计数达到预期值时,就会触发通知。这种方法确保了在无序网络环境中可靠的完成检测。
硬件特定优化:最大化性能
TransferEngine 针对不同硬件平台实现了专门优化:
AWS EFA 支持:
- ❀
使用 libfabric 实现,每个 NIC 管理一个结构域 - ❀
对所有传输强制执行有效描述符,即使对于仅含即时值的零大小写入也是如此 - ❀
采用工作请求模板,预填充和保留 libfabric 描述符中的公共字段
NVIDIA ConnectX-7 支持:
- ❀
通过 libibverbs 实现,每个对等节点使用 UD 队列对交换 RC 握手 - ❀
为每个对等节点创建 2 个 RC 队列对:一个用于双向操作,另一个用于单向操作 - ❀
启用 WR 链式操作,通过链接最多 4 个工作请求减少门铃 ringing 次数 - ❀
启用 IBV_ACCESS_RELAXED_ORDERING 以允许 NIC 和 GPU 内存之间的无序 PCIe 事务
生产系统案例研究
案例一:KvCache 传输实现分解推理
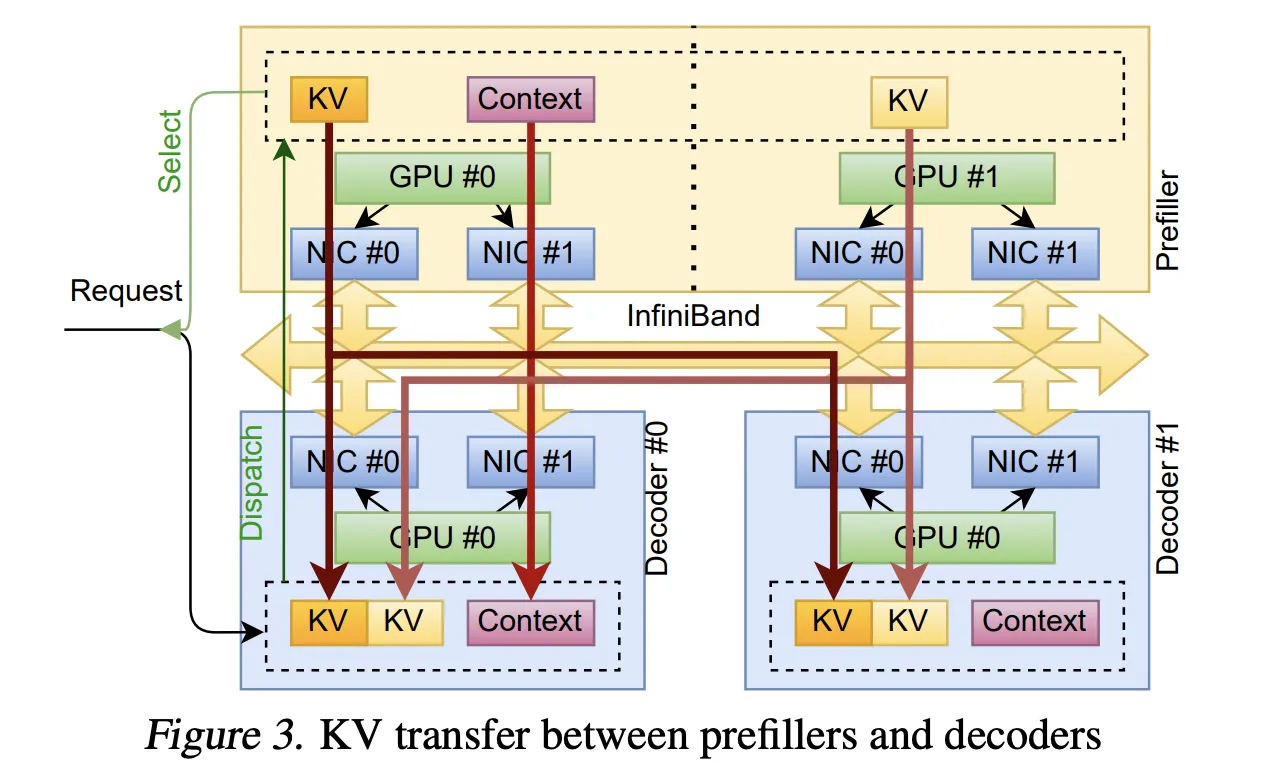
分解推理架构将预填充和解码阶段分离到不同的设备上,优化资源利用率。在这种模式下,预填充节点处理输入令牌并生成键值缓存(KvCache),然后将其传输到解码节点进行自回归令牌生成。
TransferEngine 通过以下方式实现高效的 KvCache 传输:
-
动态调度:全局调度器选择预填充节点和解码节点,解码节点预分配 KvCache 页面并通过
submit_send将请求分派到指定的预填充节点 -
分层流式传输:在分块预填充期间,模型在每个层的注意力输出投影后递增 UVM 观察器值。TransferEngine 检测到变化后,通过
submit_paged_writes启动该层的传输 -
完成通知:解码节点预先知道期望的传输数量,使用
expect_imm_count在传输完成时接收通知并开始解码 -
错误处理:通过心跳消息检测传输层故障,实现细粒度的取消和确认机制
这种方法避免了集体通信的固定成员关系和同步初始化开销,实现了真正的弹性扩展。
案例二:强化学习权重更新
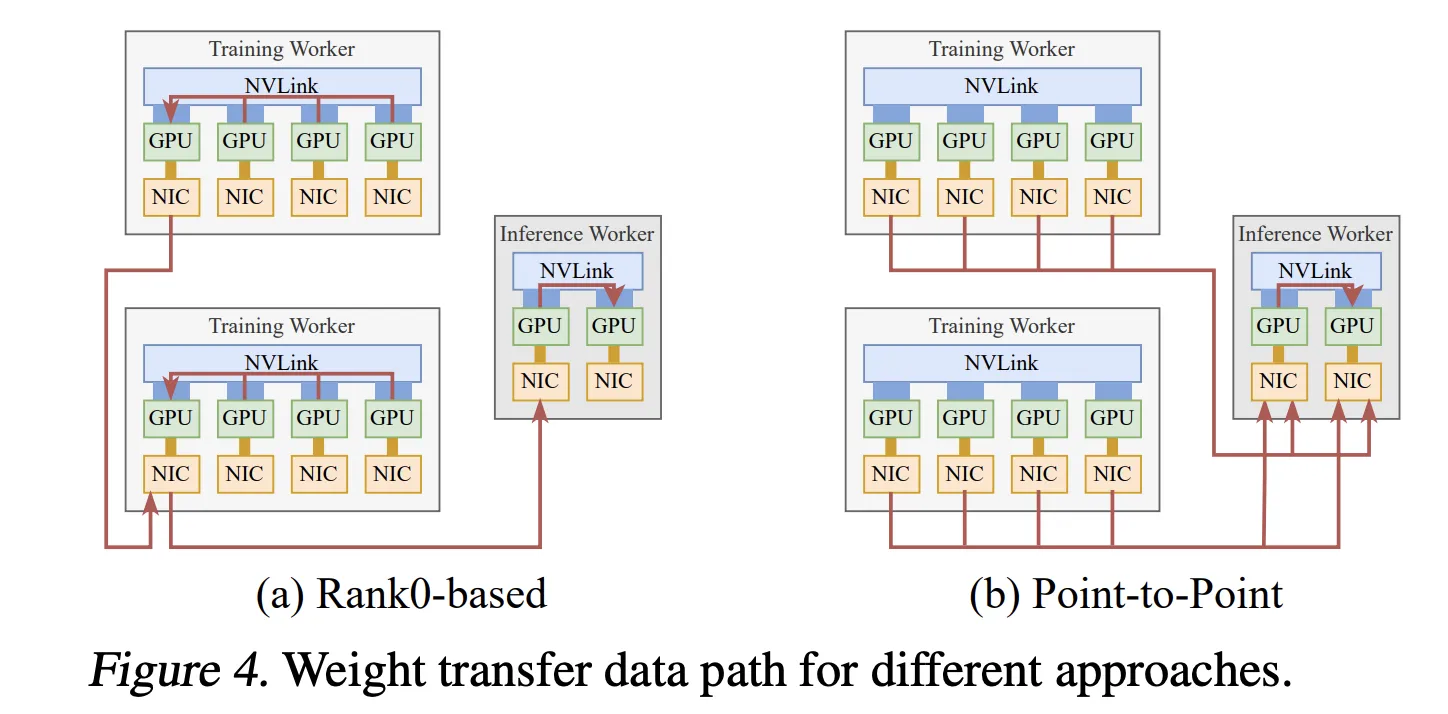
在异步强化学习微调中,训练和推理在独立的 GPU 上运行。传统的设计使用集体通信,将所有更新的参数收集到训练子组的 Rank0,然后广播到每个推理子组的 Rank0,这使训练 Rank0 的 NIC 成为瓶颈。
TransferEngine 的点对点方法彻底改变了这一范式:
-
直接权重传输:每个训练 GPU 使用单向 RDMA 写入直接将其参数分片发送到相应的推理 GPU,利用所有 NIC 的完整集群带宽
-
流水线执行:每个张量传输任务分为四个重叠阶段:
- ❀
阶段 1:如果 FSDP 将权重卸载到 CPU,则执行主机到设备的内存复制 - ❀
阶段 2:参数准备,包括使用 full_tensor()重构完整权重,应用投影融合,以及量化(如需要) - ❀
阶段 3:RDMA 传输,从本地 GPU 内存零拷贝写入到远程推理 GPU 内存 - ❀
阶段 4:全局屏障,在所有 full_tensor()调用完成后,通过以太网使用 GLOO 跨网格组同步
- ❀
-
内存管理:通过可配置的水位线控制临时 GPU 内存使用,避免内存不足错误
在生产环境中,这一方案实现了突破性的性能:对于 Kimi-K2(1T 参数)、DeepSeek V3(671B)和 Qwen3(235B)等模型,从 256 个训练 GPU(bf16)到 128 个推理 GPU(fp8)的参数更新仅需约 1.3 秒,比现有 RL 框架快 100 倍以上。
案例三:混合专家路由

混合专家模型的令牌路由需要高效的 all-to-all 通信模式。TransferEngine 实现的 MoE 内核在保持可移植性的同时,提供了最先进的性能:
架构特点:
- ❀
使用 NVLink 进行节点内通信,RDMA 进行节点间通信 - ❀
将调度和组合拆分为独立的发送和接收阶段,允许微批处理和通信计算重叠 - ❀
主机代理线程通过 GDRCopy 轮询 GPU 状态,并在源缓冲区准备就绪时调用 TransferEngine
调度优化:
-
路由交换:对等节点首先交换路由信息(每个专家的令牌计数),以确定连续接收缓冲区中的唯一范围 -
私有缓冲区:将少量令牌推测性地分派到私有缓冲区,隐藏设备到主机和网络延迟 -
批量传输:一旦确定路由,剩余令牌被散列到对等节点的共享接收缓冲区中
内存效率:
接收缓冲区的大小考虑所有发送到当前秩的令牌。假设有 N 个秩托管 E 个专家,每个调度 T 个令牌到 R 个专家,上限为 N·T·max(R, E/N)。发送者将写入打包到这样的连续缓冲区中,而不是依赖更大的每秩接收缓冲区。
性能评估
点对点通信性能

TransferEngine 在点对点通信性能上表现出色,在 NVIDIA ConnectX-7 和 AWS EFA 上均能达到接近硬件极限的吞吐量:
这些结果表明,TransferEngine 能够在两种主要硬件平台上实现高性能,同时保持抽象层的简洁性。
MoE 调度和组合性能
解码延迟(128 个令牌):
预填充延迟(4096 个令牌):
这些结果显示,在 ConnectX-7 上,TransferEngine 的 MoE 内核提供了与专门优化的 DeepEP 相当甚至更优的性能,同时在 EFA 上提供了首个可行的 MoE 实现。
私有缓冲区大小对性能的影响

私有缓冲区设计用于隐藏路由信息交换的延迟。评估显示,性能随着私有缓冲区大小的减小而下降:
- ❀
在节点内情况下,需要至少约 32 个令牌来隐藏跨两种 NIC 的路由交换延迟 - ❀
在节点间情况下,ConnectX-7 NIC 允许使用少至 24 个令牌,而 EFA NIC 在低于 32 个令牌时已经出现性能下降
这证明了延迟减少策略在实现高性能 MoE 路由中的重要性。
实际应用指南
系统要求
要使用 TransferEngine 和 pplx garden,您的系统需要满足以下要求:
- ❀
Linux Kernel 5.12 或更高(推荐,用于 DMA-BUF 支持) - ❀
CUDA 12.8 或更高版本 - ❀
libfabric、libibverbs 和 GDRCopy 库 - ❀
SYS_PTRACE和SYS_ADMINLinux 能力(用于pidfd_getfd) - ❀
支持 GPUDirect RDMA 的 RDMA 网络,每个 GPU 至少一个专用 RDMA NIC
Docker 开发环境
为方便开发,项目提供了 Docker 镜像:
# 构建镜像
docker build -t pplx-garden-dev - < docker/dev.Dockerfile
# 运行容器
./scripts/run-docker.sh
构建和安装
在容器内,可以按照以下步骤构建和安装 Python 包:
cd /app
export TORCH_CMAKE_PREFIX_PATH=$(python3 -c "import torch; print(torch.utils.cmake_prefix_path)")
python3 -m build --wheel
python3 -m pip install /app/dist/*.whl
运行基准测试
网络调试:
# 服务器端
/app/target/release/fabric-debug 0,1,2,3,4,5,6,7 2
# 客户端
/app/target/release/fabric-debug 0,1,2,3,4,5,6,7 2 <服务器地址>
All-to-All 基准测试:
# 设置环境变量
NUM_NODES=...
NODE_RANK=... # [0, NUM_NODES)
MASTER_IP=...
# 在所有节点上运行
cd /app
python3 -m benchmarks.bench_all_to_all \
--world-size $((NUM_NODES * 8)) --nets-per-gpu 2 --init-method=tcp://$MASTER_IP:29500 \
--node-rank=$NODE_RANK --nvlink=8
注意:如果只想使用 RDMA,移除 --nvlink 标志;根据 VM 实例类型相应设置 --nets-per-gpu。
与其他解决方案的比较
常见问题解答
TransferEngine 与传统的集体通信库(如 NCCL)有何不同?
集体通信库擅长结构化的数据交换模式,如张量或数据并行,但对新兴工作负载施加了不合适的约束:固定成员关系阻止动态扩展,同步初始化增加开销,统一的缓冲区大小即使对于稀疏模式也强制密集通信。TransferEngine 的点对点方法提供了灵活性,同时通过 RDMA 原语保持高性能。
TransferEngine 是否支持 GPU 直接初始化 RDMA?
当前,GPUDirect Async(IBGDA)仅在 ConnectX NIC 上受支持。TransferEngine 通过主机代理线程透明地处理这种情况,在 ConnectX 上使用 GPU 直接初始化(当可用时),在 EFA 上回退到主机代理方法。这种设计确保了跨硬件的可移植性,同时在不同平台上优化性能。
在混合硬件环境中部署 TransferEngine 有什么要求?
所有对等节点必须使用每个 GPU 相同数量的 NIC。这一限制允许 TransferEngine 在源和目标域之间具有完整的 NIC 知识,从而实现请求的分片或负载均衡。对于 EFA,这对于使用多个适配器实现全 400Gbps 带宽至关重要。
TransferEngine 如何处理网络可靠性和错误恢复?
TransferEngine 依赖于底层 RDMA 硬件的可靠性保证。对于应用级错误处理,它提供了检测传输层故障的心跳机制和细粒度的取消功能。在 KvCache 传输的案例中,解码器触发的取消必须由预填充节点明确确认,确保 KV 页面在远程写入可能覆盖它们之前不会被重用。
TransferEngine 的内存占用如何?
对于 MoE 路由,接收缓冲区的大小上限为 N·T·max(R, E/N),其中 N 是托管 E 个专家的秩数量,每个调度 T 个令牌到 R 个专家。通过重用调度接收缓冲区进行组合,以及使用私有缓冲区进行初始令牌传输,TransferEngine 最小化了内存开销,同时保持了低延迟。
结论
Perplexity AI 的 TransferEngine 和 pplx garden 的发布代表了 LLM 基础设施领域的重大进步。通过提供在异构 RDMA 硬件上工作的可移植点对点通信抽象,它使团队能够在现有的混合 GPU 集群上运行万亿参数模型,而无需昂贵的硬件升级或深度的供应商锁定。
三个生产系统——具有动态扩展的分解推理、1.3 秒更新的强化学习权重传输,以及跨 ConnectX-7 和 EFA 的可移植 MoE 路由——证明了该方法的有效性。通过在保持性能的同时避免供应商锁定,TransferEngine 为云原生 LLM 部署奠定了坚实的基础。
随着模型规模继续超越单个节点的能力,像 TransferEngine 这样提供高效、可移植通信的解决方案将变得越来越重要。其开源可用性(MIT 许可证)确保了这一技术进步可以被广泛采用,推动整个行业向前发展。
参考文献和资源
- ❀
研究论文:RDMA Point-to-Point Communication for LLM Systems - ❀
GitHub 仓库:pplx-garden - ❀
技术报告:Deepseek-v3 Technical Report - ❀
Kimi K2:Open Agentic Intelligence
引用信息:
@misc{pplx-rdma-p2p,
title={RDMA Point-to-Point Communication for LLM Systems},
author={Nandor Licker and Kevin Hu and Vladimir Zaytsev and Lequn Chen},
year={2025},
eprint={2510.27656},
archivePrefix={arXiv},
primaryClass={cs.DC},
url={https://arxiv.org/abs/2510.27656},
}
