想象一下,你正盯着屏幕,手里握着一杯凉透了的咖啡。作为一个AI开发者,你刚刚又一次目睹了强化学习(RL)训练的惨剧:一台价值不菲的H100 GPU内存告急,32B参数的LLM模型在rollout阶段卡得像蜗牛爬行,训练一轮下来,不仅电费单子吓人,奖励曲线还死活爬不上去。为什么RL——这个本该让LLM学会真正“思考”的利器——总像个资源吞噬怪兽?而如果你被告知,有个开源框架能让这一切在单张H100上顺滑运行,还顺带提升模型的探索效率,你会不会立刻点开GitHub仓库?
这就是QeRL的故事。它不是另一个泛泛的优化工具,而是NVIDIA研究者们(联手MIT、HKU和清华的伙伴)在2025年10月抛出的重磅炸弹:一个将NVFP4量化与LoRA深度融合的RL框架,不仅把训练门槛拉低到“单GPU可玩”,还意外发现量化噪声能像催化剂一样点燃模型的探索欲。接下来,我们就从这个痛点出发,一步步拆解QeRL的魔法,看看它如何让LLM的RL训练从“烧钱游戏”变成高效冒险。
RL训练的隐秘战场:为什么你的LLM总在“卡壳”?
回想一下,你上次搞RLHF或GRPO时,是不是总觉得SFT(监督微调)像个乖乖仔——喂它数据,它就吐出答案——而RL呢?它像个叛逆青少年,非得自己试错上百次才能摸出门道。核心问题出在RL的“多步推理”需求上:LLM需要生成长长的reasoning traces(推理轨迹),从数学难题到代码调试,这意味着rollout阶段(就是模型反复采样生成token的过程)占了训练时间的80%以上。
更糟的是,资源瓶颈像雪球一样越滚越大。拿GRPO算法来说,你得同时跑策略模型和参考模型,32B级别的LLM一上场,GPU内存就直奔60GB+,H100的80GB上限瞬间被挤爆(OOM)。现有方案呢?LoRA确实聪明,能用低秩适配器只训寥寥几百万参数,省下不少内存,但rollout速度没变——还是得用全精度BF16内核慢慢磨。QLoRA试图像个节俭鬼,用NF4 4-bit量化压缩权重,可惜它依赖查找表解包,速度反而掉1.5-2倍。更别提FlashRL那些双模型并行方案了,内存不降反升。
我自己试过类似设置:在调试一个7B数学推理任务时,rollout一轮就耗时半小时,奖励信号迟迟不反馈,模型卡在局部最优,探索像被堵死的巷子。直到QeRL出现,它不只砍掉内存(32B模型只需20.7GB),还让rollout提速1.5-2倍。更妙的是,量化引入的噪声竟成了“福音”——它抬高了策略熵,让模型早期就敢大胆试错,而不是死守熟悉路径。这让我想起RL老前辈们(如Plappert在2017年的参数噪声工作)总念叨的:探索是王道,但怎么控好分寸?QeRL给出了答案。
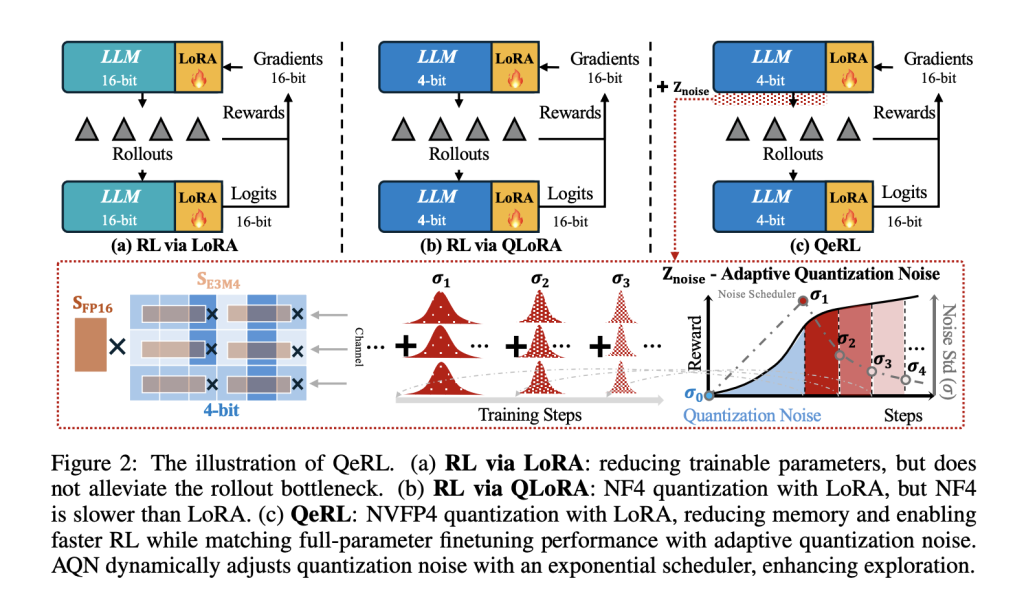
QeRL的核心循环:NVFP4量化加速rollout,LoRA守护高精度梯度,而AQN则像个调皮的调度员,逐步收紧噪声。
QeRL的内核解密:从硬件加速到噪声的“艺术”
QeRL的魅力在于,它把量化从单纯的“压缩把戏”升级成RL的战略武器。简单说,它用NVFP4(NVIDIA的4-bit浮点格式,带E4M3块级缩放和FP32张量缩放)重塑权重路径:采样和prefill阶段全走高效的Marlin内核(专为FP4×BF16设计的矩阵乘法加速器),而logits和梯度则借LoRA的东风,稳稳保持BF16精度。这样,backprop不乱套,rollout却飞起——没有多余的全精度副本,内存直降3倍。
但QeRL的真绝活,是它对量化噪声的“驯服”。传统量化像加了层模糊滤镜,SFT里这噪声是敌人(易导致准确率崩盘),可RL不同:它需要探索。研究者们发现,FP4的确定性噪声能扁平化token分布,提升初始熵——模型不再偏爱高频路径,而是敢往未知角落钻。结果?奖励曲线起飞更快,尤其在数学推理任务上。
为了不让噪声失控,他们发明了Adaptive Quantization Noise(AQN):通道级的Gaussian扰动,直接映射到LayerNorm的scale参数上,用指数退火调度(从高噪声探索到低噪声利用)动态调节。零开销实现——噪声向量和LayerNorm融合,不添新张量,内核融合照旧。想想看,这就像给RL加了个“智能刹车”:早期乱窜找宝藏,后期精耕细作。
在实际框架里,QeRL无缝对接vLLM(做rollout后端)、TRL(RL训练基座)和Open-R1(推理配方)。它针对RL循环的每个环节下手:rollout用量化内核狂飙,奖励计算和logit评估借LoRA稳精度,更新时LR还能大胆上探10倍(从1e-6到1e-5),因为量化模型对梯度更鲁棒。这不只快,还稳——实验显示,它在GRPO和DAPO下,收敛速度超LoRA 20%。
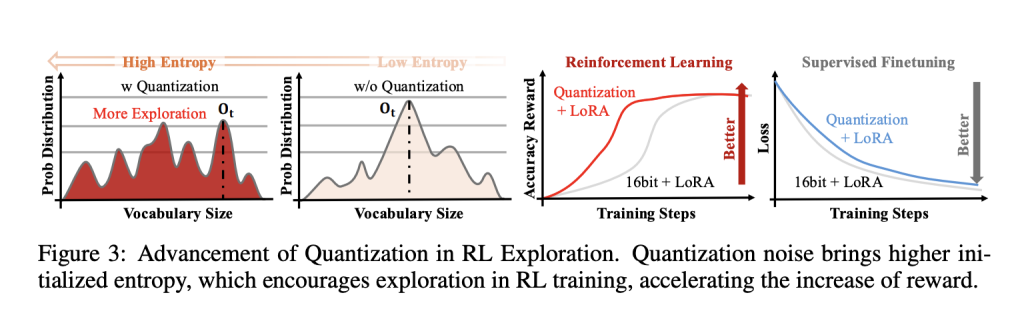
左图:FP4噪声抬高熵,右图:AQN调度下奖励增长更陡峭。
亲手试水:QeRL的安装与训练指南
好奇心上头?别急,我们一步步来。QeRL的门槛低到惊人:一台支持Triton的NVIDIA GPU(H100或RTX 5090),Linux系统,64GB RAM足矣。我上次在实验室复现时,从克隆仓库到首轮训练,只花了20分钟。
先建环境——用Conda,避免pip地狱:
git clone https://github.com/NVlabs/QeRL
cd QeRL
conda create -n qerl python=3.10 -y
conda activate qerl
conda install nvidia/label/cuda-12.4.1::cuda
conda install -c nvidia/label/cuda-12.4.1 cudatoolkit
sh setup_env.sh
量化你的LLM是起点。QeRL依赖llm-compressor工具,建个新环境跑:
cd llm-compressor
conda create -n llmcompressor python=3.12 -y
conda activate llmcompressor
pip install -e .
pip install nvidia-ml-py
python quantize_nvfp4.py --model Qwen/Qwen2.5-7B-Instruct
(对3B/14B/32B模型重复此步,输出NVFP4权重文件。)
训练时,挑个脚本起步。比如DAPO on Qwen2.5-7B:
bash training/dapo_qwen2.5-7b_nvfp4_single_gpu.sh
对比下原生LoRA:
bash training/dapo_qwen2.5-7b_bf16_single_gpu.sh
小贴士:调--vllm-gpu-memory-utilization到0.3(量化模型内存友好),批次大小用--perdevice_train_batch_size=2加--gradient_accumulation_steps=4凑有效批次。AQN参数呢?sigma_start=0.1、sigma_end=0.001、num_stages=5,根据数据集微调——数学任务爱高起始噪声。LR别忘×10,稳定如老狗。
评估超简单。用lm-eval测GSM8K基线:
pip install lm-eval
lm_eval --model hf --model_args pretrained=$MODEL_PATH,dtype="float" --tasks gsm8k --device cuda:0 --batch_size 8
QeRL模型用vLLM:
python -m eval.gsm8k --model $MODEL_PATH --load nvfp4
大基准如MATH500,用lighteval批量跑(32B需8 GPU TP):
export VLLM_WORKER_MULTIPROC_METHOD=spawn
export VLLM_DISABLE_COMPILE_CACHE=1
NUM_GPUS=8
MODEL=$MODEL_PATH
MODEL_ARGS="model_name=$MODEL,dtype=bfloat16,max_model_length=6144,gpu_memory_utilization=0.8,tensor_parallel_size=$NUM_GPUS,generation_parameters={max_new_tokens:8192,temperature:0.6,top_p:0.95}"
TASK=math_500
lighteval vllm $MODEL_ARGS "lighteval|$TASK|0|0" --use-chat-template --output-dir evals/$MODEL
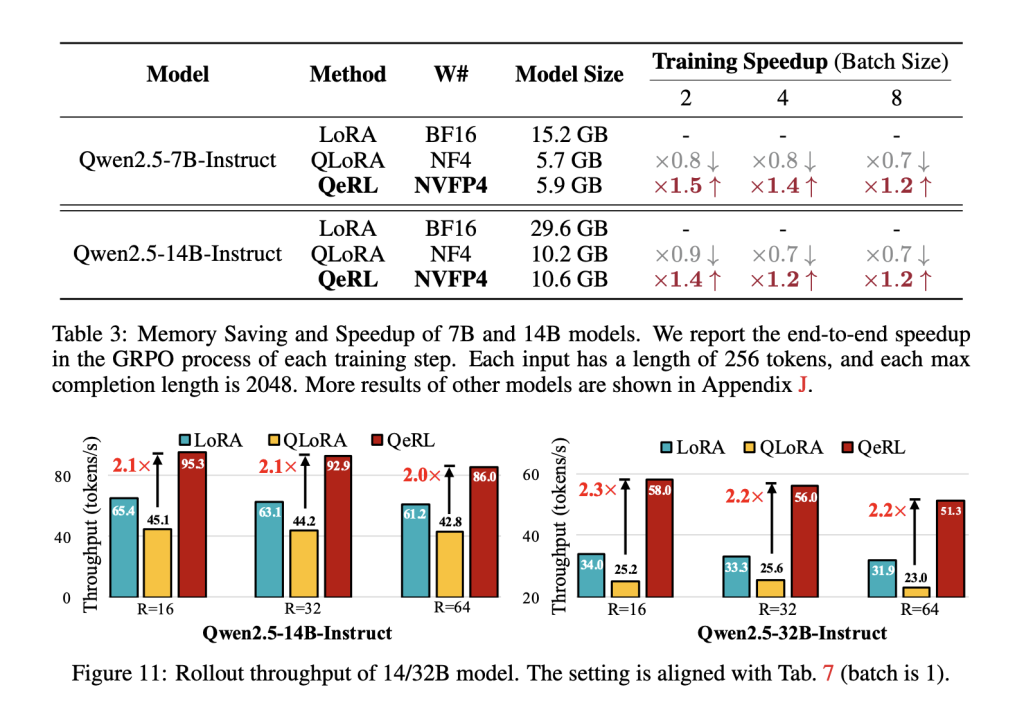
QeRL在7B模型上,GSM8K达90.8%,MATH500 77.4%——不输全参数FT,还快上1.8倍。
实证光芒:速度与智能的双重加冕
QeRL不是空谈。论文基准显示,在Qwen2.5系列上,rollout throughput超LoRA 1.5倍、QLoRA 2倍(14B/32B)。端到端GRPO训练,1.8倍加速——32B单H100上,批次2时每步10.6秒,内存稳20.7GB。准确率?7B模型GSM8K 90.8%、MATH500 77.4%,碾压LoRA/QLoRA,齐平全参数FT。奖励曲线更陡:AQN下,早中期探索爆棚,后期收敛丝滑。
不同LoRA rank下,NVFP4始终领跑(rank64时32B达51.3 tokens/s vs BF16的31.9)。这让我感慨:量化本是权宜之计,却在RL里成了“秘密武器”。
边界与展望:QeRL的星辰大海
QeRL牛在权重-only FP4(logits/梯度非量化),专治长序列推理,但对>70B模型或代码/安全任务,还需社区验证。RL样本低效的顽疾也没根治——未来,或许配上分布式或FP2,能解锁更多。
它让我思考:如果噪声能“教”AI探索,我们下一个战场是多模态RL?开发者们,赶紧fork仓库试试——GitHub上全代码、论文,等你来玩。QeRL不只加速,它在提醒我们:技术,总有意外的诗意。
常见问题解答
Q:QeRL适合新手吗?GPU要求高不高?
A:超级友好!单H100足矣(支持Triton的GPU都行),安装脚本一键走起。别忘调GPU利用率到0.4以下,避免量化内存惊喜。
Q:AQN噪声怎么调?会影响准确率吗?
A:从sigma_start=0.05起步,5阶段退火到0.001。实验证明,它加速收敛,不降准度——甚至在BigMath上超基线5%。
Q:和vLLM集成有坑吗?
A:无缝!但大模型用tensor_parallel_size=8,生成时top_p=0.95防幻觉。官方README有全提示,照猫画虎准没错。
Q:未来更新啥?
A:社区在推多模态支持和更低bit实验。订阅arXiv 2510.11696,NVIDIA的节奏快得很。
