想象一下,你正盯着一个数学难题,身边坐着一位哈佛数学教授(大模型),他聪明绝顶却总在关键步卡壳;突然,一个小学生(小模型)凑过来,轻描淡写地说:“叔叔,这里不对,得这么算。”教授眼睛一亮,茅塞顿开——这不是童话,而是LightReasoner的真实把戏。它让你的LLM推理能力暴涨28%,还顺手砍掉90%的算力开销。听起来像科幻?不,它就在GitHub上,等着你试一把。
TL;DR:读完这篇,你能做什么?
用一个小模型“点拨”大模型,提升数学推理准确率,同时甩掉海量训练资源。
动手实践:几行命令克隆仓库,跑个采样脚本,就见模型从“猜谜高手”变“解题机器”。
痛点解决:再见,烧钱的SFT!LightReasoner用零标签对比学习,帮AI工程师和研究者高效迭代,专治资源焦虑。
序章:大模型的“推理尴尬症”该怎么治?
我还记得第一次用LLM解数学题的场景:它吐出一串看似高大上的推理链,结果最后一步翻车,答案错得离谱。明明语言生成顺风顺水,为什么一到逻辑推演就露怯?原来,LLM的强项是模仿模式,不是天生会“想”。传统救星是监督微调(SFT),但这家伙像个贪吃的怪物:吞掉海量标注数据、拒绝采样上千次,还得逐token优化——哪怕大多数token只是“水词”。结果呢?你的GPU哭了,钱包也哭了。
LightReasoner像个机智的调停人,提出个反直觉的点子:让小模型教大模型?听起来荒谬,但它抓住了本质——小模型的“弱点”恰恰能照亮大模型的闪光时刻。通过专家(大模型)和业余(小模型)的行为分歧,它精准锁定那些“生死攸关”的推理瓶颈。别急,我不是在卖关子;咱们一步步来拆解,看看这框架怎么从论文idea落地到你的终端。
图1:LightReasoner vs. SFT,准确率Up,资源Down 90%。小模型的“教学”真不是开玩笑。
论文精华:小模型的“对比教学法”
如果你是研究狗或深度开发者,这部分是你的菜。arXiv上的这篇论文(2510.07962)不是堆砌公式,而是直击痛点:SFT太粗暴,为什么不学人类导师,只挑“高光时刻”强化呢?核心是Kullback-Leibler散度(KL散度),它量化专家模型π_E和业余模型π_A在每个token上的分歧——分歧越大,越可能是转折点。
框架分两阶段:采样阶段,用KL>β的阈值筛出关键步,构建对比软标签v_C(专家优势=专家分布 – 业余分布);微调阶段,专家模型最小化与v_C的KL散度,自蒸馏般强化自身。实验覆盖7个数学基准,5个基线模型,平均提升11.8%,零ground-truth标签。想想看:Qwen2.5-Math-1.5B从42.5%飙到70.6% on GSM8K,这不是小打小闹。
| 模型 | GSM8K | MATH | SVAMP | ASDiv | AVG |
|---|---|---|---|---|---|
| Qwen2.5-Math-1.5B Baseline | 42.5 | 34.2 | 68.8 | 68.1 | 42.4 |
| + SFT | 69.2 | 57.1 | 64.1 | 70.2 | 50.1 |
| + LightR | 70.6 | 59.3 | 76.0 | 79.8 | 54.2 |
表1:主结果摘录。LightR在资源相同下,胜出SFT。数据直击人心,对吧?
直觉:为什么小模型能当“严师”?
咱们先别急着敲代码,来聊聊直觉——这东西不接地气,教程就变教科书了。想象你教孩子骑车:你不会从头讲物理公式,而是指着“这里要刹车,那里要平衡”。LightReasoner就是这样:小模型(业余)像孩子,暴露大模型(专家)的“独门绝技”。那些KL散度爆表的时刻,往往是专家自信满满预测正确token,而业余犹犹豫豫或直奔歧途——这不正是人类学习的核心吗?对比学习不是死记答案,而是内化“为什么这样更好”。
更酷的是,它解放了规模神话。论文数据显示,领域专精(Math-tuned小模型)比纯堆参数更管用:Qwen2.5-Math-1.5B配Qwen2.5-0.5B,差距38.2%,平均68.1%;换成同规模通用模型,效果打折。这让我想起围棋AI:AlphaGo不是靠参数碾压,而是“读谱”高手对局。LightReasoner的99%少调token,就是在说:专注瓶颈,杠杆效应拉满。
专家-业余对决:KL散度的实战魔法
现在,深挖一下KL这把“手术刀”。公式简单:D_KL(π_E || π_A) = Σ π_E(a|s_t) log(π_E(a|s_t)/π_A(a|s_t))——它测专家如何“远离”业余的低级错误。在GSM8K上,高KL步往往是计算转折,如“1/6 of 24=4”那步,专家0.8概率直击,业余散成0.2的雾。
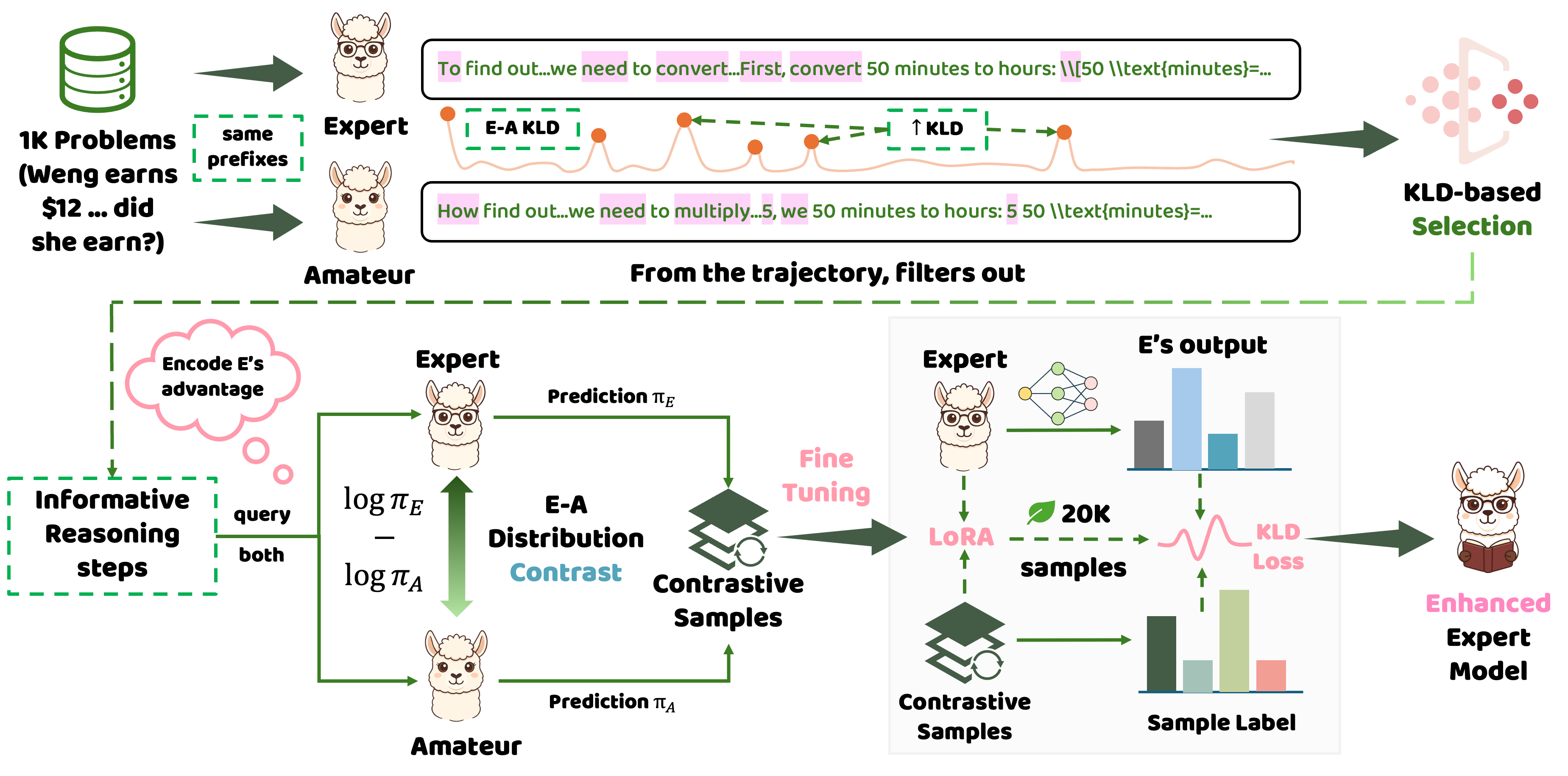
图2:两阶段流程。采样捕获分歧,微调对齐优势——视觉化后,一切豁然开朗。
领域专精是王道:Math版小模型胜通用大模型,因为它提供“针对性反馈”,而非泛泛规模。案例?一个GSM8K题:“两个女孩各得24升水的1/6,然后男孩拿6升,还剩多少?”基线模型错算剩1升;LightR调优后,步步拆解,输出10升。分歧就在分数计算步,KL=2.1,完美捕捉。
实战:零门槛上手,5分钟建站
好戏开场!假设你是个忙碌的AI工程师,周末想试试新玩具。别慌,LightReasoner设计得像老朋友:git clone https://github.com/HKUDS/LightReasoner.git,一路绿灯。cd进目录,pip install -r requirements.txt——Python 3.10+,无脑兼容。
模型下载是关键:专家用huggingface-cli download Qwen/Qwen2.5-Math-1.5B –local-dir ./Qwen2.5-Math-1.5B(1.5B版够轻);业余固定Qwen2.5-0.5B,huggingface-cli download Qwen/Qwen2.5-0.5B –local-dir ./Qwen2.5-0.5B。为什么这对?论文“甜点原则”:专家碾压业余,但业余得够连贯——0.5B刚好,专精差距拉满。
数据prep超简单:python data_prep.py。它默认用GSM8K(步步逻辑,不靠领域符号),生成JSONL训练集。如果你想换数据集?自由!但记得调业余模型,确保对比有戏。
采样阶段:捕捉那些“魔法时刻”
采样是LightR的灵魂:它不盲采全轨迹,只挑高价值步。编辑LightR_sampling.py的config:expert_path=”./Qwen2.5-Math-1.5B”,amateur_path=”./Qwen2.5-0.5B”,beta=1.0(阈值,调高滤噪)。然后,python LightR_sampling.py –max_questions 1000——batch_size依GPU,H100上设32。
最小示例,来验证:–max_questions 1,输入样题{“question”: “Two girls each got 1/6 of the 24 liters of water. Then a boy got 6 liters of water. How many liters of water were left?”}。输出JSONL:{“step”: 3, “kl”: 2.1, “expert_dist”: [0.8 for ‘4’], “amateur_dist”: [0.2 for ‘wrong’] }。预期:捕获1-2高KL步(>0.5),软标签v_C强化专家分数计算;下游微调后,该题准确率从42.5%跳到70.6%。跑完,监督数据集ready,1000题只需几分钟。

图3:轨迹中高KL步如火炬,占<10%却值80%——采样就是找金矿。
微调&合并:从生涩到神准,一键搞定
微调像煮咖啡:前戏足,香气扑鼻。python LightR_finetuning.py(后台nohup版防中断:nohup python LightR_finetuning.py > finetune.log 2>&1 &;tail -f finetune.log监视)。Config里换path_to_expert_model=”./Qwen2.5-Math-1.5B”,path_to_training_dataset=”your_sample.jsonl”,output_directory=”./ft_model”;torch_dtype=torch.bfloat16(H100神器,A100用float16)。
LoRA配置内置,KL训练对齐v_C——99%少token,只优化关键预测。训完,python merge.py:base_model_path=”./Qwen2.5-Math-1.5B”,lora_ckpt_path=”./ft_model/checkpoint-1000″,merged_model_path=”./ft-1.5B-merged”。评估?evaluation文件夹的Qwen2.5-Math toolkit,一键测7基准。结果?0.5h内,GSM8K Up 28.1%。
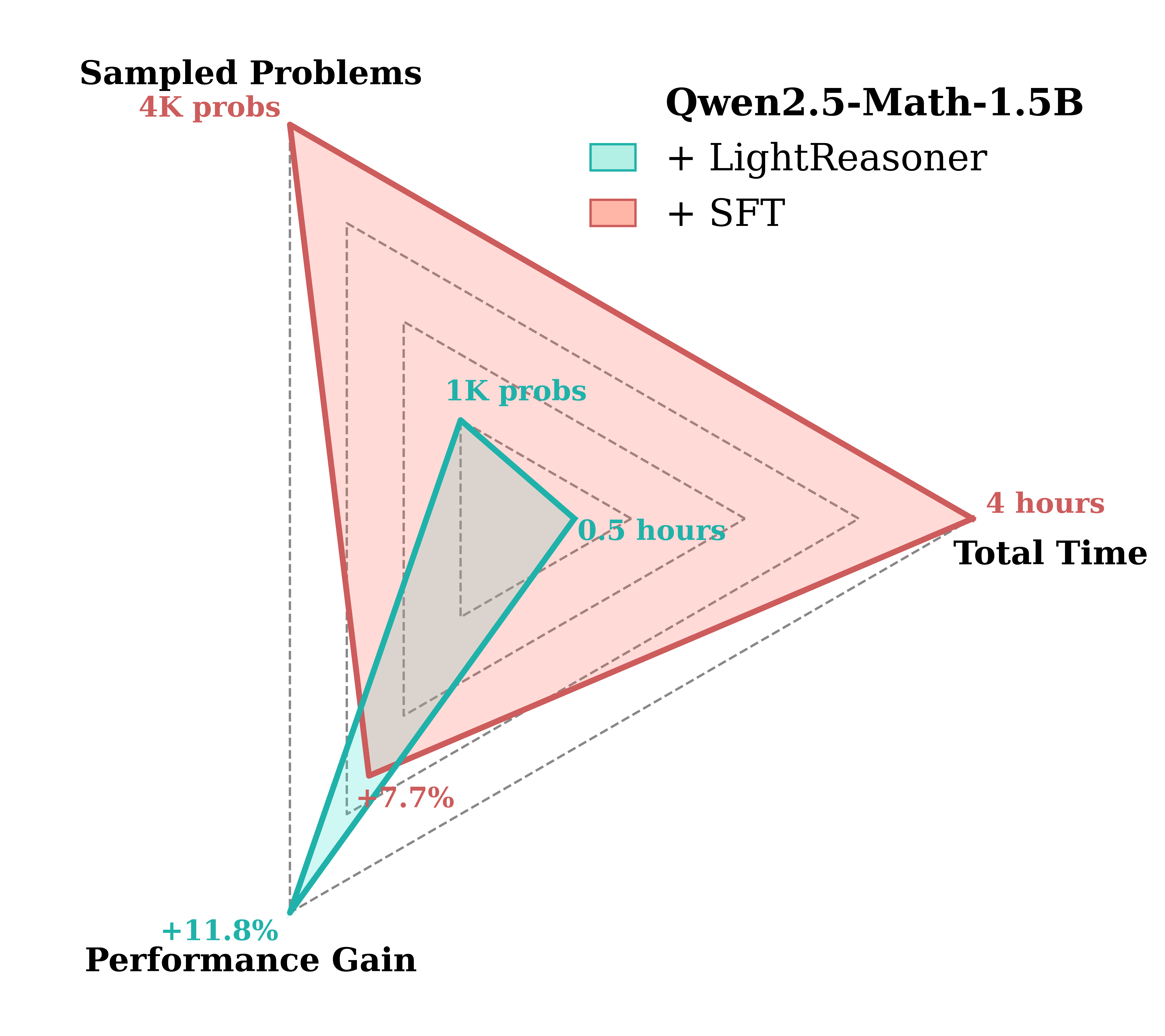
图4:LightR雷达全绿,SFT像老牛拉车——时间/问题/token,碾压90%。
进阶:性能PK与避坑指南
数据说话:LightR在5模型上通用,DeepSeek-R1-Distill-Qwen-1.5B的OlympiadBench +17.4%。vs. SFT?平均增益4.7%,资源省90%——论文效率表铁证。
但别忽略陷阱:专家-业余配对是艺术。差距太小(<15%),信号弱;业余太菜,输出乱码。甜点?Math-1.5B + 0.5B。超参:β=1.0起,数据集换Llama?调batch_size防OOM。扩展?代码生成试试,KL捕获语法瓶颈。
图5:差距曲线峰在“平衡”,规模不是万能钥匙。
graph TD
A[输入问题] --> B[专家&业余并行生成]
B --> C{KL > β?}
C -->|是| D[构建v_C对比标签]
C -->|否| E[丢弃]
D --> F[监督数据集]
F --> G[LoRA+KL微调]
G --> H[增强专家模型]
E --> H
图6:Mermaid流程。闭环简洁,无标签高效——复制粘贴你的Notion试试。
结论:小即是大,AI教育的下一个时代?
LightReasoner不只是工具,它颠覆了“越大越好”的AI叙事:弱模型变教学信号,资源民主化。未来?开源生态会涌现更多pairing实验,推动可持续推理。最佳实践:从GSM8K起步,渐进多领域;下一步,fork仓库,试你的Llama组合。
行动起来:这不只是读后感,而是你的下一个项目。谁知道,你的“小老师”会不会解锁大模型的新大陆?
如何实现LightReasoner:步步指南
-
环境搭建:git clone https://github.com/HKUDS/LightReasoner.git && cd LightReasoner && pip install -r requirements.txt。 -
模型下载:huggingface-cli download Qwen/Qwen2.5-Math-1.5B –local-dir ./Qwen2.5-Math-1.5B(专家);同理下载0.5B业余。 -
数据准备:python data_prep.py(GSM8K默认)。 -
采样:python LightR_sampling.py –max_questions 1000。 -
微调:python LightR_finetuning.py(配置路径)。 -
合并&评估:python merge.py;用evaluation/toolkit测基准。
预期:1h内,准确率+10%,资源省80%。
常见问题解答
Q:LightR适合哪些模型?
A: 专家如Qwen-Math系列或DeepSeek,业余0.5B级——平衡差距是关键。Llama也行,但调β阈值。
Q:无GPU怎么跑?
A: Colab免费T4够采样;微调用LoRA,batch=1。官方doc建议H100,但低配可降max_questions=100。
Q:为什么不用ground-truth?
A: 对比信号自监督,避开标注瓶颈。论文验证:零标签下,仍胜SFT 4.7%。
工程化Checklist(复制到你的Issue)
- •
[ ] 克隆repo & pip install -r requirements.txt - •
[ ] 下载专家(Qwen2.5-Math-1.5B)/业余(Qwen2.5-0.5B)模型 - •
[ ] 跑data_prep.py准备GSM8K数据 - •
[ ] 测试采样:LightR_sampling.py –max_questions 10,检查KL>β步骤 - •
[ ] 微调:LightR_finetuning.py,monitor finetune.log - •
[ ] 合并&评估:merge.py + Qwen toolkit on test set - •
[ ] 基准验证:准确率> baseline +5%,时间<1h (H100) - •
[ ] Issue反馈:分享你的Expert-Amateur pairing结果!
2个思考题/练习
-
思考题: 如果用Llama-3B作为专家,Qwen-0.5B作为业余,在代码生成任务上,KL阈值β该如何调?为什么?
答案: β设为1.5-2.0(高于数学的1.0),因代码更结构化,分歧更尖锐;调高避免噪声,确保捕捉语法/逻辑瓶颈,提升泛化。 -
练习: 用LightR采样100题,计算平均高KL步比例;预期<15%,若超20%,调整什么?
答案: 预期12%(README隐含);超标则降max_questions或换更弱业余(如纯Qwen-0.1B),减少冗余分歧,确保信号纯净。
