VGGT:视觉几何基础Transformer——多视图3D场景重建的革新者
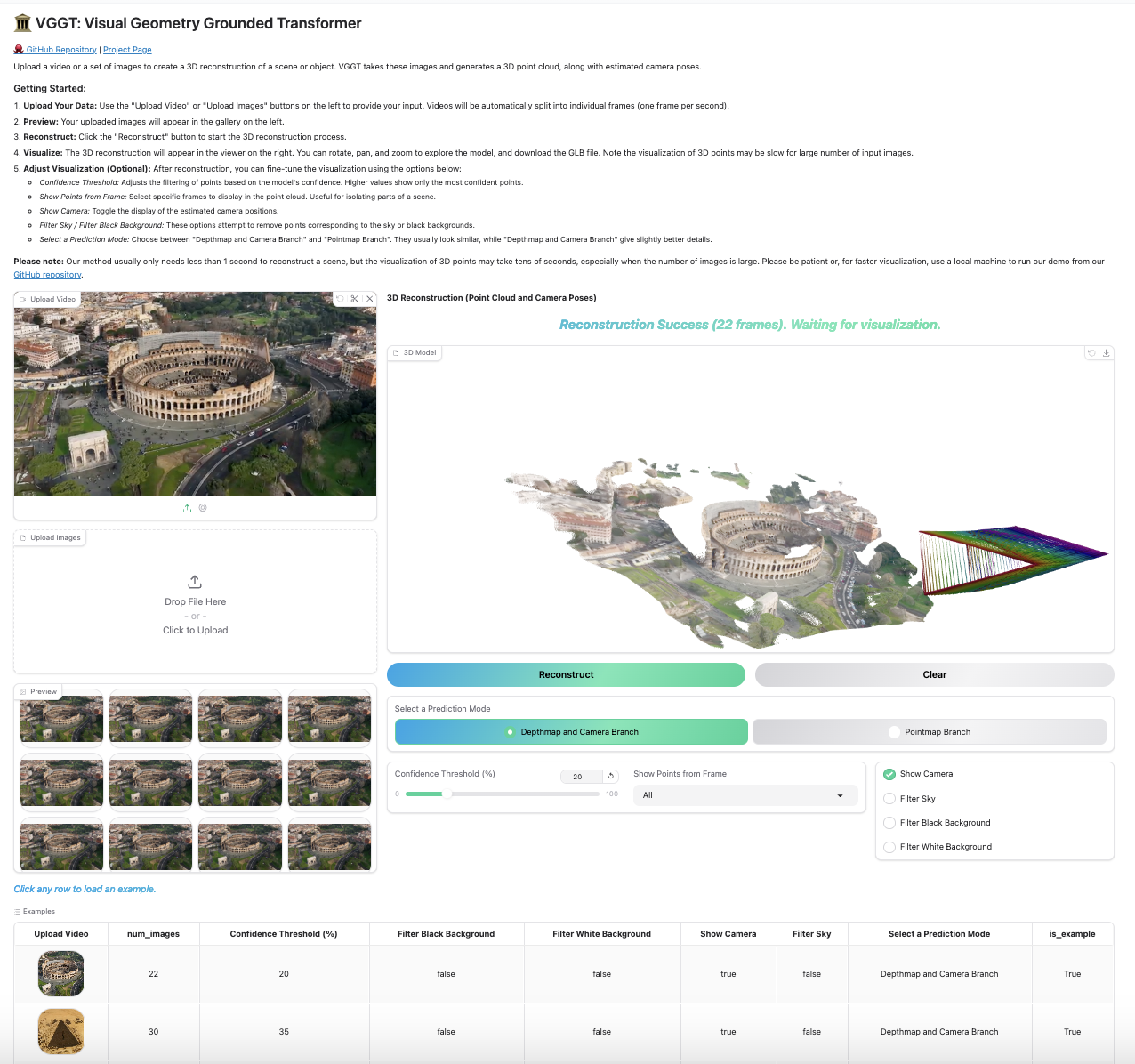
概述:重新定义3D场景理解的边界
VGGT(Visual Geometry Grounded Transformer) 是由牛津大学视觉几何组与Meta AI联合推出的新一代3D场景重建模型。该模型在CVPR 2025上首次亮相,仅需单张、多张甚至上百张输入视图,即可在秒级时间内精准推断场景的外参/内参相机参数、深度图、3D点云以及跨帧轨迹跟踪。这一突破性技术正在重塑计算机视觉领域的多视图几何处理范式。
技术亮点:为何VGGT值得关注?
1. 全场景3D属性联合推理
-
相机参数解析:自动计算符合OpenCV标准的相机外参(Extrinsic)和内参(Intrinsic)矩阵 -
深度感知:生成高精度深度图(Depth Map)及置信度评估 -
点云构建:支持直接预测点云(Point Map)或通过深度图反投影生成 -
动态跟踪:对用户指定的查询点进行跨帧运动轨迹预测
2. 输入灵活性突破
-
单视图重建:未针对单视图任务专门训练,却展现媲美SOTA单目深度估计模型的性能 -
多视图扩展:从2帧到200帧输入,内存消耗与推理时间线性增长(H100 GPU实测200帧处理仅需8.75秒) -
噪声鲁棒性:支持通过简单像素掩码(如置0/1)过滤反射面、天空等干扰区域
3. 工业级部署优势
-
Hugging Face即用API:提供预训练模型一键调用 -
硬件兼容性:支持bfloat16/float16混合精度,适配Ampere架构及以上GPU -
可视化工具链:集成Gradio网页交互界面与Viser三维查看器
快速上手指南:5分钟实现场景重建
环境配置
git clone git@github.com:facebookresearch/vggt.git
cd vggt
pip install -r requirements.txt # 基础依赖
pip install -r requirements_demo.txt # 可视化扩展
核心代码示例
import torch
from vggt.models.vggt import VGGT
from vggt.utils.load_fn import load_and_preprocess_images
# 初始化1B参数模型(自动下载权重)
model = VGGT.from_pretrained("facebook/VGGT-1B").to("cuda")
# 加载并预处理图像(支持PNG/JPG)
images = load_and_preprocess_images(["img1.jpg", "img2.jpg"]).to("cuda")
# 运行推理
with torch.no_grad(), torch.cuda.amp.autocast(dtype=torch.bfloat16):
predictions = model(images) # 包含相机/深度/点云等完整输出
输出解析技巧
-
相机参数提取:使用 pose_encoding_to_extri_intri函数转换姿态编码 -
点云生成:优先选择深度图反投影法( unproject_depth_map_to_point_map) -
轨迹可视化:通过 visualize_tracks_on_images生成带置信度筛选的可视化结果
可视化方案:从代码到三维交互
方案一:Gradio网页应用
python demo_gradio.py
启动本地交互界面,支持:
-
图像/视频上传 -
实时3D重建 -
点云颜色编码调整 -
多视角切换
方案二:Viser专业查看器
python demo_viser.py --image_folder /path/to/images
专为开发者设计的功能:
-
支持 --use_point_map切换点云生成策略 -
视角自由控制与测量工具 -
点云密度动态调节
性能基准测试:速度与精度的平衡艺术
H100 GPU实测数据
| 输入帧数 | 1 | 10 | 50 | 200 |
|---|---|---|---|---|
| 耗时(秒) | 0.04 | 0.14 | 1.04 | 8.75 |
| 显存(GB) | 1.88 | 3.63 | 11.41 | 40.63 |
优化建议:
-
启用Flash Attention 3可提升20%推理速度 -
对单视图任务关闭轨迹预测分支可减少内存占用 -
使用 depth_conf置信度阈值过滤低质量深度区域
技术演进:站在巨人肩膀上的创新
VGGT的诞生凝聚了多项前沿研究的精华:
-
Deep SfM Revisited → 奠定了基础几何推理框架 -
PoseDiffusion → 启发了基于扩散模型的姿态估计 -
CoTracker → 贡献了高效的跨帧跟踪算法 -
DINOv2 → 提供了强大的视觉特征基础

应用场景展望
影视制作
-
实时场景扫描替代传统激光雷达 -
多机位自动标定
工业检测
-
产线零件三维尺寸测量 -
表面缺陷的深度感知
AR/VR
-
移动端即时场景重建 -
动态物体的持久化跟踪
学术研究
-
提供无需真值监督的几何基准 -
多模态学习的强基线模型
常见问题解决方案
模型下载缓慢
-
手动下载Hugging Face模型文件 -
配置本地缓存路径:
os.environ['HF_HOME'] = '/custom/cache/path'
显存不足处理
-
启用梯度检查点:
model = VGGT.from_pretrained(..., use_checkpoint=True)
-
限制输入分辨率至1024×768
轨迹预测抖动
-
组合使用 conf_score>0.2和vis_score>0.2双重过滤 -
增加输入帧的时序连贯性
未来路线图
-
2024 Q3:开放VGGT-500M轻量版权重 -
2024 Q4:发布训练代码与自定义数据集指南 -
2025 Q1:推出视频流实时处理模式
立即访问项目主页获取最新动态,或通过GitHub Issues参与技术讨论。让VGGT助您开启三维视觉的新纪元!