

Audio-Driven Cinematic Video Generation: How WAN-S2V Transforms Movie Production
Introduction: The Challenge of Film-Quality Animation
Creating realistic character animations for films and TV shows has always been a major hurdle. While current AI models can handle simple talking heads or basic movements, complex scenes with dynamic camera work and character interactions remain challenging. This is where WAN-S2V steps in – a breakthrough model designed specifically for generating high-quality cinematic videos using audio as the driving force.
Imagine watching a movie where characters move naturally with the dialogue, cameras sweep dramatically across scenes, and every gesture feels intentional. WAN-S2V makes this possible by combining text prompts for overall scene control with audio inputs for precise character actions.
Understanding the Technical Foundation
2.1 How Current Models Fall Short
Traditional audio-driven animation systems primarily focus on:
-
Single-character scenarios -
Limited motion ranges (mostly facial expressions) -
Short video clips under 10 seconds
These limitations make them unsuitable for complex productions like:
-
Multi-character interactions -
Long-duration scenes -
Dynamic camera movements -
Full-body actions
2.2 The WAN-S2V Advantage
The model builds on Alibaba’s WAN text-to-video foundation but adds specialized audio control capabilities. Key innovations include:
-
Hybrid text+audio control system -
Full-parameter training approach -
Long video stabilization techniques -
Specialized data processing pipeline
Data Pipeline: Building the Ultimate Training Set
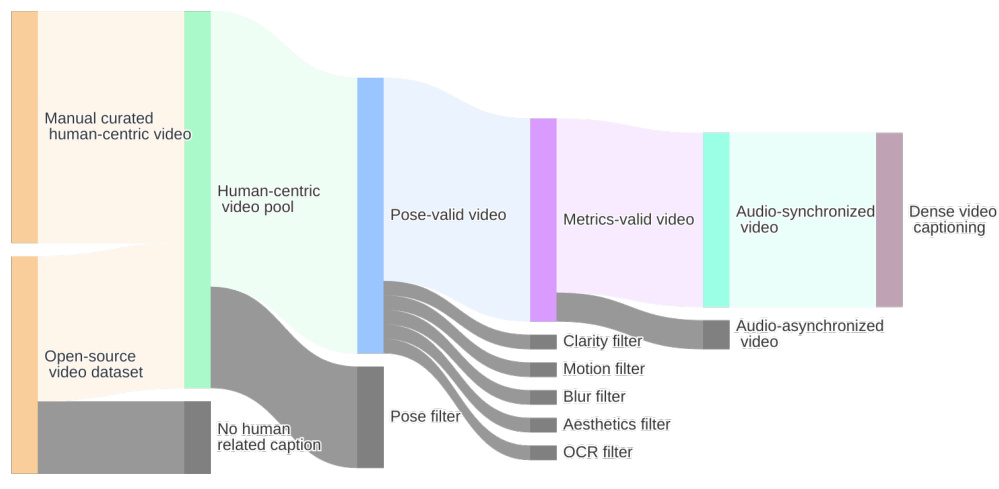
3.1 Data Collection Strategy
The team employed a two-pronged approach:
3.1.1 Automated Screening
-
Source Material: OpenHumanViD and other public datasets -
Initial Filter: Videos with human-related descriptions -
Pose Tracking: -
2D pose estimation using ViTPose -
Conversion to DWPose format -
Spatial/temporal filtering to remove partial/occluded characters
-
3.1.2 Manual Curation
-
Selected videos with intentional human activities: -
Speaking -
Singing -
Dancing -
Complex gestures
-
3.2 Quality Control Metrics
Each video undergoes rigorous evaluation using five key metrics:
| Quality Aspect | Tool/Method | Acceptance Threshold |
|---|---|---|
| Visual Clarity | Dover metric | Perceptual sharpness >0.8 |
| Motion Stability | UniMatch optical flow | Motion score <0.3 |
| Detail Sharpness | Laplacian operator | Face/hand variance <0.1 |
| Aesthetic Quality | Improved aesthetic predictor | Score >7.5/10 |
| Subtitle Interference | OCR detection | Zero text over faces/hands |
3.3 Video Captioning System
QwenVL2.5-72B generates detailed captions covering:
-
Camera angles (wide shot, close-up, etc.) -
Character appearance (clothing, accessories) -
Action breakdown (specific limb movements) -
Environmental features (architecture, lighting)

Model Architecture: The Technical Breakdown
4.1 Core Components
4.1.1 Input Processing
-
Reference Image: Single frame for character identity -
Audio Input: WAV/FLAC format -
Text Prompt: Scene description -
Motion Frames: Optional previous clips
4.1.2 Latent Space Conversion
-
3D VAE encodes target frames into latent space -
FlowMatching adds noise to create training samples -
Multi-modal inputs are patchified and flattened
4.2 Audio Processing Pipeline

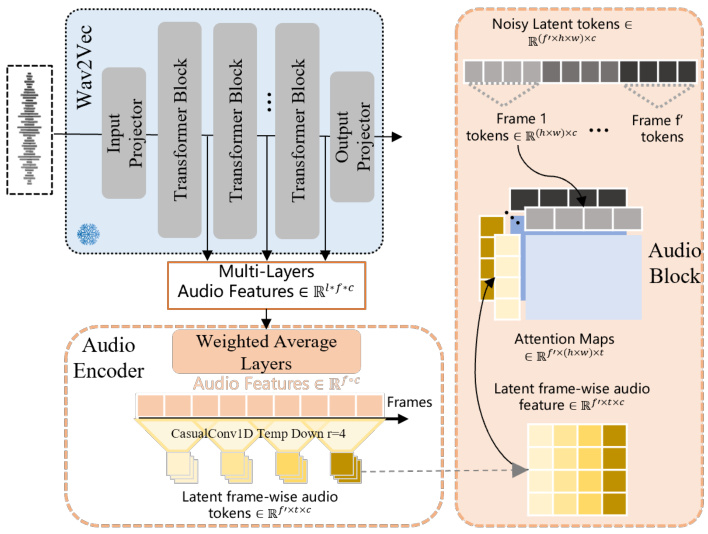
-
Wav2Vec Encoding:
-
Extracts multi-level audio features -
Combines shallow rhythm cues with deep lexical content
-
-
Temporal Compression:
-
Causal 1D convolutions reduce temporal dimension -
Creates frame-aligned audio features (60 tokens/frame)
-
-
Audio-Visual Attention:
-
Segmented attention between audio and visual tokens -
Maintains natural synchronization
-
4.3 Training Innovations
| Training Stage | Data Used | Purpose |
|---|---|---|
| Audio Encoder | Speech/singing videos | Learn audio feature extraction |
| Full Pre-training | Mixed dataset | Harmonize text+audio control |
| Fine-tuning | High-quality影视 data | Refine cinematic details |
Key Training Enhancements:
-
Hybrid parallelism (FSDP + Context Parallel) -
Dynamic resolution training -
3-stage curriculum learning
Technical Implementation Details
5.1 Parallel Training Strategy
| Component | Technology | Configuration |
|---|---|---|
| Model Parallelism | FSDP | 8 GPUs/node, 80GB/GPU |
| Sequence Parallelism | RingAttention + Ulysses | Near-linear scaling |
| Max Resolution | 1024×768 | 48 frames per batch |
5.2 Variable Resolution Handling
1. Calculate token count after patchify
2. Apply dynamic resolution adjustment:
- Exceeding M tokens → Resize/crop
- Under M tokens → Use directly
5.3 Long Video Stabilization
Adopted FramePack module with:
-
Adaptive compression ratios -
Higher compression for distant frames -
Maintains temporal consistency -
Supports 100+ frame sequences
Experimental Results
6.1 Performance Comparison
| Metric | EchoMimicV2 | MimicMotion | EMO2 | FantasyTalking | HY-Avatar | WAN-S2V |
|---|---|---|---|---|---|---|
| FID↓ | 33.42 | 25.38 | 27.28 | 22.60 | 18.07 | 15.66 |
| FVD↓ | 217.71 | 248.95 | 129.41 | 178.12 | 145.77 | 129.57 |
| SSIM↑ | 0.662 | 0.585 | 0.662 | 0.703 | 0.670 | 0.734 |
Key Advantages:
-
30% better identity consistency (CSIM) -
Superior hand detail (HKC: 0.435 vs 0.553) -
More dynamic expressions (EFID: 0.283)
6.2 Use Case Validation
6.2.1 Multi-Character Scene


-
Text controls camera angles -
Audio drives micro-expressions -
Supports synchronized group movements
6.2.2 Long-Form Video

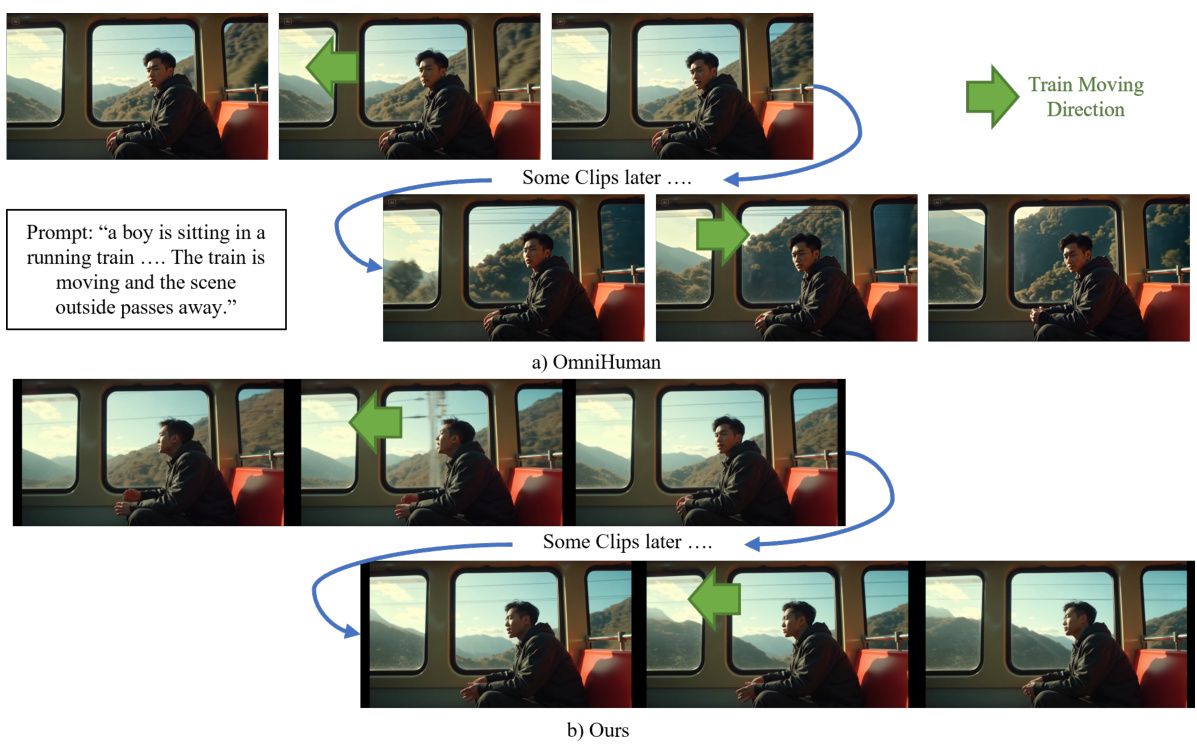
-
Maintains motion continuity across clips -
Preserves object consistency (e.g., paper props) -
Handles complex camera movements
Practical Application Guide
7.1 Hardware Requirements
| Component | Minimum | Recommended |
|---|---|---|
| GPU | 8×A100-80G | 8×H100-80G |
| RAM | 640GB | 1TB |
| Storage | 50TB SSD | 100TB NVMe |
7.2 Standard Workflow
1. Prepare reference image (512x768)
2. Create audio input (clean audio preferred)
3. Write text prompt:
"Medium shot, character in blue suit delivering passionate speech in conference room"
4. Set parameters:
- Duration: 120 frames (4s@30fps)
- Resolution: 1024x768
- Motion intensity: 1.5 (0-2 scale)
Frequently Asked Questions
Q1: How does WAN-S2V differ from Hunyuan-Avatar?
Key Differences:
-
Architecture: Full-parameter vs partial training -
Use Case: Multi-character vs single-character focus -
Training Data: Includes proprietary影视 dataset
Q2: How to fix audio-lip sync issues?
Solutions:
-
Light-ASD alignment detection -
Adversarial training augmentation -
Sliding window generation (4-frame validation)
Q3: How to ensure temporal consistency?
Critical Measures:
-
Motion frame compression -
Cross-clip attention mechanism -
Text-guided object tracking
Future Development Roadmap
As the first release in the Vida series, WAN-S2V will be followed by:
-
Advanced multi-character interaction models -
Precise dance motion control -
Real-time video generation systems
These innovations aim to revolutionize digital content creation, offering filmmakers unprecedented creative flexibility.

