

How Uber Built Finch: The Conversational AI That Transforms Financial Analysis
Core Question
How did Uber turn financial analysis from writing SQL queries into chatting with an AI assistant inside Slack?
At Uber’s global scale, financial decisions depend on how quickly and accurately teams can access data. Every minute waiting for reports can delay choices that affect millions of transactions. Uber’s engineering team discovered that financial analysts spent more time searching for the right data than actually analyzing it.
Their solution was Finch — a conversational AI agent built to live inside Slack, allowing finance teams to ask data questions in plain English and get real-time answers.
Table of Contents
-
The Problem: From Fragmented Data to Instant Insights -
What Is Finch? Core Features and Use Cases -
Architecture: Modular, Secure, and Context-Aware -
How Finch Works: Step-by-Step Query Flow -
Accuracy and Performance at Scale -
Lessons and Reflections from Uber’s Design -
One-Page Summary -
FAQ
The Problem: From Fragmented Data to Instant Insights
Core Question: Why did Uber need a conversational AI for finance?
Before Finch, Uber’s finance analysts faced a time-consuming and fragmented workflow:
-
Logging into multiple platforms like Presto, IBM Planning Analytics, Oracle EPM, and Google Docs; -
Manually searching across systems, often using inconsistent or outdated data; -
Writing complex SQL queries to get specific metrics; -
Submitting tickets to the data science team and waiting hours or even days for reports.
In short: data access was fragmented, technical, and slow.
Uber’s goal:
-
Build a secure, real-time financial data access layer; -
Enable natural language queries directly inside Slack; -
Let the system automatically handle translation, querying, and response.
The result was Finch, a secure, intelligent assistant that removes friction from financial analysis.
What Is Finch? Core Features and Use Cases
Core Question: How does Finch make data retrieval as easy as sending a Slack message?
1. Overview
Finch is a conversational AI data agent integrated directly into Slack. Instead of opening multiple systems or writing SQL, analysts simply ask questions like:
User: What was the GB value in US&C in Q4 2024?
Finch: Gross Bookings for US&C in Q4 2024 were $XXX million.
Behind the scenes, Finch interprets the question, builds the correct SQL query, retrieves data, and returns a clean, readable response — all within seconds.
2. Key Capabilities
| Feature | How It Works | User Benefit |
|---|---|---|
| Natural language queries | Converts English into SQL | No SQL needed |
| Accurate data retrieval | Built on curated data marts | Reduced error and complexity |
| Secure access | Role-Based Access Control (RBAC) | Protects sensitive data |
| Scalable output | Slack messages + Google Sheets export | Easy to work with results |
| Semantic mapping | Interprets synonyms and acronyms (e.g., “US&C”) | Understands real-world language |
| Real-time performance | Parallel agent execution | Fast, responsive answers |
Finch transforms data access from “find the right table” to “just ask.”
Architecture: Modular, Secure, and Context-Aware
Core Question: How is Finch architected to balance flexibility, security, and precision?
Uber built Finch around three foundational layers — data, semantic, and agent orchestration — each optimized for independence and scalability.
1. Data Layer: Simplified and Fast
-
Uses single-table data marts containing curated financial metrics. -
Avoids heavy joins and complex queries for speed and clarity. -
Ensures consistency across departments.
Value: Queries run faster and produce cleaner, more consistent results.
2. Semantic Layer: Connecting Natural Language to Data
-
Built with OpenSearch to store natural-language aliases for columns and values. -
Enables fuzzy matching — understanding variations like “US&C,” “US and Canada,” or “North America.”
Example:
If a user types “US&C revenue Q4,” Finch maps it automatically to the correct field and filter.
This layer improves the precision of WHERE clauses — historically one of the weakest parts of LLM-generated SQL.
3. Agent Layer: Coordinated Intelligence
Finch uses Uber’s internal Generative AI Gateway with LangChain and LangGraph to manage multiple specialized agents.
-
Generative AI Gateway: Connects to multiple LLMs (self-hosted or external). -
LangGraph Framework: Orchestrates agent collaboration. -
Supervisor Agent: Routes tasks to the right sub-agent. -
SQL Writer Agent: Builds and validates the query. -
OpenSearch Index: Supplies semantic metadata. -
Slack SDK & AI Assistant APIs: Manage real-time user interaction. -
Google Sheets Exporter: Handles large result sets.
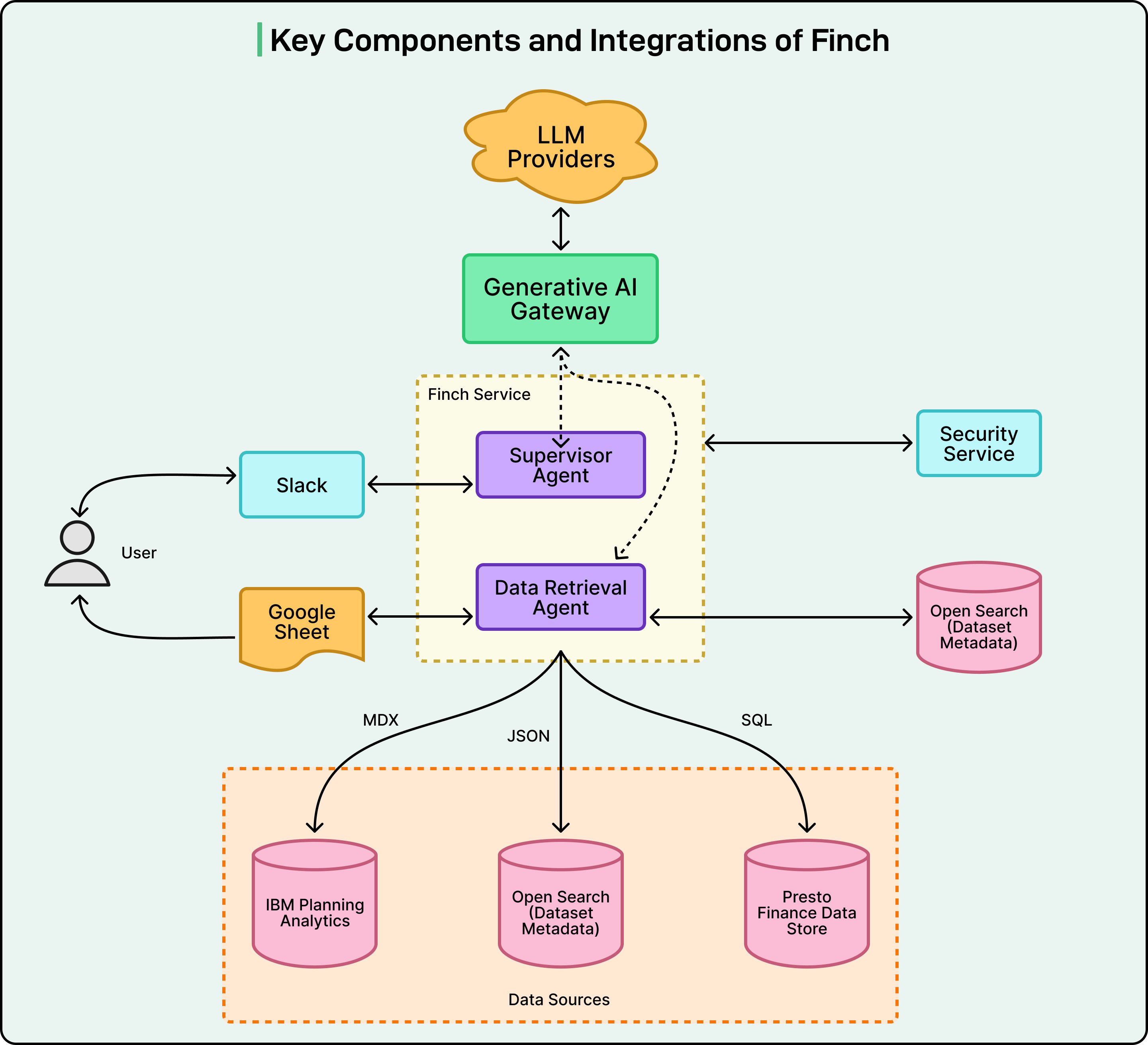
Image source: Uber Engineering Blog

This modular setup allows Uber to evolve Finch — swapping models or expanding functionality — without changing its core structure.
How Finch Works: Step-by-Step Query Flow
Core Question: What happens when you type a question into Slack?
Step 1: Input and Intent Recognition
-
The user sends a message in Slack. -
The Supervisor Agent identifies the request type (data query, document lookup, etc.). -
For data queries, it forwards the task to the SQL Writer Agent.
Step 2: Metadata Mapping and Query Construction
-
The SQL Writer Agent retrieves metadata from OpenSearch. -
It maps human terms to table names and fields. -
Builds a structured SQL query against the relevant data mart.
Example:
User: Compare US&C Q4 2024 with Q4 2023
Finch recognizes both quarters, applies date filters, and generates a comparison query automatically.
Step 3: Execution and Real-Time Feedback
-
Finch executes the SQL query.
-
Sends live progress updates in Slack:
“Identifying data source…” → “Building SQL…” → “Executing query…”
-
Returns structured results in Slack or exports to Google Sheets if the dataset is large.
Step 4: Contextual Conversation
Finch supports multi-turn interaction.
If the user follows up with “Compare to previous quarter,” Finch understands the context and builds upon the last query.
Accuracy and Performance at Scale
Core Question: How does Finch stay accurate and fast as usage grows?
1. Continuous Evaluation
Uber maintains rigorous testing and validation pipelines:
| Evaluation Type | Description | Goal |
|---|---|---|
| Sub-agent testing | Compare outputs against “golden queries” | Maintain logic accuracy |
| Routing validation | Ensure Supervisor Agent assigns correct tasks | Avoid misclassification |
| End-to-end validation | Simulate real-world usage | Detect integration issues |
| Regression testing | Re-run historical queries | Prevent performance drift |
By combining automated tests and real data simulations, Uber ensures Finch’s reliability even after model or schema updates.
2. Performance Optimization
To achieve real-time speed, Finch employs:
-
Parallel agent execution — reduces query latency; -
Optimized SQL structures — minimizes database load; -
Prefetched metrics cache — near-instant responses for common queries.
Together, these make Finch both responsive and scalable — suitable for thousands of daily queries across global teams.
Lessons and Reflections from Uber’s Design
Core Question: What can we learn from Uber’s approach to building Finch?
“True intelligence in AI doesn’t replace analysts — it frees them to think.”
Reflection 1: Human-first Design
Uber didn’t train analysts to learn SQL; it trained systems to understand humans.
Finch reflects a human-centered philosophy: the best tools reduce friction, not add complexity.
Reflection 2: Semantic Structure Matters
LLMs are powerful but not omniscient. Uber’s addition of a semantic layer using OpenSearch gave Finch contextual awareness — an essential bridge between natural language and structured data.
The takeaway: AI becomes enterprise-ready when combined with curated, interpretable data layers.
Reflection 3: Continuous Evaluation Beats One-time Deployment
Uber’s “golden query” testing and regression validation ensured Finch stayed consistent over time.
For large-scale AI systems, quality assurance must be continuous, not reactive.
One-Page Summary
| Module | Key Function | Core Value |
|---|---|---|
| Objective | Real-time, secure, natural-language access to financial data | Faster decisions |
| Interface | Fully integrated into Slack | Seamless workflow |
| Core Tech | LangGraph + OpenSearch + RBAC | Modular, secure, scalable |
| Workflow | Supervisor → SQL Writer → Execution → Response | Transparent process |
| Performance | Parallel agents + caching | Real-time response |
| Accuracy | Multi-layer evaluation | High trust |
| Impact | Empowers analysts to focus on insight, not querying | Productivity boost |
FAQ
Q1: What kinds of questions can Finch answer?
Finch handles financial queries, comparisons, and performance lookups in natural language.
Q2: Does Finch access multiple databases?
No. It uses simplified data marts optimized for clarity and performance.
Q3: How does Finch ensure data security?
Role-based access control (RBAC) restricts sensitive information to authorized users only.
Q4: Is Finch tied to a single large language model?
No. Uber’s Generative AI Gateway supports multiple interchangeable models.
Q5: Can I export Finch results?
Yes. Large datasets are automatically exported to Google Sheets for analysis.
Q6: How does Finch learn new business terms?
OpenSearch mappings are updated continuously to include new aliases and data fields.
Q7: What’s next for Finch?
Uber plans deeper FinTech integrations, predictive analytics, and automated reporting capabilities.
Q8: What’s Finch’s greatest contribution?
It humanizes data access — turning financial analysis into a conversation rather than a chore.

